
Die kurze Antwort: nein, aber die Richtung ist wichtig
DiffusionGemma ist keine Erklärung Googles, dass die Next-Token-Vorhersage tot sei. Besser versteht man es als ein ernst zu nehmendes experimentelles Signal: Google testet einen anderen Weg für die KI-Textgenerierung, bei dem Geschwindigkeit, Parallelität und interaktive lokale Workflows wichtiger sind als der vertraute Ein-Token-nach-dem-anderen-Rhythmus standardmäßiger LLMs.
Google beschreibt DiffusionGemma als ein experimentelles offenes Modell, das auf Textdiffusion basiert. Statt Text strikt von links nach rechts zu erzeugen, generiert es Textblöcke, indem es eine Leinwand aus verrauschten oder Platzhalter-Tokens verfeinert. Das praktische Versprechen ist einfach: Wenn ein Modell an vielen Positionen gleichzeitig arbeiten kann, kann es GPU-Rechenleistung effizienter nutzen und die Inferenzlatenz für bestimmte Anwendungsfälle reduzieren.
Das bedeutet jedoch nicht, dass autoregressive Sprachmodelle morgen ersetzt werden. Googles eigener Einführungsbeitrag formuliert die Abwägung vorsichtig. Er sagt, dass standardmäßige Gemma 4-Modelle weiterhin die Empfehlung für Anwendungen sind, die maximale Produktionsqualität erfordern. Dieser eine Satz ist wichtig. DiffusionGemma ist ein auf Geschwindigkeit ausgerichtetes Forschungs- und Entwicklermodell, kein universeller Ersatz für das dominante LLM-Paradigma.
Warum die Next-Token-Vorhersage zum Standard wurde
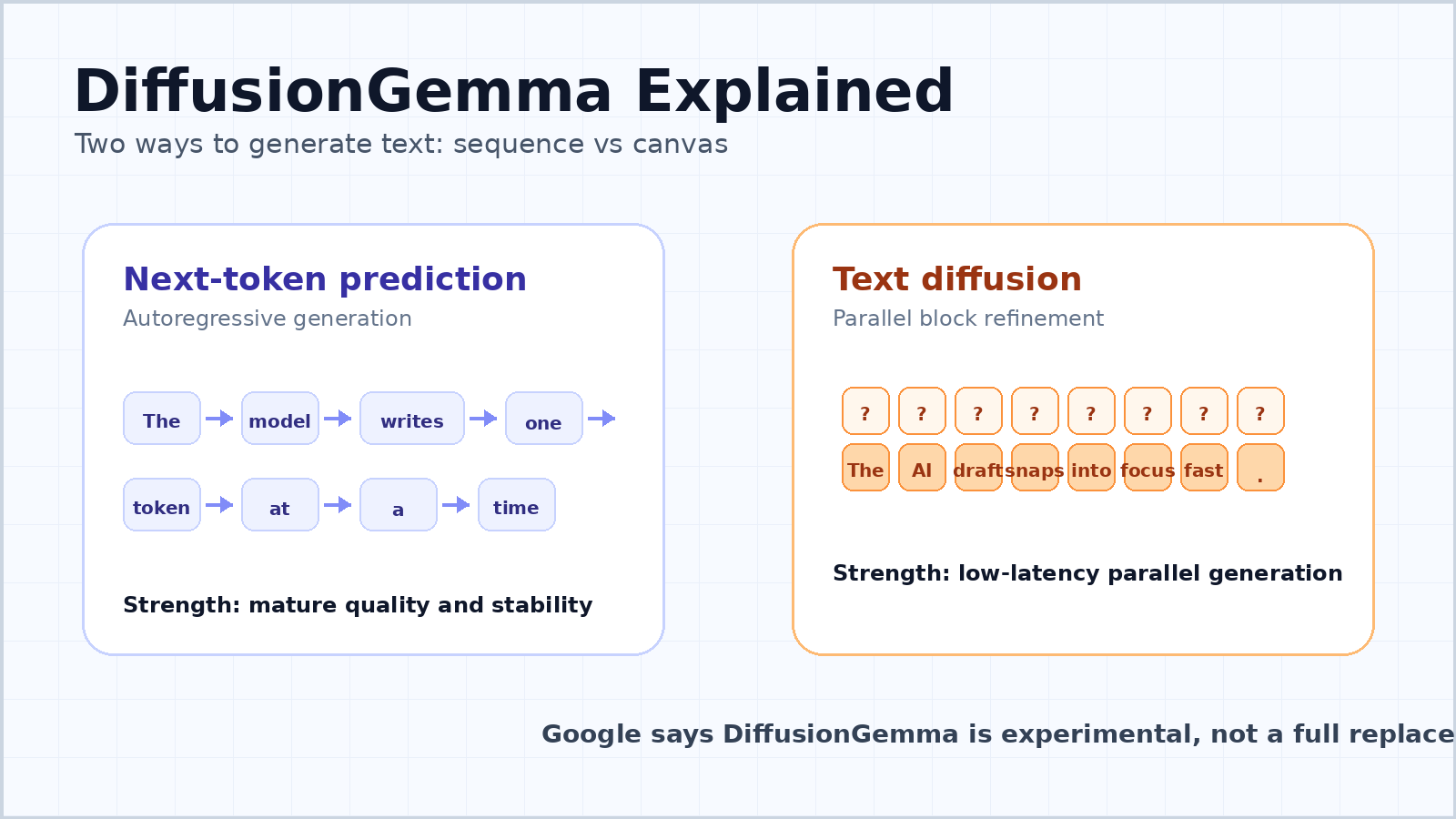
Die meisten modernen Chatbots und großen Sprachmodelle sind autoregressiv. Sie lesen den Prompt, sagen dann das nächste Token voraus, danach das darauffolgende Token, und fahren fort, bis die Antwort vollständig ist. Das ist das einfache mentale Modell hinter der Next-Token-Vorhersage.
Dass sie dominant wurde, ist kein Zufall. Autoregressive Modelle sind flexibel, stabil und gut skalierbar. Sie können Text variabler Länge erzeugen, Kohärenz von links nach rechts bewahren und funktionieren gut bei Chat, Programmierung, Übersetzung, Zusammenfassung, Schlussfolgerungen und Tool-Nutzung. Der Ansatz passt außerdem natürlich dazu, wie geschriebene Sprache entsteht.
Die Schwäche ist die Latenz. Ein Token-für-Token-Modell hat eine sequenzielle Abhängigkeit: Token 100 hängt von den Tokens 1 bis 99 ab, und Token 101 hängt von Token 100 ab. Selbst wenn die GPU leistungsstark ist, muss das Modell die Sequenz Schritt für Schritt durchlaufen. Wenn ein einzelner Nutzer eine einzelne Frage stellt, kann ein großer Teil der Hardware ungenutzt bleiben, weil das Modell auf Speicherbewegungen und sequenzielles Decoding wartet.
Was DiffusionGemma anders macht
DiffusionGemma lässt sich von Diffusionsmodellen inspirieren, jener Familie generativer Modelle, die durch Bild- und Videogenerierung bekannt geworden ist. Statt die Antwort Token für Token zu schreiben, beginnt ein Diffusionsmodell mit Rauschen oder Unsicherheit und verfeinert diese schrittweise zu einer kohärenten Ausgabe.
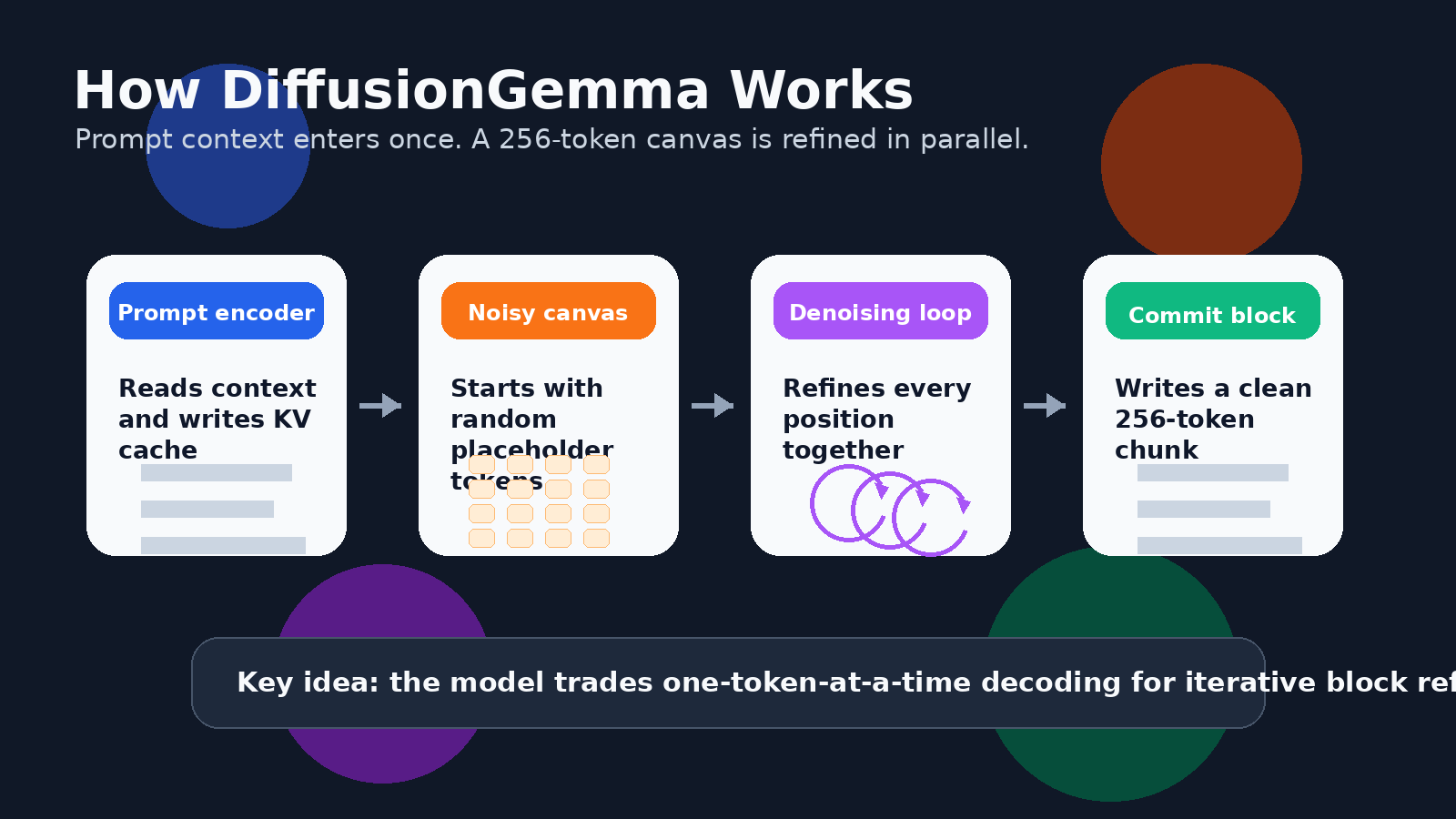
Für Text bedeutet das, dass das Modell parallel an einem Block von Tokens arbeiten kann. Googles Entwicklerleitfaden beschreibt eine 256-Token-Leinwand. Das Modell beginnt mit einer Leinwand aus zufälligen Platzhalter-Tokens und entrauscht dann wiederholt den gesamten Block. Sichere Token-Positionen werden zu Ankern, unsichere Positionen werden erneut verfeinert, und der Block nimmt nach und nach klare Gestalt an.
Das ist nicht dasselbe, wie einen gesamten langen Aufsatz in einem einzigen Durchlauf zu generieren. DiffusionGemma verwendet für längere Ausgaben einen block-autoregressiven Ansatz. Sobald ein 256-Token-Block vollständig verfeinert ist, wird er in den KV-Cache übernommen, und das Modell geht zum nächsten Block über. Es hat also weiterhin eine Links-nach-rechts-Struktur über Blöcke hinweg, kann innerhalb jedes Blocks jedoch viele Tokens gemeinsam verfeinern.
Warum es schneller sein kann
Bei der Geschwindigkeit geht es um den Hardware-Engpass. Traditionelle autoregressive Modelle können durch die Speicherbandbreite begrenzt sein, weil das Modell beim Generieren eines Tokens nach dem anderen wiederholt Gewichte lädt. DiffusionGemma versucht, mehr Arbeit in Richtung Rechenleistung zu verlagern, indem es der GPU innerhalb jedes Blocks eine größere parallele Arbeitslast gibt.
Google sagt, dass DiffusionGemma auf dedizierten GPUs eine bis zu viermal schnellere Token-Generierung liefern kann, mit Beispielen wie mehr als 1000 Tokens pro Sekunde auf einer einzelnen NVIDIA H100 und mehr als 700 Tokens pro Sekunde auf einer RTX 5090. Diese Zahlen sind kein pauschales Versprechen für jede Aufgabe, jedes Gerät oder jede Batch-Größe. Sie sind ein Hinweis auf ein bestimmtes hardwarefreundliches Generierungsmuster.
Deshalb ist DiffusionGemma besonders interessant für lokale und interaktive Workflows. Wenn ein Nutzer schnelle Bearbeitungen, Code-Ergänzungen, strukturierte Entwürfe oder rasche Iterationen anfordert, kann die GPU über freie Rechenkapazität verfügen, die ein autoregressives Modell nicht vollständig nutzen kann. Ein Diffusions-Sprachmodell kann für diese Art von Low-Batch- und geschwindigkeitssensibler Arbeitslast besser geeignet sein.
Die Rolle bidirektionaler Aufmerksamkeit und Selbstkorrektur
Einer der wichtigsten Unterschiede ist die bidirektionale Aufmerksamkeit. Während des Entrauschens können Tokens auf der Arbeitsfläche andere Positionen im Block berücksichtigen, nicht nur frühere Tokens. Das verändert das Gefühl der Generierung. Das Modell kann Kontext von beiden Seiten einer fehlenden oder unsicheren Passage nutzen.
Das ist besonders nützlich für nichtlineare Textprobleme. Google nennt Inline-Bearbeitung, Code-Ergänzung, mathematische Graphen und sogar Sudoku-artige beschränkte Generierung als Beispiele, bei denen zukünftige Positionen wichtig sind. Ein standardmäßiges autoregressives Modell kann bei vielen Aufgaben stark sein, doch sobald es ein frühes Token ausgibt, ist es in der Regel daran gebunden. Diffusionsartiges Entrauschen schafft Raum für Überarbeitung, bevor der Block finalisiert wird.
Das ist auch der Grund, warum der Begriff Selbstkorrektur im Zusammenhang mit DiffusionGemma immer wieder auftaucht. Das Modell tippt nicht einfach nur. Es bewertet wiederholt die gesamte Arbeitsfläche, behält sichere Positionen bei, ersetzt unsichere und verfeinert den Block, bis er konvergiert.
Was das 26B-MoE-Design bedeutet
DiffusionGemma basiert auf einem 26B-Mixture-of-Experts-Design aus der Gemma 4-Familie, wobei während der Inferenz nur eine kleinere aktive Teilmenge verwendet wird. Googles KI-Dokumentation beschreibt es als 26B-Modell mit ungefähr 4B aktiven Parametern, während der Entwicklerleitfaden erklärt, dass das Modell bei Quantisierung innerhalb von 18 GB VRAM-Grenzen passen soll.
Die zentrale Idee ist Effizienz. Ein spärliches MoE-Modell kann eine große Gesamtzahl an Parametern haben und dabei für ein bestimmtes Token oder eine bestimmte Aufgabe nur ausgewählte Experten aktivieren. Das kann die Leistungsfähigkeit verbessern, ohne dass bei jedem Schritt das gesamte Modell aktiv sein muss.
Für Entwickler ist das wichtig, weil DiffusionGemma nicht nur eine Labordemo ist. Es wird als Open-Weights-Modell unter einer Apache 2.0-Lizenz veröffentlicht, mit Dokumentation für vLLM, Hugging Face, Google Cloud Model Garden und andere Bereitstellungswege. Google lädt das Ökosystem eindeutig dazu ein zu testen, ob diffusionsbasierte Generierung in realen Anwendungen praktikabel werden kann.
Wo DiffusionGemma sinnvoll ist

Die besten Anwendungsfälle sind nicht unbedingt hochwertige Langformtexte. Es sind geschwindigkeitskritische Aufgaben, bei denen der Nutzer von schneller Iteration profitiert. Inline-Bearbeitung ist ein Beispiel. Anstatt darauf zu warten, dass ein Modell einen Absatz Token für Token umschreibt, kann ein Diffusionsmodell eine ganze Passage schnell verfeinern.
Code-Ergänzung ist ein weiterer starker Kandidat. Ein Entwickler benötigt möglicherweise ein Modell, das die Mitte einer Funktion ausfüllt oder einen Codeblock anpasst und dabei berücksichtigt, was davor und danach kommt. Bidirektionale Aufmerksamkeit ist hier nützlich, weil das Modell über beide Seiten des fehlenden Abschnitts hinweg schlussfolgern kann.
Auch strukturierte und beschränkte Generierung ist interessant. Wenn die Ausgabe mehrere Abhängigkeiten hat, wie eine Tabelle, ein Rätsel, eine Vorlage oder ein formales Schema, kann Blockverfeinerung dem Modell mehr Spielraum geben, Positionen miteinander zu koordinieren. Deshalb geht es bei DiffusionGemma nicht nur darum, schneller zu sein. Es weist auch auf einen anderen Interaktionsstil für Generierung hin.
Wo autoregressive Modelle weiterhin gewinnen
Der Kompromiss ist die Qualität. Google sagt ausdrücklich, dass DiffusionGemma Geschwindigkeit und parallele Layout-Generierung priorisiert und dass seine allgemeine Ausgabequalität niedriger ist als bei standardmäßigem Gemma 4. Das ist der zentrale Grund, warum es nicht so beschrieben werden sollte, als würde es Next-Token-Prediction vollständig ersetzen.
Autoregressive Modelle haben weiterhin große Vorteile. Sie sind für die Produktion tiefgehend optimiert, bei vielen allgemeinen Aufgaben stark und werden von ausgereiften Serving-Stacks unterstützt. Sie funktionieren außerdem natürlich für dialogische Abläufe, bei denen das Modell Text in einer stetigen Sequenz fortsetzt.
Die realistische Zukunft besteht wahrscheinlich nicht darin, dass eine Decoding-Methode die andere ersetzt. Wahrscheinlicher ist, dass KI-Systeme unterschiedliche Aufgaben an unterschiedliche Generierungsstrategien weiterleiten. Autoregressive Modelle könnten der Standard für hochwertigen allgemeinen Chat und Schlussfolgern bleiben, während Diffusions-Sprachmodelle schnelle Bearbeitung, lokale Generierung, Code-Ergänzung und andere interaktive Workloads antreiben könnten.
Worauf Entwickler als Nächstes achten sollten
Die größte Frage ist, ob Diffusion-Sprachmodelle die Qualitätslücke schließen können, während sie den Latenzvorteil beibehalten. Geschwindigkeit allein reicht nicht aus, wenn die Ausgabe zu viele Korrekturen benötigt. Wenn sich die Qualität jedoch verbessert, könnte die Architektur für lokale KI, IDE-Assistenten, Dokumentbearbeitung und Echtzeit-Schnittstellen sehr wichtig werden.
Die zweite Frage betrifft die Serving-Infrastruktur. Die Unterstützung von vLLM ist wichtig, weil Diffusion-Sprachmodelle ein anderes Decoding-Verhalten erfordern: bidirektionale Aufmerksamkeit, iterative Entrauschung, benutzerdefiniertes Sampling und Commit-Logik auf Blockebene. Wenn Inferenz-Frameworks dies erleichtern, werden mehr Entwickler experimentieren.
Die dritte Frage betrifft das Produktdesign. Ein Diffusion-Textmodell ist nicht einfach nur ein schnellerer Chatbot. Seine natürliche Schnittstelle ähnelt möglicherweise eher einem intelligenten Editor, der eine Arbeitsfläche überarbeitet, Lücken füllt und Entwürfe direkt verbessert. Das könnte verändern, wie Nutzer KI-Schreib- und Coding-Tools erleben.
Abschließende Erkenntnis
DiffusionGemma bedeutet nicht, dass Google heute die Next-Token-Vorhersage ersetzt. Es bedeutet, dass Google Textdiffusion praktisch genug macht, damit Entwickler sie in realen Workflows testen können.
Die wichtige Veränderung ist nicht nur schnellerer Text. Es ist die Idee, dass Sprachgenerierung nicht immer so aussehen muss, als würde ein Modell von links nach rechts tippen. Manchmal ist die bessere Interaktion eine Arbeitsfläche, die parallel verfeinert wird.
Wenn sich dieses Muster verbessert, könnte KI-Textgenerierung schneller, interaktiver und besser für lokale Geräte geeignet werden. Vorerst sollte DiffusionGemma jedoch als experimentelles offenes Modell mit einer sehr klaren Botschaft verstanden werden: Die Zukunft der Sprachgenerierung könnte mehr als einen Decoding-Pfad umfassen.
Kurzvergleich
Frage | Autoregressive LLMs | DiffusionGemma |
Generierungsmuster | Sagt das nächste Token sequenziell voraus | Verfeinert eine Token-Arbeitsfläche parallel |
Stärke | Hochwertige Produktionsausgaben | Interaktive Generierung mit niedriger Latenz |
Kontextfluss | Während des Decodings meist von links nach rechts | Bidirektional innerhalb jeder Entrauschungs-Arbeitsfläche |
Am besten geeignet für | Allgemeinen Chat, Schlussfolgern, ausgereiftes Serving | Bearbeitung, Code-Infilling, schnelle lokale Workflows |
Status | Dominantes Produktionsparadigma | Experimentelles offenes Modell |
CTA
Wenn Sie KI-Produkte entwickeln, sollten Sie DiffusionGemma nicht als einfaches Ersatzmodell betrachten. Betrachten Sie es als ein neues Generierungsmuster, das dort getestet werden sollte, wo Inferenzlatenz, lokale Reaktionsfähigkeit und nichtlineare Bearbeitung am wichtigsten sind.
Für Teams, die Entwicklertools, Schreibassistenten, Coding-Workflows oder KI-Erlebnisse auf dem Gerät entwickeln, ist dies eine Architektur, die es wert ist, frühzeitig benchmarked zu werden.
FAQ
Was ist DiffusionGemma?
DiffusionGemma ist Googles experimentelles offenes Textgenerierungsmodell, das diskrete Diffusion nutzt, um Token-Blöcke parallel zu verfeinern, anstatt sich ausschließlich auf Token-für-Token-Generierung zu verlassen.
Ersetzt Google die Next-Token-Vorhersage?
Nein. Google empfiehlt weiterhin das standardmäßige Gemma 4 für maximale Produktionsqualität. DiffusionGemma ist experimentell und für geschwindigkeitskritische Workflows optimiert.
Warum ist DiffusionGemma schneller?
Es arbeitet parallel auf einer Arbeitsfläche mit 256 Tokens und verlagert mehr Arbeit in Richtung GPU-Compute, anstatt strikt jeweils ein Token nach dem anderen zu generieren.
Was ist eine 256-Token-Canvas?
Es ist ein Block von Token-Positionen, den das Modell initialisiert, entrauscht, verfeinert und anschließend festschreibt, bevor es zum nächsten Block übergeht.
Wer sollte DiffusionGemma testen?
Entwickler, die an lokaler Inferenz, Inline-Bearbeitung, Code-Infilling, schnellem Entwerfen und anderen interaktiven KI-Tools mit geringer Latenz arbeiten, sollten aufmerksam werden.
Verwandte Tools
- vLLM
- Colab
- Kaggle
Quellen
- DeepMind


