
Введение
Еженедельное обновление HyperAI на этой неделе посвящено сильной подборке моделей для аудио, видео, понимания изображений, OCR и распознавания речи. Главный проект выпуска — Irodori-TTS-500M-v3, открытая японская модель преобразования текста в речь, объединяющая высококачественную генерацию речи с частотой 48 кГц, zero-shot-клонирование голоса и тонкое управление стилем с помощью эмодзи-аннотаций.
В обновление также вошли инструменты для разделения аудио по промптам, видеоматтинга, 4D-симуляции мира, генерации аудио по видео, OCR документов, сегментации на устройстве, выразительного редактирования аудио и потокового ASR с низкой задержкой. Ниже представлена очищенная, готовая к публикации версия исходного еженедельного обзора, в которой полезные скриншоты сохранены в исходном контексте.
Примечание об источнике
Эта статья основана на еженедельном обновлении BAAI Hub / HyperAI, опубликованном на На исходной странице указано, что материал взят из WeChat, а изображения могут быть удалены при наличии вопросов, связанных с авторскими правами.
QR-коды, рекламные постеры, изображения с приглашениями в группы и нерелевантные рекомендательные баннеры были намеренно удалены. Ссылки на изображения DiaMoE-TTS и DreamOmni2 сохранены в исходных местах, но во время проверки запросы предпросмотра завершились по тайм-ауту, поэтому они отмечены здесь, а не рассматриваются как полностью проверенные скриншоты.
Обзор еженедельного обновления HyperAI
С 27 июня по 3 июля HyperAI обновила несколько публичных ресурсов на своем официальном сайте:
- 12 отобранных публичных руководств
- 5 популярных статей AI-энциклопедии
- 4 дедлайна AI-конференций в июле
Главная тема этой недели — практические эксперименты. Большинство материалов представляют собой не просто описания статей: они предоставляют онлайн-демо или исполняемые ноутбуки, чтобы пользователи могли быстро протестировать поведение моделей.
Отобранные публичные руководства
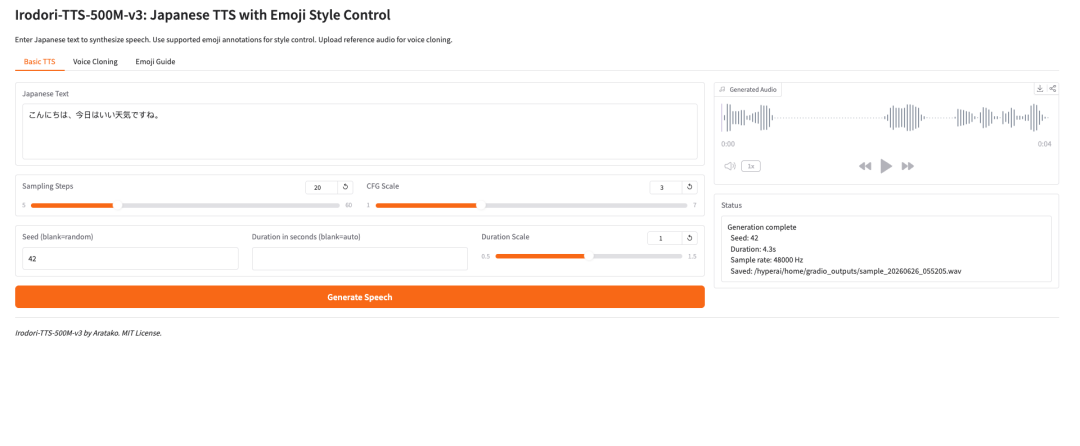
- Irodori-TTS-500M-v3: японский TTS с управлением стилем через эмодзи
Irodori-TTS — это открытый проект преобразования японского текста в речь, выпущенный разработчиком Aratako в 2026 году. Представленная модель, Irodori-TTS-500M-v3, предназначена для синтеза японской речи, zero-shot-клонирования голоса и управления голосовым стилем с помощью эмодзи.
Модель построена на архитектуре Rectified Flow Diffusion Transformer (RF-DiT) и генерирует речь в непрерывном латентном пространстве DACVAE. В практическом применении наиболее интересный момент заключается в том, что она может клонировать целевой голос всего по короткому референсному фрагменту, обычно длительностью около 3–10 секунд, без дополнительного дообучения.
Она также поддерживает управление стилем через эмодзи-аннотации. Это делает модель более гибкой, чем базовая TTS-система: пользователи могут более легким способом задавать тон, эмоции, темп и тонкие невербальные проявления.
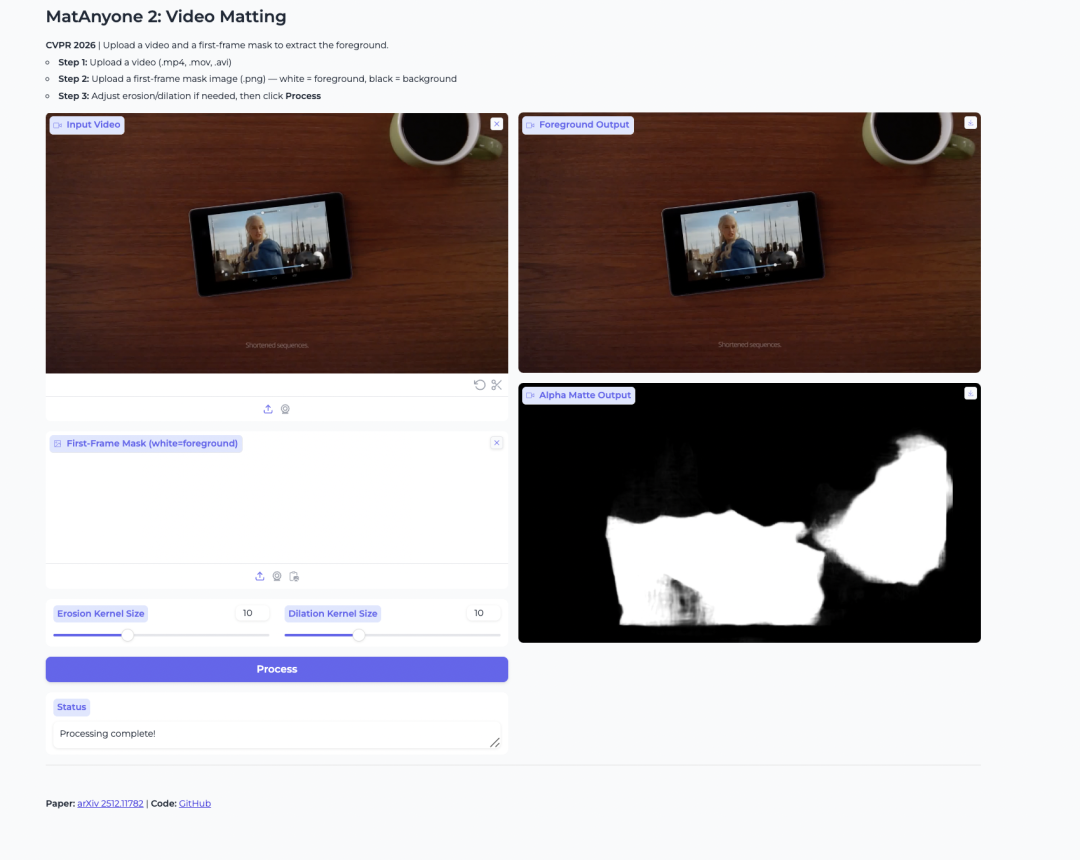
- MatAnyone 2: видеоматтинг для извлечения переднего плана
MatAnyone 2 — модель видеоматтинга, выпущенная NTU S-Lab и SenseTime. Она предназначена для извлечения переднего плана с человеком и генерации альфа-масок из видео.
Модель повышает стабильность за счет обученного оценщика качества. Это помогает уменьшить артефакты на границах и сохранить такие детали, как волосы, полупрозрачные края и контуры переднего плана. Она также полезна, когда пользователю нужно изолировать конкретного человека в видео с несколькими людьми.
Онлайн-демо:
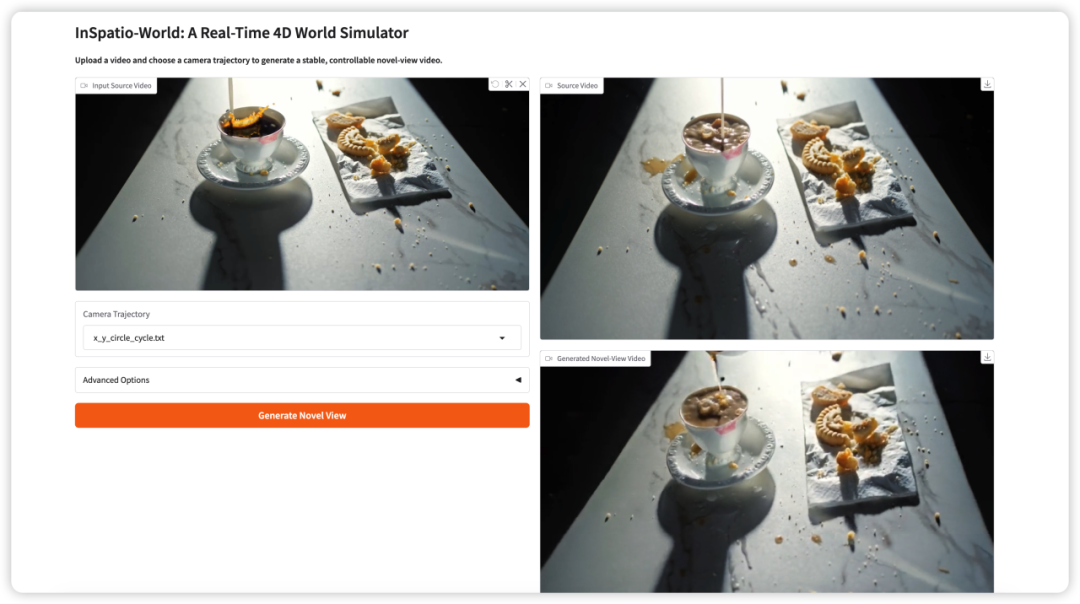
- InSpatio-World: 4D-симуляция мира в реальном времени
InSpatio-World — это 4D-симулятор мира в реальном времени, выпущенный командой InSpatio в 2026 году. Он может принимать входное видео и заданную траекторию камеры, а затем генерировать стабильное видео с новым ракурсом.
Основная идея — сделать видеосцены более управляемыми. Вместо пассивного просмотра фиксированного ракурса пользователи могут задавать движение камеры и исследовать сцену с новых точек обзора, сохраняя временную согласованность.
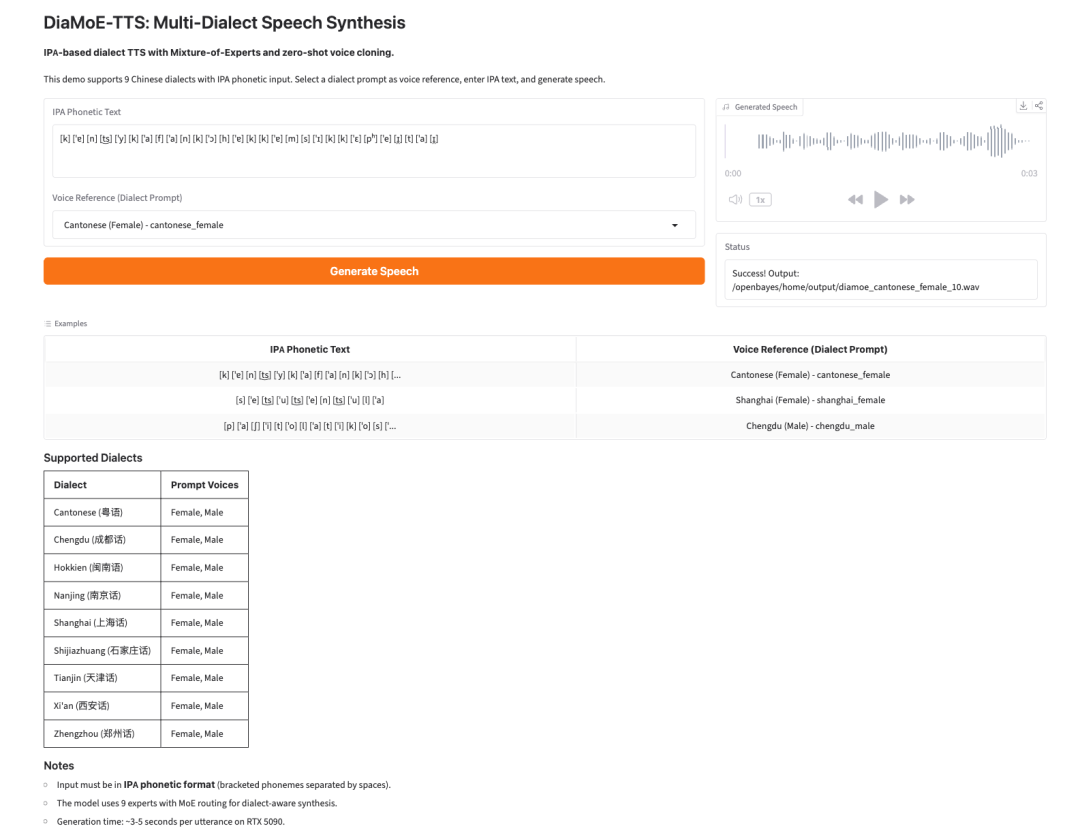
- DiaMoE-TTS: многодиалектный синтез речи на основе IPA
DiaMoE-TTS — это фреймворк многодиалектного синтеза речи от Giant AI Lab. Он использует Международный фонетический алфавит, или IPA, как единый фронтенд для генерации диалектной речи.
Модель сочетает архитектуру Mixture-of-Experts с методами параметрически эффективной адаптации, такими как LoRA и conditioning adapters. Это позволяет системе быстрее адаптироваться к новым диалектам, даже когда доступно лишь ограниченное количество данных.
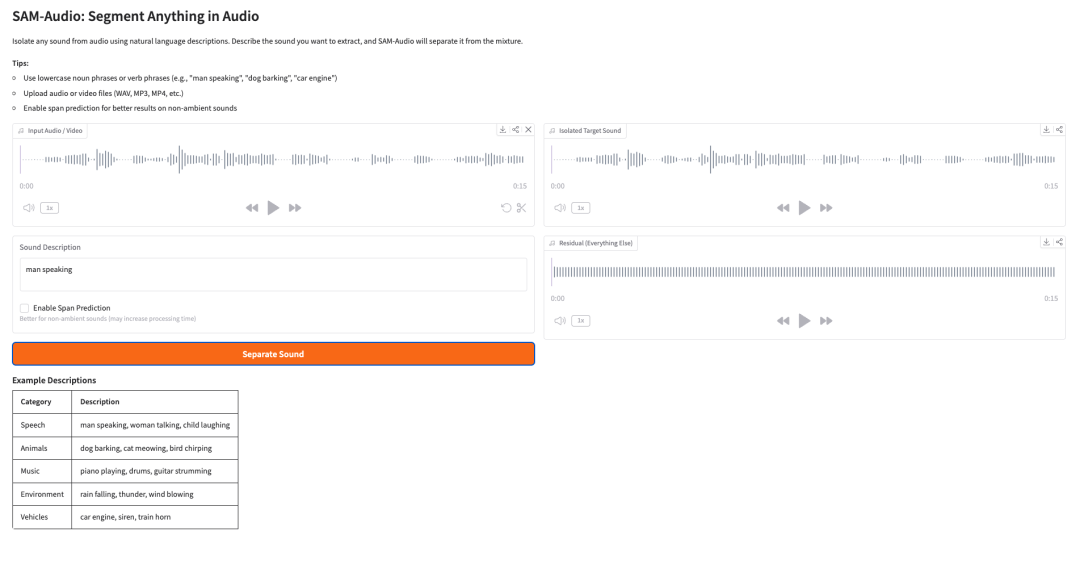
- SAM-Audio: Segment Anything in Audio
SAM-Audio — это базовая модель Meta для разделения аудиоисточников. Она может выделять целевой звук из смешанного аудиосигнала с помощью описаний на естественном языке, визуальных подсказок из видео или выбранного временного интервала.
Например, пользователь может описать звук, который хочет отделить: «говорящий мужчина», «лай собаки», «двигатель автомобиля» или «игра на пианино». Затем модель пытается отделить целевой звук от всех остальных звуков в смеси.
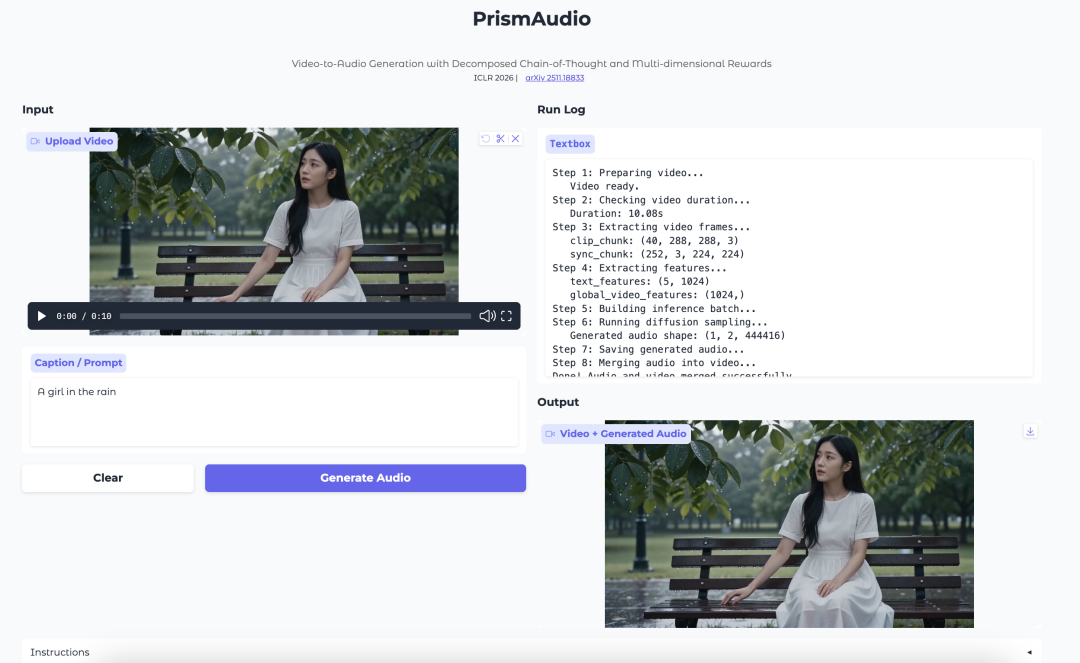
- PrismAudio: генерация аудио из видео с декомпозированной цепочкой рассуждений и многомерными наградами
PrismAudio — это модель генерации аудио из видео от Tongyi Lab. Она ориентирована на создание звука, который соответствует визуальной сцене, таймингу, атмосфере и пространственному ощущению видео.
Модель вводит декомпозированный процесс планирования Chain-of-Thought. Вместо того чтобы рассматривать генерацию аудио из видео как один единый шаг рассуждения, она разделяет процесс на семантическое, временное, эстетическое и пространственное измерения. Каждому измерению соответствует целевой сигнал награды для обучения с подкреплением.
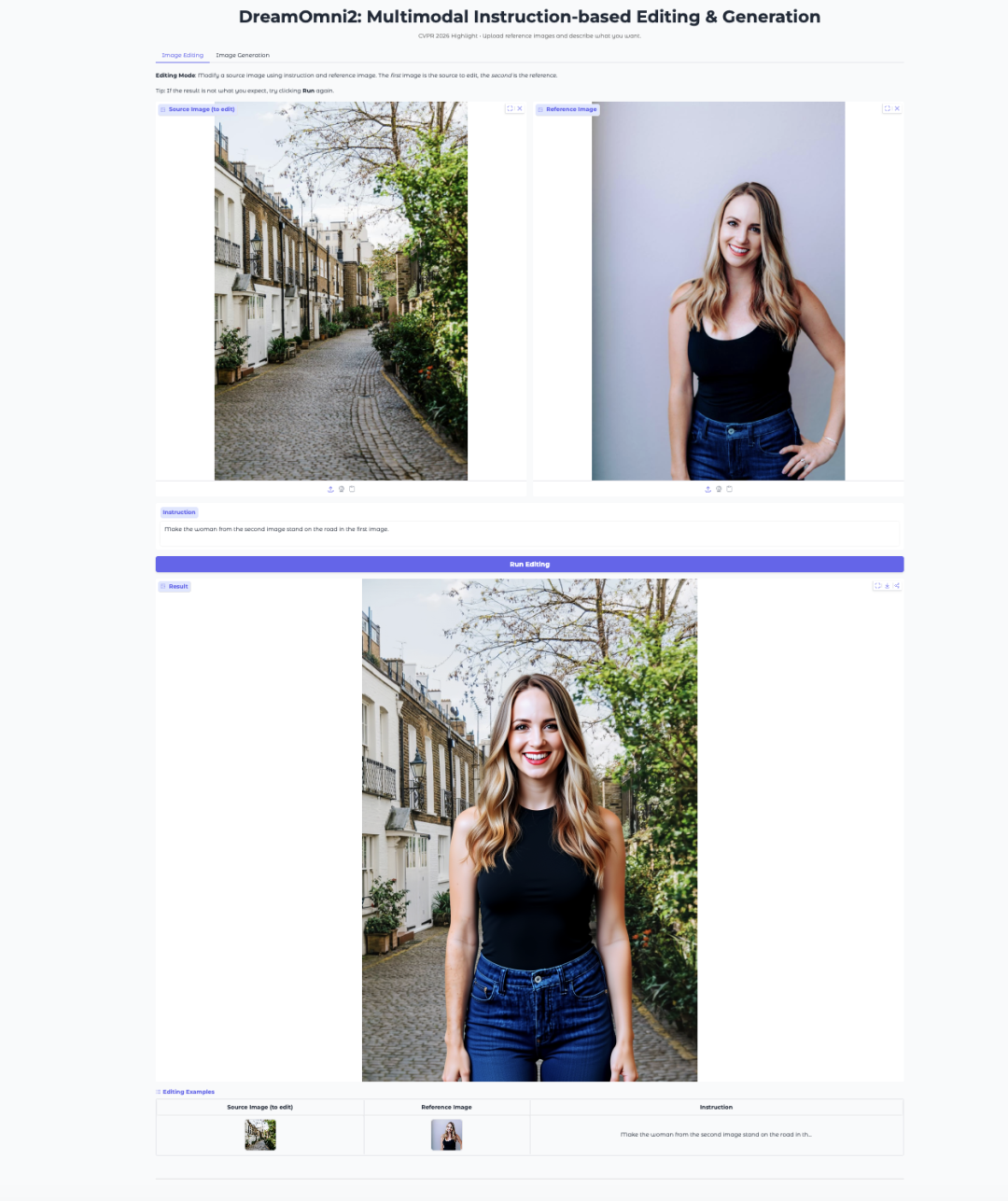
- DreamOmni2: мультимодальное редактирование и генерация изображений на основе инструкций
DreamOmni2 — это мультимодальная модель редактирования и генерации изображений от CUHK JIA Lab. Она была принята на CVPR 2026 в качестве Highlight paper.
Модель построена на базе FLUX.1-Kontext-dev и использует дообученную визуально-языковую модель Qwen2.5-VL-7B для обработки инструкций. Она поддерживает текстовые подсказки на естественном языке вместе с референсными изображениями, что делает ее подходящей для таких задач, как замена объектов, перенос стиля, имитация позы и генерация на основе концептов.
- PixelRefer: детальное понимание объектов в изображениях и видео
PixelRefer — это унифицированный фреймворк для понимания объектов в изображениях и видео от Alibaba DAMO Academy. Он сосредоточен на детальном объектно-ориентированном понимании, а не только на описании всей сцены целиком.
Фреймворк поддерживает указание на уровне регионов, создание описаний и ответы на вопросы. Он также вводит масштабно-адаптивный объектный токенизатор и более легкую версию PixelRefer-Lite, чтобы сделать представление объектов более компактным и эффективным.

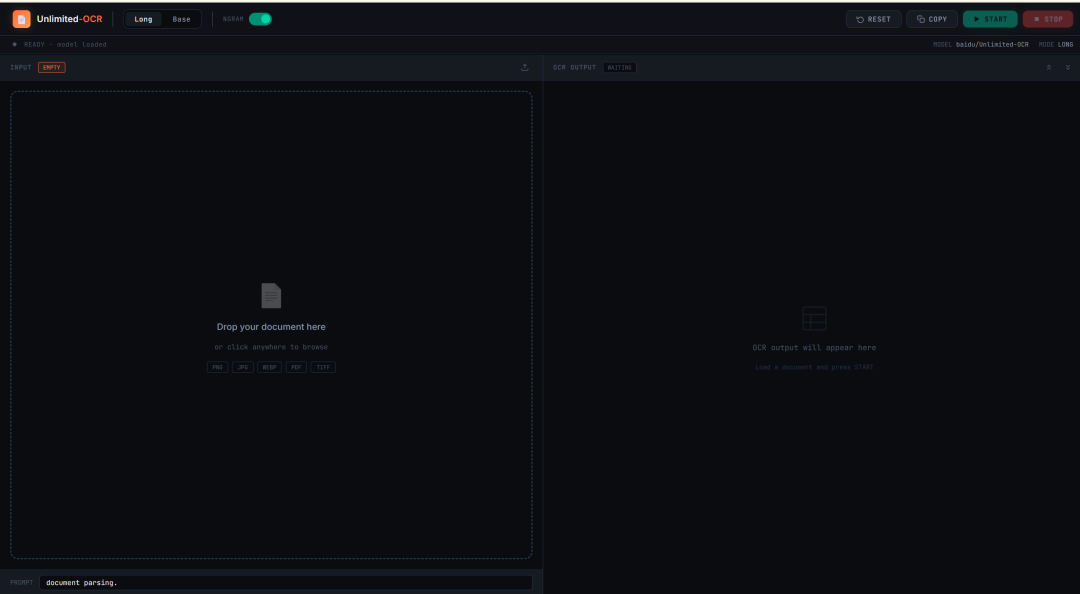
- Unlimited-OCR: OCR длинных документов за один проход и разбор макета
Unlimited-OCR — это проект OCR и разбора макета документов, выпущенный Baidu в 2026 году. Он предназначен для анализа длинных документов, а не только для распознавания отдельных страниц.
Проект может обрабатывать отдельные изображения документов, многостраничные изображения и страницы, преобразованные из PDF. Он особенно полезен для научных статей, отчетов, отсканированных документов, длинных таблиц и многостраничных структурированных материалов.
- EdgeTAM: сегментация изображений и видео с подсказками для периферийных устройств
EdgeTAM — это локальная модель Track Anything Model, разработанная Meta Reality Labs и NTU S-Lab. Она предназначена для устройств с ограниченными ресурсами, сохраняя при этом интерактивные возможности сегментации моделей в стиле SAM.
Модель уменьшает узкое место, связанное с attention-памятью в SAM 2, с помощью 2D Spatial Perceiver и конвейера дистилляции. На практике это означает, что она может поддерживать сегментацию с подсказками
сегментацию и отслеживание видеообъектов более эффективно на периферийном оборудовании.

- Step-Audio-EditX: клонирование голоса без обучения на примерах и выразительное редактирование аудио
Step-Audio-EditX — это модель для редактирования аудио от StepFun. Она объединяет аудиомодель на базе LLM с 3 млрд параметров и обучение с подкреплением, поддерживая клонирование голоса в режиме zero-shot и выразительное редактирование аудио.
Модель работает с мандаринским китайским, английским, сычуаньским диалектом, кантонским, японским и корейским языками. Она предназначена для таких задач, как управление эмоциями, редактирование манеры речи, редактирование паралингвистических характеристик и итеративное улучшение аудио.

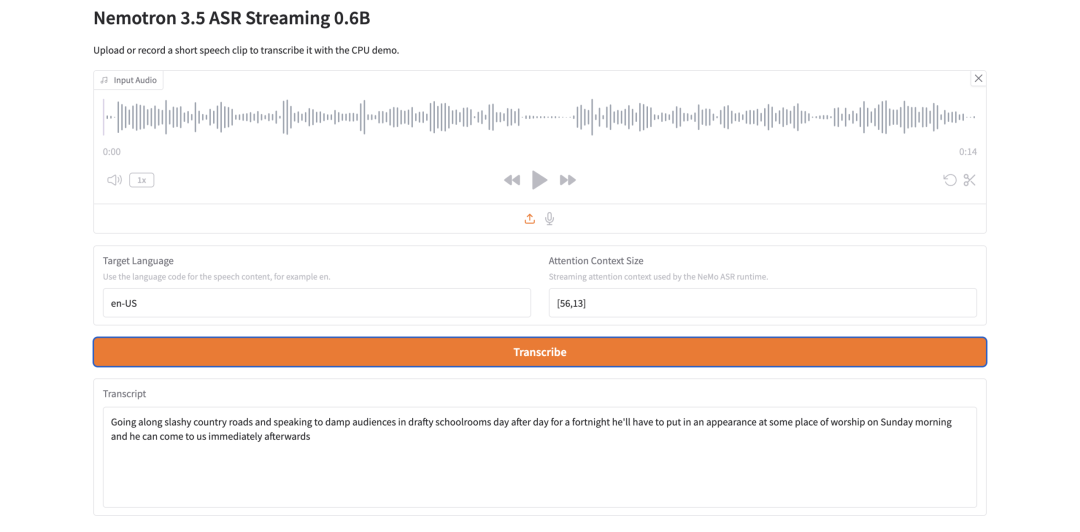
- Nemotron 3.5 ASR Streaming 0.6B: лёгкое потоковое распознавание речи
Nemotron 3.5 ASR Streaming 0.6B — это модель автоматического распознавания речи от NVIDIA. Она создана для потоковой транскрибации с низкой задержкой и использует архитектуру FastConformer-RNNT с учётом кэширования.
Ключевая идея конструкции — повторное использование контекста. Во время потокового инференса модель повторно использует контекст энкодера вместо повторного вычисления перекрывающихся аудиофрагментов, что помогает снизить избыточные вычисления и улучшить производительность в реальном времени.
Популярные статьи энциклопедии
На этой неделе HyperAI также выделила пять популярных статей AI-энциклопедии:
- Большая языковая модель (LLM)
- Модель действий мира (WAM)
- Среднее гармоническое
- Виртуальный скрининг
- Обучение с подкреплением на основе обратной связи от ИИ (RLAIF)
Вики HyperAI собирает сотни понятий и объяснений, связанных с ИИ. Она полезна читателям, которым нужен быстрый способ разобраться в терминах, часто встречающихся в научных статьях, руководствах и документации моделей.
Дедлайны AI-конференций в июле
В оригинальном обновлении также перечислены дедлайны нескольких конференций по ИИ и компьютерным наукам в июле. Все сроки указаны по времени AoE.
| Дата | Время | Конференция |
|---|---|---|
| 09 июля | 23:59:59 | POPL 2027 |
| 10 июля | 23:59:59 | ICSE 2027 |
| 17 июля | 23:59:59 | SIGMOD 2027 |
| 28 июля | 23:59:59 | AAAI 2027 |
О HyperAI
HyperAI — это сообщество в области искусственного интеллекта и высокопроизводительных вычислений. Его сайт предоставляет открытые ресурсы для разработчиков, исследователей и изучающих ИИ.
Согласно исходному источнику, HyperAI уже собрала или поддерживает:
- 2 100+ открытых наборов данных с внутренними узлами ускоренного доступа
- 700+ классических и популярных онлайн-руководств
- 300+ кейс-стади по статьям AI4Science
- 700+ энциклопедических статей, связанных с ИИ
- Полное китайское зеркало документации Apache TVM
FAQ
Что такое Irodori-TTS-500M-v3?
Irodori-TTS-500M-v3 — это открытая японская модель преобразования текста в речь на основе архитектуры RF-DiT. Она поддерживает генерацию японской речи, zero-shot-клонирование голоса по короткому референсу и управление стилем с помощью эмодзи.
Может ли Irodori-TTS клонировать голос без дообучения?
Да. В оригинальном обновлении указано, что Irodori-TTS поддерживает zero-shot-клонирование голоса по короткому референсному аудиофрагменту, обычно длительностью около 3–10 секунд. При этом результат всё равно зависит от качества и чёткости референсного аудио.
Для чего используется SAM-Audio?
SAM-Audio используется для разделения аудиоисточников на основе промптов. Пользователи могут описать звук, который хотят извлечь, предоставить визуальные подсказки или указать временной диапазон, чтобы изолировать целевой звук из смешанной записи.
В чём разница между видеоматтингом и видеосегментацией?
Видеосегментация обычно разделяет объекты на области или маски, тогда как видеоматтинг оценивает более детализированную альфа-маску. Маттинг особенно важен для чистого извлечения переднего плана, детализации волос, полупрозрачных краёв и композитинга.
Что генерирует PrismAudio?
PrismAudio генерирует аудио для видео. Она стремится согласовать сгенерированный звук с семантическим содержанием видео, таймингом, эстетическим ощущением и пространственными подсказками.
Почему Unlimited-OCR полезна для длинных документов?
Unlimited-OCR разработана для долгосрочного парсинга, а не только для изолированного OCR отдельных страниц. Она может быть полезна при работе со статьями, отчётами, сканированными файлами, длинными таблицами или изображениями, полученными из многостраничных PDF.
Подходит ли Nemotron 3.5 ASR Streaming 0.6B для транскрибации речи в реальном времени?
Да, она разработана для потоковой транскрибации с низкой задержкой.
потокового ASR. Его архитектура FastConformer-RNNT с учетом кэша повторно использует контекст во время потокового вывода, что помогает снизить избыточные вычисления.
Связанные инструменты
- Irodori-TTS: open-source японский TTS с клонированием голоса по референсному аудио и управлением стилем.
- Irodori-TTS-500M-v3 on Hugging Face: страница модели для контрольной точки японского TTS 500M v3.
- SAM-Audio: репозиторий Meta для инференса и примеров Segment Anything in Audio.
- MatAnyone 2: страница проекта фреймворка видеоматтинга MatAnyone 2.
- InSpatio-World: страница проекта для интерактивной 4D-симуляции мира в реальном времени.
- DiaMoE-TTS: GitHub-репозиторий для синтеза речи на основе IPA с поддержкой нескольких диалектов.
- PrismAudio: страница проекта по генерации аудио из видео с декомпозированным CoT и многомерными наградами.
- DreamOmni2: open-source проект для мультимодального редактирования и генерации изображений на основе инструкций.
- PixelRefer: фреймворк Alibaba DAMO Academy для детального понимания объектов на изображениях и видео.
- Unlimited-OCR: проект Baidu для OCR на длинном горизонте и парсинга документов.
- EdgeTAM: модель Meta для отслеживания любых объектов на устройстве с поддержкой подсказок для сегментации изображений и видео.
- Step-Audio-EditX: модель StepFun для zero-shot клонирования голоса и выразительного редактирования аудио.
- Nemotron 3.5 ASR Streaming 0.6B: страница модели NVIDIA на Hugging Face для потокового ASR с низкой задержкой.
Связанные ссылки
- Original BAAI Hub Article: исходная статья для этого еженедельного обновления HyperAI.
- HyperAI Official Website: основной портал с руководствами, статьями, датасетами и AI-ресурсами HyperAI.
- HyperAI Wiki: портал AI-энциклопедии, охватывающий распространенные понятия и исследовательские термины.
- HyperAI Conference Tracker: трекер дедлайнов конференций по AI и компьютерным наукам.
- Meta SAM-Audio Research Page: официальная исследовательская страница Segment Anything Model Audio.
- SAM-Audio Paper on arXiv: исследовательская статья, описывающая фундаментальную модель SAM-Audio.
- MatAnyone 2 Paper on arXiv: статья о MatAnyone 2 и ее обученном оценщике качества маттинга.
- Unlimited-OCR Paper on arXiv: технический отчет об Unlimited OCR и парсинге на длинном горизонте.
Резюме
Это еженедельное обновление объединяет полезную подборку новых AI-демо и ресурсов моделей, особенно в областях генерации аудио, распознавания речи, обработки видео, понимания изображений и OCR для длинных документов.
Самые практичные позиции — Irodori-TTS для генерации японской речи, SAM-Audio для разделения звуков на основе подсказок, MatAnyone 2 для качественного видеоматтинга, Unlimited-OCR для длинных документов и Nemotron 3.5 ASR для потокового распознавания речи.
В целом эта подборка полезна для читателей, которые хотят быстро понять, какие новые AI-модели стоит протестировать, что делает каждая из них и где их можно попробовать.


