
Introduction
This week’s HyperAI update focuses on a strong mix of audio, video, image understanding, OCR, and speech recognition models. The headline project is Irodori-TTS-500M-v3, an open Japanese text-to-speech model that combines high-fidelity 48 kHz speech generation, zero-shot voice cloning, and fine-grained style control through emoji annotations.
The update also includes tools for prompt-based audio separation, video matting, 4D world simulation, video-to-audio generation, document OCR, on-device segmentation, expressive audio editing, and low-latency streaming ASR. Below is a cleaned-up, publication-ready version of the original weekly roundup, with the useful screenshots preserved in their original context.
Source Note
This article is based on the BAAI Hub / HyperAI weekly update published at The original page states that the article source is from WeChat and that images can be removed if there are copyright concerns.
QR codes, promotional posters, group invitation images, and unrelated recommendation banners were intentionally removed. The DiaMoE-TTS and DreamOmni2 image links are retained at their source positions, but their preview requests timed out during checking, so they are noted here instead of being treated as fully verified screenshots.
Weekly HyperAI Update Overview
From June 27 to July 3, HyperAI updated several public resources on its official website:
- 12 selected public tutorials
- 5 popular AI encyclopedia entries
- 4 AI conference deadlines in July
The main theme this week is practical experimentation. Most entries are not just paper descriptions; they provide online demos or runnable notebooks so users can quickly test the model behavior.
Selected Public Tutorials
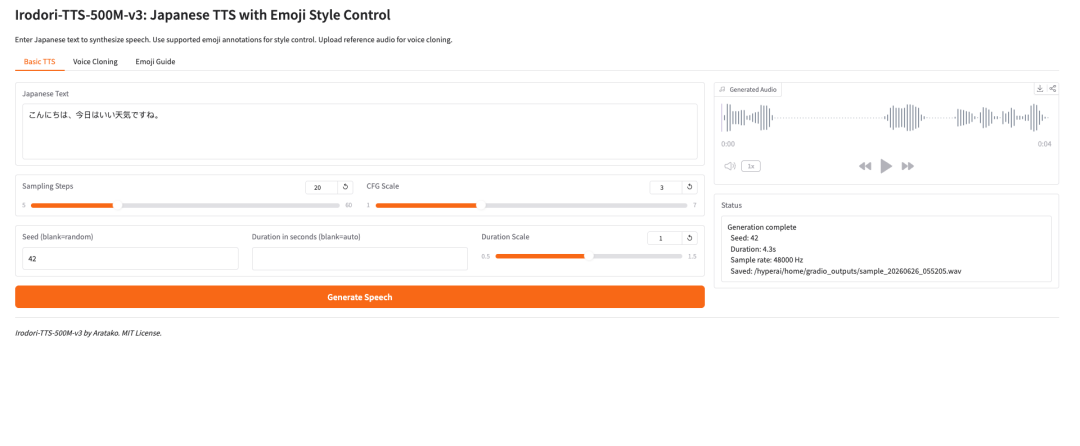
- Irodori-TTS-500M-v3: Japanese TTS with Emoji Style Control
Irodori-TTS is an open-source Japanese text-to-speech project released by developer Aratako in
2026. The featured model, Irodori-TTS-500M-v3, is designed for Japanese speech synthesis, zero-shot voice cloning, and emoji-guided voice style control.
The model is built around a Rectified Flow Diffusion Transformer (RF-DiT) architecture and generates speech in a continuous DACVAE latent space. In practical use, the most interesting point is that it can clone a target voice from only a short reference clip, usually around 3 to 10 seconds, without extra fine-tuning.
It also supports style control through emoji annotations. That makes the model more flexible than a basic TTS system: users can guide tone, emotion, pacing, and subtle non-verbal expression in a more lightweight way.
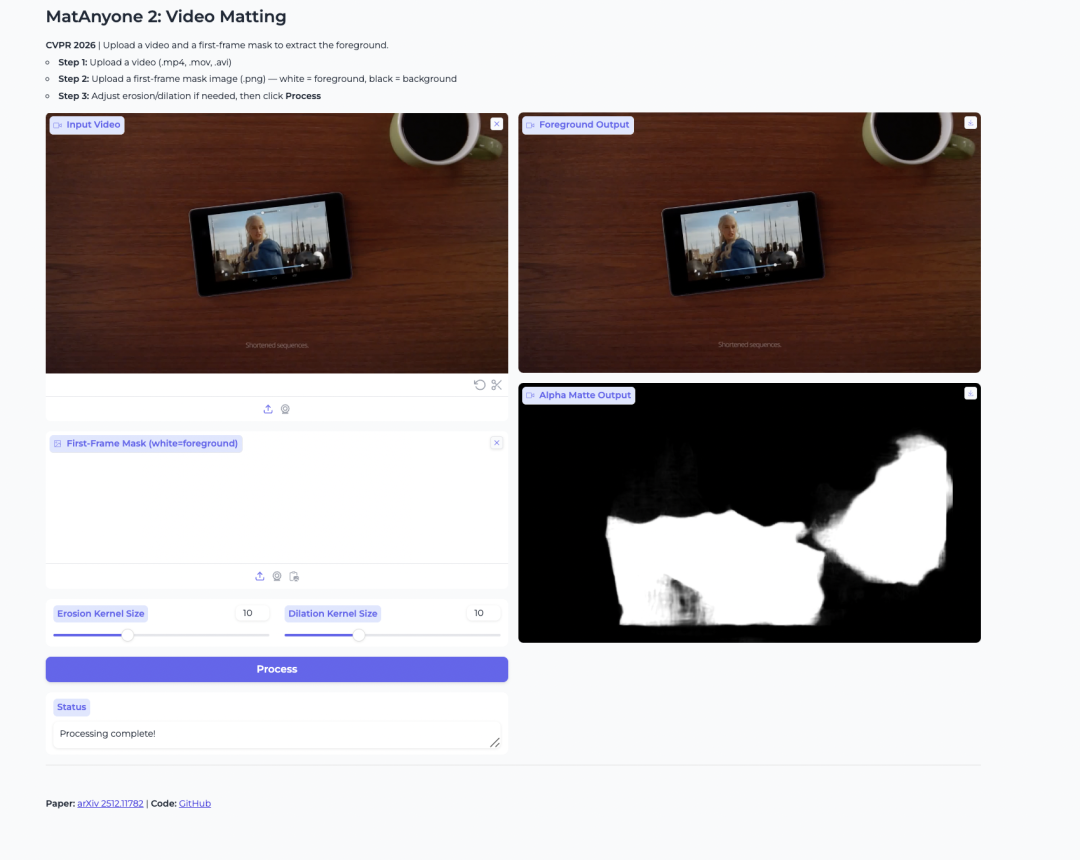
- MatAnyone 2: Video Matting for Foreground Extraction
MatAnyone 2 is a video matting model released by NTU S-Lab and SenseTime. It is built for extracting human foregrounds and generating alpha mattes from videos.
The model improves stability by using a learned quality evaluator. This helps reduce boundary artifacts and preserve details such as hair, semi-transparent edges, and foreground contours. It is also useful when the user wants to isolate a specific person in a multi-person video.
Online demo:
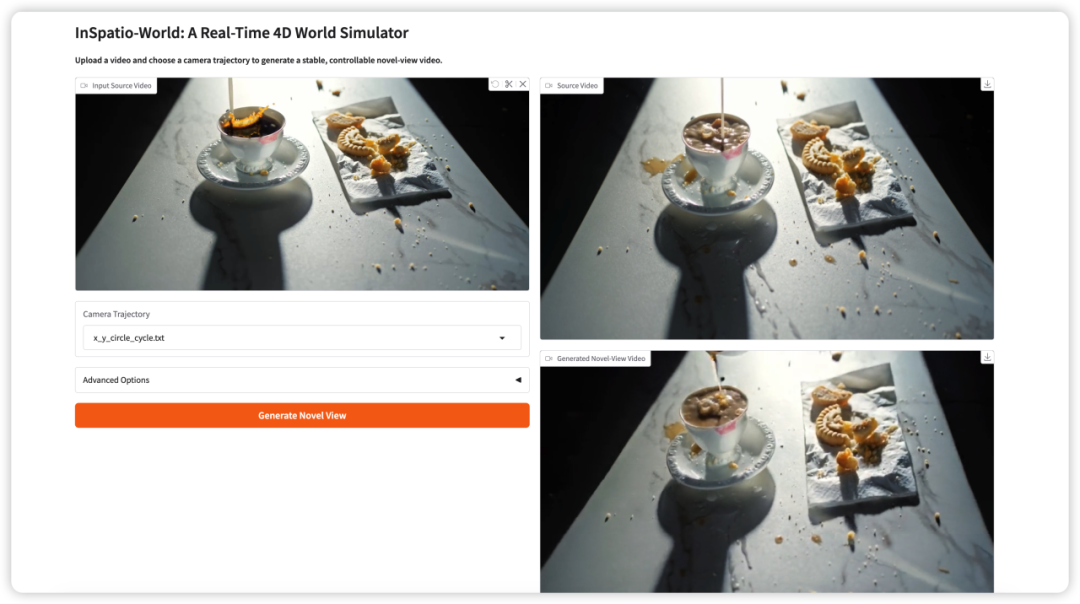
- InSpatio-World: Real-Time 4D World Simulation
InSpatio-World is a real-time 4D world simulator released by the InSpatio team in
2026. It can take an input video and a specified camera trajectory, then generate a stable new-view video.
The core idea is to make video scenes more controllable. Instead of passively watching a fixed camera view, users can define camera movement and explore the scene from new viewpoints while preserving temporal consistency.
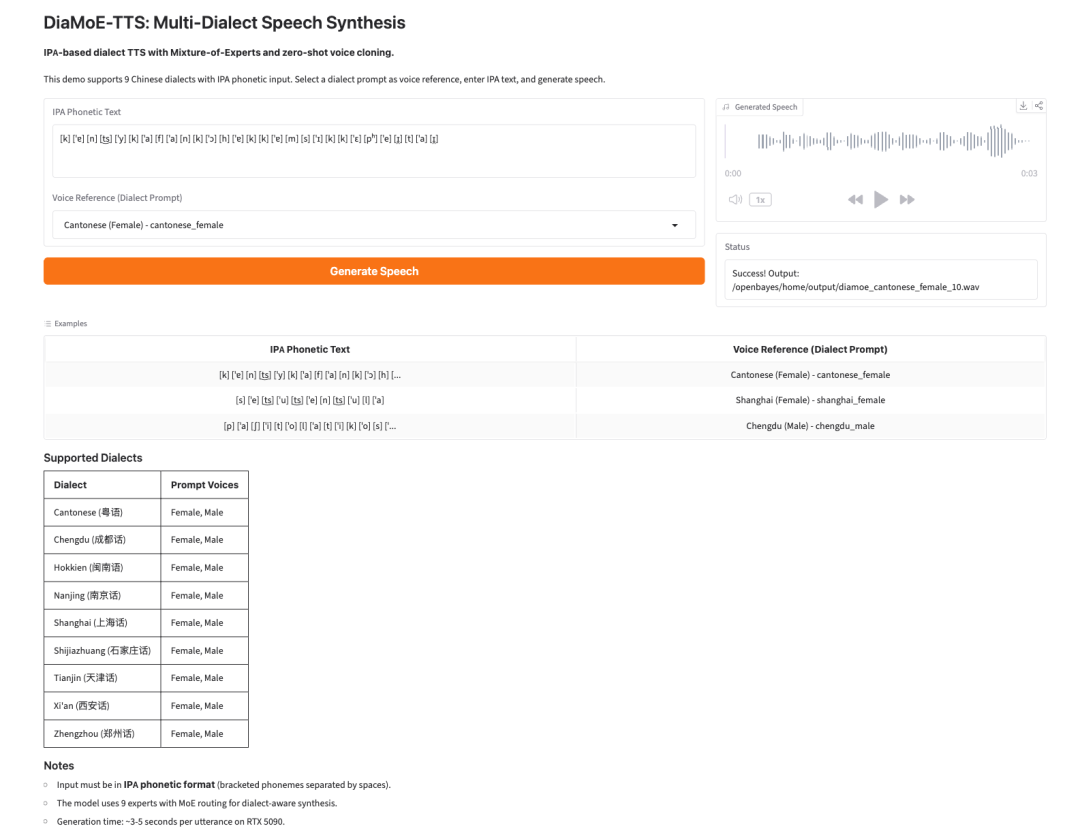
- DiaMoE-TTS: IPA-Based Multi-Dialect Speech Synthesis
DiaMoE-TTS is a multi-dialect speech synthesis framework from Giant AI Lab. It uses the International Phonetic Alphabet, or IPA, as a unified frontend for dialect speech generation.
The model combines a Mixture-of-Experts design with parameter-efficient adaptation methods such as LoRA and conditioning adapters. This allows the system to adapt more quickly to new dialects, even when only limited data is available.
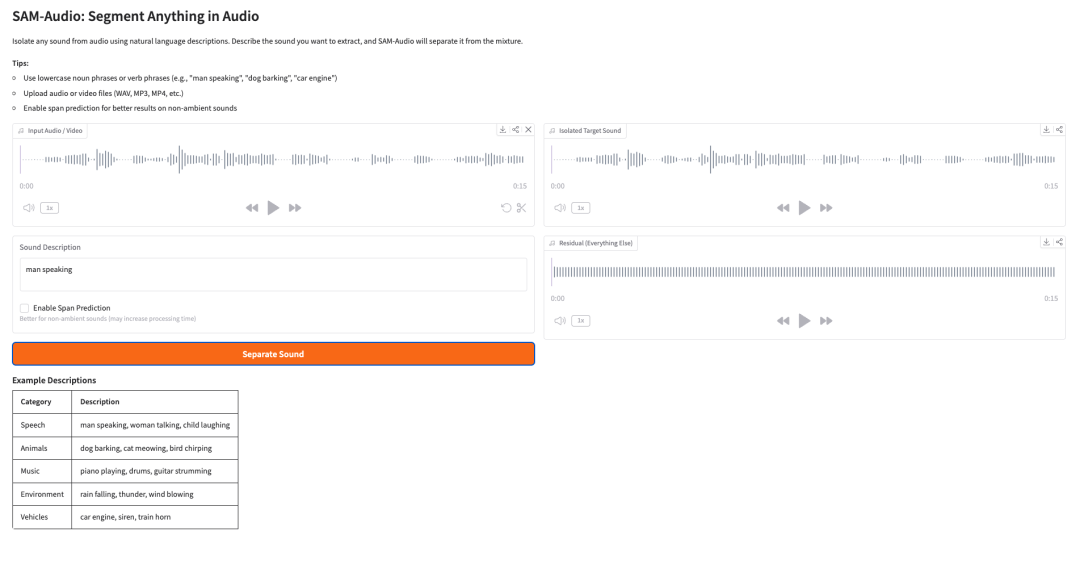
- SAM-Audio: Segment Anything in Audio
SAM-Audio is Meta’s audio source separation foundation model. It can isolate a target sound from a mixed audio signal using natural language descriptions, visual cues from video, or a selected time span.
For example, a user can describe the sound they want to separate, such as “man speaking,” “dog barking,” “car engine,” or “piano playing.” The model then attempts to separate the target audio from everything else in the mixture.
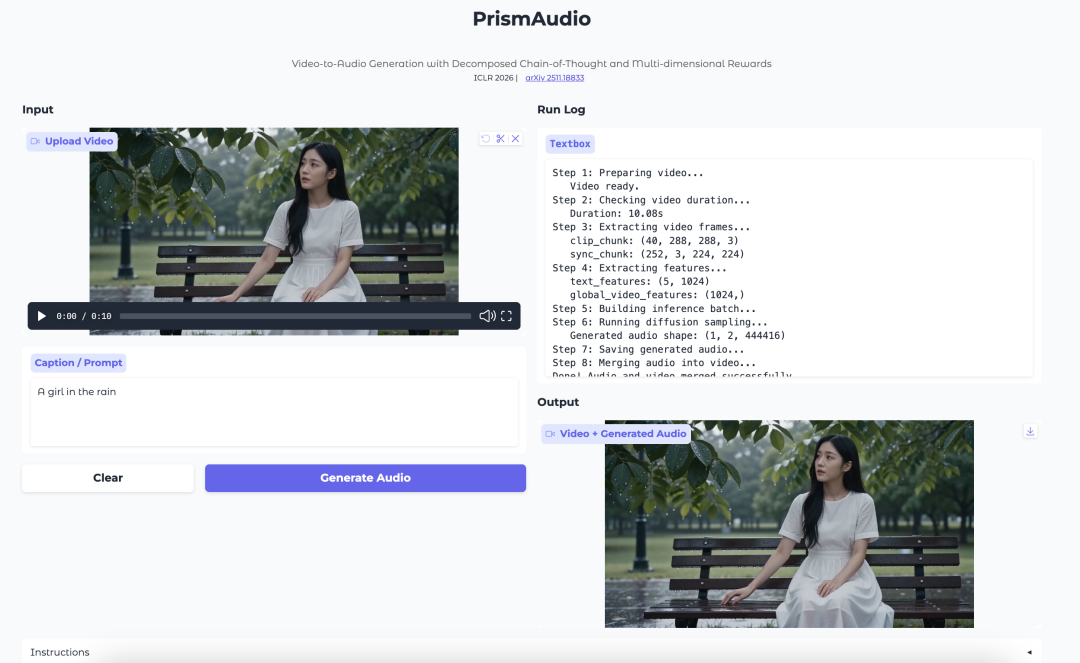
- PrismAudio: Video-to-Audio Generation with Decomposed CoT and Multi-Dimensional Rewards
PrismAudio is a video-to-audio generation model from Tongyi Lab. It focuses on generating audio that matches the visual scene, timing, atmosphere, and spatial feeling of a video.
The model introduces a decomposed Chain-of-Thought planning process. Instead of treating video-to-audio generation as one single reasoning step, it separates the process into semantic, temporal, aesthetic, and spatial dimensions. Each dimension is paired with a targeted reward signal for reinforcement learning.
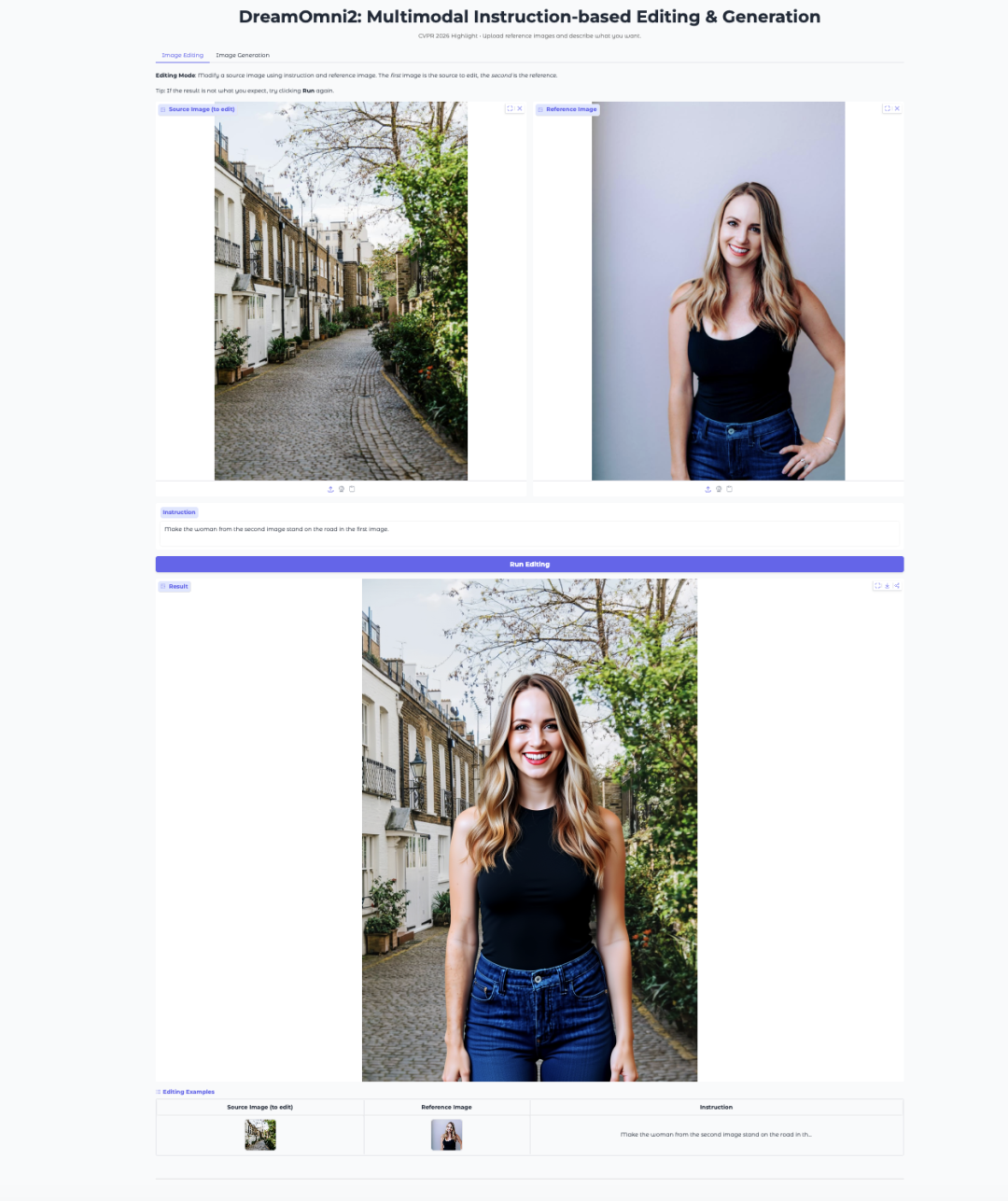
- DreamOmni2: Multimodal Instruction-Based Image Editing and Generation
DreamOmni2 is a multimodal image editing and generation model from CUHK JIA Lab. It has been accepted by CVPR 2026 as a Highlight paper.
The model is built on FLUX.1-Kontext-dev and uses a fine-tuned Qwen2.5-VL-7B visual language model to handle instructions. It supports natural language prompts together with reference images, which makes it suitable for tasks such as object replacement, style transfer, pose imitation, and concept-driven generation.
- PixelRefer: Fine-Grained Object Understanding for Images and Videos
PixelRefer is a unified image and video object understanding framework from Alibaba DAMO Academy. It focuses on fine-grained object-centric comprehension instead of only describing an entire scene.
The framework supports region-level pointing, captioning, and question answering. It also introduces a scale-adaptive object tokenizer and a lighter PixelRefer-Lite variant to make object representation more compact and efficient.

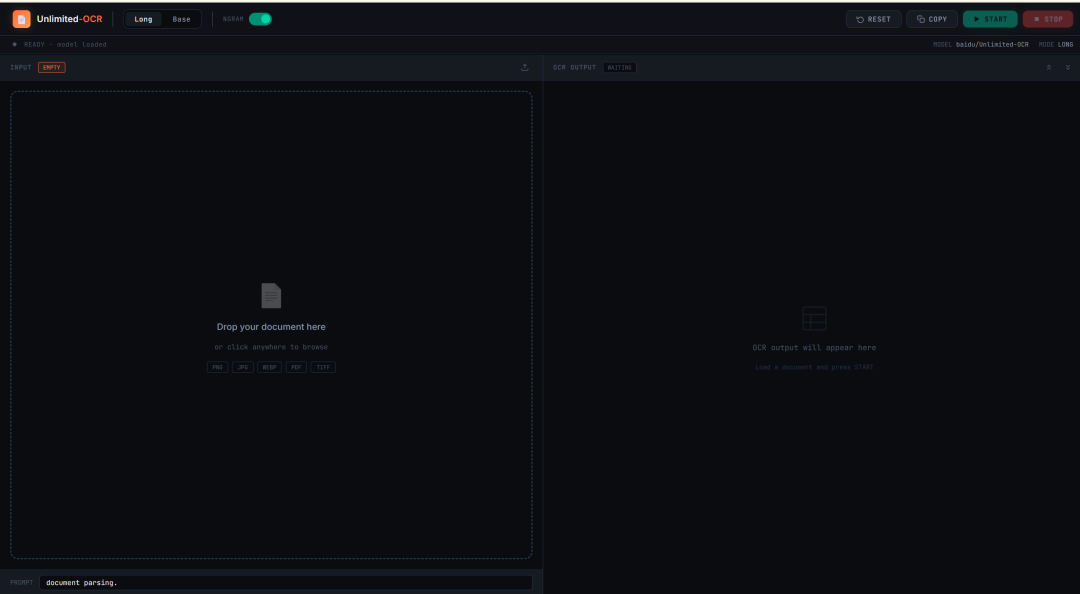
- Unlimited-OCR: One-Shot Long-Document OCR and Layout Parsing
Unlimited-OCR is an OCR and document layout parsing project released by Baidu in
2026. It is designed for long-document parsing rather than only single-page recognition.
The project can process single document images, multi-page images, and pages converted from PDFs. It is especially useful for papers, reports, scanned documents, long tables, and multi-page structured materials.
- EdgeTAM: Promptable Image and Video Segmentation for Edge Devices
EdgeTAM is an on-device Track Anything Model developed by Meta Reality Labs and NTU S-Lab. It is designed for resource-constrained devices while keeping the interactive segmentation ability of SAM-style models.
The model reduces the memory attention bottleneck of SAM 2 through a 2D Spatial Perceiver and a distillation pipeline. In practice, that means it can support promptable segmentation and video object tracking more efficiently on edge hardware.

- Step-Audio-EditX: Zero-Shot Voice Cloning and Expressive Audio Editing
Step-Audio-EditX is an audio editing model from StepFun. It combines a 3B-parameter LLM-based audio model with reinforcement learning to support zero-shot voice cloning and expressive audio editing.
The model can handle Mandarin, English, Sichuanese, Cantonese, Japanese, and Korean. It is built for tasks such as emotion control, speaking-style editing, paralinguistic editing, and iterative audio refinement.

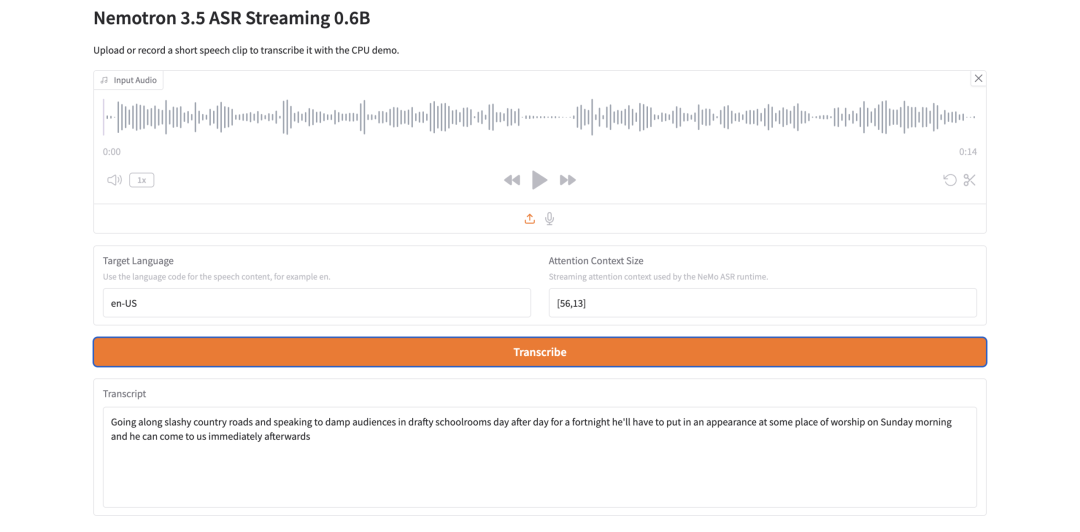
- Nemotron 3.5 ASR Streaming 0.6B: Lightweight Streaming Speech Recognition
Nemotron 3.5 ASR Streaming 0.6B is an automatic speech recognition model from NVIDIA. It is built for low-latency streaming transcription and uses a cache-aware FastConformer-RNNT architecture.
The key design is context reuse. During streaming inference, the model reuses encoder context instead of recomputing overlapping audio chunks, which helps reduce redundant computation and improve real-time performance.
Popular Encyclopedia Entries
HyperAI also highlighted five popular AI encyclopedia entries this week:
- Large Language Model (LLM)
- World Action Model (WAM)
- Harmonic Mean
- Virtual Screening
- Reinforcement Learning from AI Feedback (RLAIF)
HyperAI’s wiki collects hundreds of AI-related concepts and explanations. It is useful for readers who want a quick way to understand terms that often appear in papers, tutorials, and model documentation.
AI Conference Deadlines in July
The original update also lists several AI and computer science conference deadlines in July. All deadline times are marked as AoE time.
| Date | Time | Conference |
|---|---|---|
| July 09 | 23:59:59 | POPL 2027 |
| July 10 | 23:59:59 | ICSE 2027 |
| July 17 | 23:59:59 | SIGMOD 2027 |
| July 28 | 23:59:59 | AAAI 2027 |
About HyperAI
HyperAI is an artificial intelligence and high-performance computing community. Its website provides public resources for developers, researchers, and AI learners.
According to the original source, HyperAI has already collected or supported:
- 2,100+ public datasets with domestic acceleration nodes
- 700+ classic and popular online tutorials
- 300+ AI4Science paper case studies
- 700+ AI-related encyclopedia entries
- A complete Chinese documentation mirror for Apache TVM
FAQ
What is Irodori-TTS-500M-v3?
Irodori-TTS-500M-v3 is an open Japanese text-to-speech model based on an RF-DiT architecture. It supports Japanese speech generation, short-reference zero-shot voice cloning, and emoji-based style control.
Can Irodori-TTS clone a voice without fine-tuning?
Yes. The original update describes Irodori-TTS as supporting zero-shot voice cloning from a short reference audio clip, typically around 3 to 10 seconds. The effect still depends on the quality and clarity of the reference audio.
What is SAM-Audio used for?
SAM-Audio is used for prompt-based audio source separation. Users can describe the sound they want to extract, provide visual cues, or specify a time range to isolate a target sound from a mixed recording.
What is the difference between video matting and video segmentation?
Video segmentation usually separates objects into regions or masks, while video matting estimates a more detailed alpha matte. Matting is especially important for clean foreground extraction, hair detail, semi-transparent edges, and compositing.
What does PrismAudio generate?
PrismAudio generates audio for video. It tries to align generated sound with the video’s semantic content, timing, aesthetic feeling, and spatial cues.
Why is Unlimited-OCR useful for long documents?
Unlimited-OCR is designed for long-horizon parsing, not just isolated single-page OCR. It can be useful when dealing with papers, reports, scanned files, long tables, or multi-page PDF-derived images.
Is Nemotron 3.5 ASR Streaming 0.6B suitable for real-time speech transcription?
Yes, it is designed for low-latency streaming ASR. Its cache-aware FastConformer-RNNT architecture reuses context during streaming inference, which helps reduce redundant computation.
Related Tools
- Irodori-TTS: Open-source Japanese TTS with reference-audio voice cloning and style control.
- Irodori-TTS-500M-v3 on Hugging Face: Model page for the 500M v3 Japanese TTS checkpoint.
- SAM-Audio: Meta’s repository for Segment Anything in Audio inference and examples.
- MatAnyone 2: Project page for the MatAnyone 2 video matting framework.
- InSpatio-World: Project page for real-time interactive 4D world simulation.
- DiaMoE-TTS: GitHub repository for IPA-based multi-dialect speech synthesis.
- PrismAudio: Project page for video-to-audio generation with decomposed CoT and multi-dimensional rewards.
- DreamOmni2: Open-source multimodal instruction-based image editing and generation project.
- PixelRefer: Alibaba DAMO Academy’s framework for fine-grained image and video object understanding.
- Unlimited-OCR: Baidu’s long-horizon OCR and document parsing project.
- EdgeTAM: Meta’s on-device track-anything model for promptable image and video segmentation.
- Step-Audio-EditX: StepFun’s model for zero-shot voice cloning and expressive audio editing.
- Nemotron 3.5 ASR Streaming 0.6B: NVIDIA’s Hugging Face model page for low-latency streaming ASR.
Related Links
- Original BAAI Hub Article: Source article for this weekly HyperAI update.
- HyperAI Official Website: Main portal for HyperAI tutorials, papers, datasets, and AI resources.
- HyperAI Wiki: AI encyclopedia portal covering common concepts and research terms.
- HyperAI Conference Tracker: Tracker for AI and computer science conference deadlines.
- Meta SAM-Audio Research Page: Official research page for Segment Anything Model Audio.
- SAM-Audio Paper on arXiv: Research paper describing the SAM-Audio foundation model.
- MatAnyone 2 Paper on arXiv: Paper for MatAnyone 2 and its learned matting quality evaluator.
- Unlimited-OCR Paper on arXiv: Technical report for Unlimited OCR and long-horizon parsing.
Summary
This weekly update brings together a useful group of new AI demos and model resources, especially around audio generation, speech recognition, video processing, image understanding, and long-document OCR.
The most practical entries are Irodori-TTS for Japanese voice generation, SAM-Audio for prompt-based sound separation, MatAnyone 2 for clean video matting, Unlimited-OCR for long documents, and Nemotron 3.5 ASR for streaming speech recognition.
Overall, this roundup is useful for readers who want to quickly discover which new AI models are worth testing, what each one does, and where to try them.


