
Qwen-AgentWorld ist ein vom Qwen-Team veröffentlichtes Sprach-Weltmodell zur Simulation von Agentenumgebungen. Anstatt wie ein allgemeines Chatmodell nur Fragen zu beantworten, ist es darauf ausgelegt vorherzusagen, was eine Umgebung zurückgeben würde, nachdem ein Agent eine Aktion ausgeführt hat.
Dadurch ist es besonders relevant für die KI-Agentenforschung, simuliertes Reinforcement Learning, Benchmark-Evaluierungen und lokale Experimente rund um Terminal-, Software-Engineering-, Such-, MCP-, Web-, Betriebssystem- und Android-ähnliche Umgebungen.
Dieser Artikel ist eine leicht überarbeitete und übersetzte Version des ursprünglichen chinesischen Artikels. Struktur, technischer Ablauf, Befehle, Tabellen und Kernaussagen wurden beibehalten, während die Sprache für eine flüssigere englische Lektüre und SEO-Veröffentlichung angepasst wurde.
Quellenhinweis: Der ursprüngliche Artikel wurde auf CSDN veröffentlicht und gibt an, der Lizenz CC BY-SA 4.0 zu folgen. Originalquelle: Qwen-AgentWorld完整部署指南:免费开源,性能超GPT-5.4,5分钟跑起来. Verifizierungshinweis: Offizielle Qwen-Seiten bestätigen die öffentliche Veröffentlichung der Modellgewichte von
Qwen-AgentWorld-35B-A3BundAgentWorldBench. Das größereQwen-AgentWorld-397B-A17Bist in offiziellen Benchmark-Ergebnissen enthalten, aber die öffentliche Modellseite und die GitHub-Veröffentlichung verweisen hauptsächlich auf die Modellgewichte des 35B-A3B-Modells.
1. Hintergrund: Warum brauchen wir ein Sprach-Weltmodell?
In den vergangenen zwei Jahren haben sich KI-Agenten rasch von einfachen Chat-Assistenten zu Werkzeugen entwickelt, die Websites bedienen, Terminalbefehle ausführen, mobile Apps steuern und Aufgaben in der Softwareentwicklung erledigen können.
Doch das Training eines leistungsfähigen Agenten ist teuer. Es erfordert oft große Mengen an Interaktionen mit realen Umgebungen, und das bringt mehrere praktische Probleme mit sich:
Der Aufbau und die Wartung von Umgebungen sind mühsam.
Die Datenerfassung ist langsam und schwer zu skalieren.
Reale Umgebungen bergen Risiken, insbesondere beim Testen von Fehlerfällen oder beim Einbringen kontrollierter Störungen.
Ein Language World Model, oder LWM, wurde entwickelt, um dieses Problem zu lösen. Die Idee ist einfach, aber wirkungsvoll: Ein Modell übernimmt die Rolle der Umgebung. Auf Grundlage einer Agentenaktion und des bisherigen Interaktionsverlaufs sagt das Modell den nächsten Umgebungszustand voraus.
Mit diesem Ansatz können Agenten in Simulationen trainiert und evaluiert werden, statt sich immer auf reale Systeme verlassen zu müssen.
Am 24.06.2026 veröffentlichte das Qwen-Team Qwen-AgentWorld, ein natives Language World Model, das sieben Interaktionsdomänen für Agenten in einem Modell vereint. Der begleitende Benchmark AgentWorldBench wurde ebenfalls veröffentlicht.
Offizielle Ressourcen:
GitHub: QwenLM/Qwen-AgentWorld
2. Kerngedanke: Was macht es zu einem „nativen“ Weltmodell?
Das Wort nativ ist hier wichtig. Qwen-AgentWorld ist nicht einfach ein Allzweck-LLM, das nach dem Training angepasst wurde, um eine Umgebung zu imitieren. Sein Ziel der Weltmodellierung ist von Anfang an in den Trainingsprozess integriert.
Vergleichsdimension | Traditioneller Ansatz | Qwen-AgentWorld |
Ausgangspunkt des Trainings | Feinabstimmung eines allgemeinen LLM | Umgebungsmodellierung von CPT an als Ziel behandeln |
Trainingsprozess | In der Regel nur SFT oder RL | CPT → SFT → RL |
Umgebungswissen | Durch zusätzliche Daten oder Anpassung hinzugefügt | Während des Trainings internalisiert |
Domänenabdeckung | Eine oder wenige Domänen | Sieben Domänen in einem Modell |
Mit anderen Worten: Qwen-AgentWorld ist nicht einfach ein allgemeines Modell, das mit Prompts umhüllt wurde. Es wird von den unteren Ebenen der Pipeline an darauf trainiert, den nächsten Zustand einer Umgebung vorherzusagen.
Dadurch erhält das Modell ein stärker strukturiertes Verständnis der Umgebungsdynamik, insbesondere bei der Simulation langer Interaktionsverläufe.
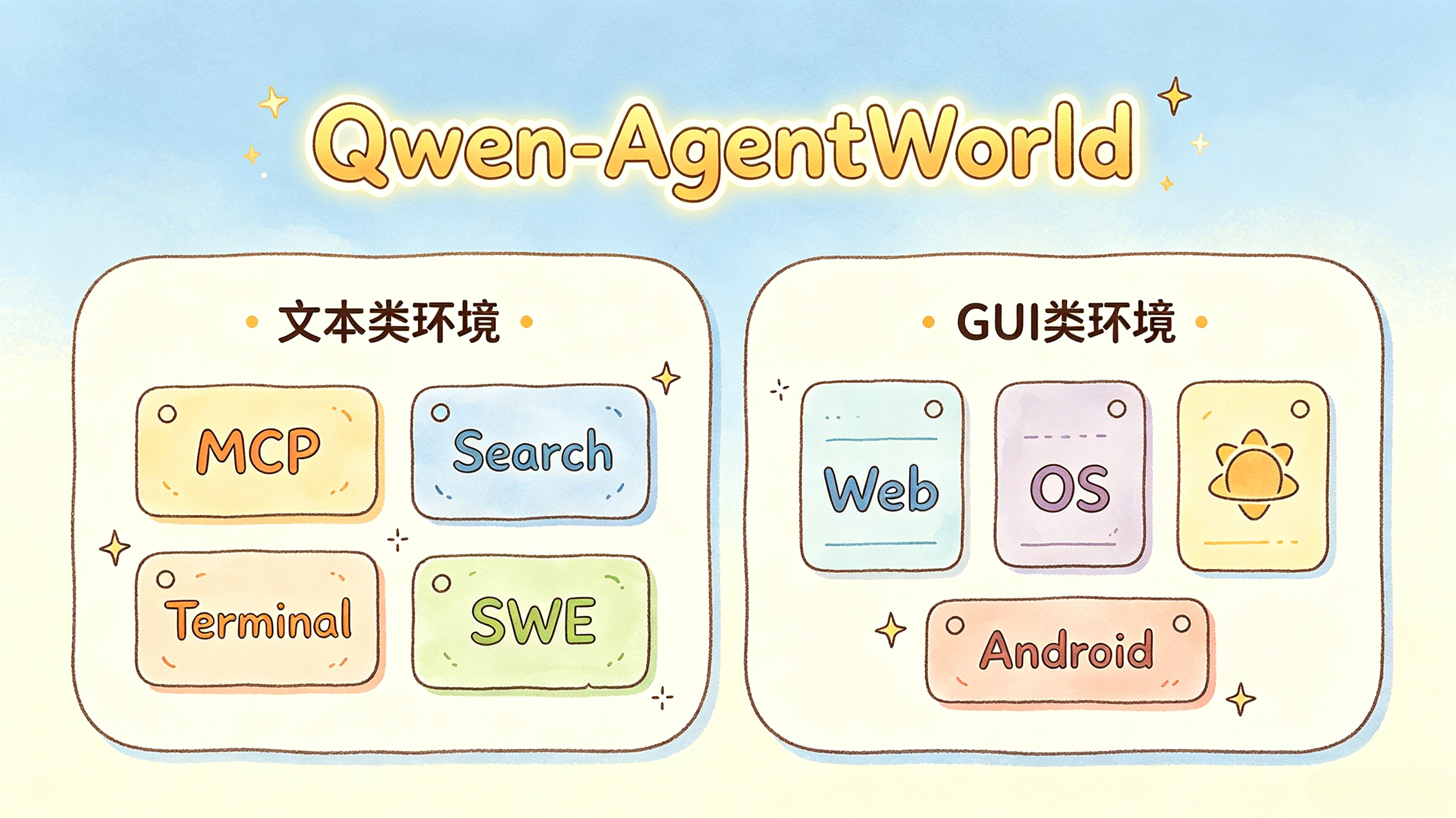
3. Sieben Domänen: Text- und GUI-Umgebungen in einem Modell
Qwen-AgentWorld unterteilt Agenten-Interaktionsszenarien in zwei große Gruppen: textbasierte Umgebungen und GUI-basierte Umgebungen.
┌──────────────────────────────────────────┐
│ Qwen-AgentWorld │
│ │
│ Textumgebungen GUI-Umgebungen │
│ ┌──────────┐ ┌──────────────────┐ │
│ │ MCP │ │ Web │ │
│ │ Suche │ │ OS │ │
│ │ Terminal│ │ Android │ │
│ │ SWE │ └──────────────────┘ │
│ └──────────┘ │
└──────────────────────────────────────────┘Bereich | Typ | Beschreibung |
MCP | Text | Werkzeugaufrufe und Interaktionen mit dem Model Context Protocol |
Suche | Text | Interaktion mit Suchmaschinen und Abrufverhalten |
Terminal | Text | Ausführung von Linux-Terminalbefehlen |
SWE | Text | Softwareentwicklungsaufgaben, wie etwa Code-Korrekturen |
Web | GUI | Interaktion mit Browsern und Webseiten |
OS | GUI | Interaktion mit Desktop-Betriebssystemen |
Android | GUI | Interaktion mit mobilen Apps und Android-ähnlichen Benutzeroberflächen |
Für die drei GUI-Domänen werden Beobachtungen als darstellbarer Code und nicht als rohe Pixel-Frames repräsentiert. Dadurch kann ein textbasiertes Weltmodell visuelle Umgebungen abdecken, ohne vollständige Bildsequenzen direkt zu verarbeiten.
Das Modell wurde mit mehr als 10 Millionen realen Interaktionstrajektorien aus den sieben Domänen trainiert.
4. Dreistufige Trainingspipeline
Qwen-AgentWorld verwendet eine verbundene dreistufige Trainingspipeline: CPT → SFT → RL.
Stufe 1: CPT — Einbringen von Umgebungswissen
Während des kontinuierlichen Vortrainings lernt das Modell aus groß angelegten Interaktionstrajektorien mit realen Umgebungen. Diese Stufe verankert die Umgebungsdynamik in den Modellgewichten.
Der Originalartikel erwähnt außerdem eine informationstheoretische Verlustmaske auf Turn-Ebene. Ziel ist es, zu identifizieren, welche Dialogrunden tatsächlich Informationen über den Umgebungszustand enthalten, und Rauschen aus weniger nützlichen Runden zu reduzieren.
Stufe 2: SFT — Aktivierung von Chain-of-Thought-Reasoning
Das überwachte Fine-Tuning wandelt die Vorhersage des nächsten Zustands in ein Reasoning-Muster im Chain-of-Thought-Stil um.
Anstatt direkt ein vorhergesagtes Ergebnis auszugeben, lernt das Modell, zu begründen, warum sich ein Zustand ändern sollte, bevor es die nächste Beobachtung generiert.
Stufe 3: RL — Verfeinerung der Simulationstreue
Die Reinforcement-Learning-Stufe verwendet hybride Belohnungssignale, einschließlich des GSPO-Algorithmus, um die Ausgabequalität zu verbessern.
Die Optimierung konzentriert sich auf:
Formatkorrektheit
Faktische Genauigkeit
Kontextkonsistenz
Realismus
Gesamtqualität der Simulation
Im Originalartikel erwähnte emergente Verhaltensweisen: Qwen-AgentWorld zeigt Berichten zufolge Selbstkorrekturverhalten, die Verhinderung von Informationslecks in Suchszenarien sowie mehrstufiges kausales Reasoning bei einigen Vorhersagen von Befehlsausgaben.
5. Liste der Open-Source-Modelle
Version | Parameter | Aktivierte Parameter | Kontextlänge | Positionierung |
Qwen-AgentWorld-35B-A3B | 35B | 3B | 256K Token | Öffentliches, effizientes offenes Modell |
Qwen-AgentWorld-397B-A17B | 397B | 17B | In der ursprünglichen Tabelle nicht eindeutig aufgeführt |
Flaggschiff-Benchmark-Modell
AgentWorldBench
—
—
—
Evaluierungs-Benchmark
Architekturdetails des 35B-A3B
Basismodell: Qwen3.5-35B-A3B-Base
Modelltyp: Kausales Sprachmodell / Sprach-Weltmodell
Architekturstil: Hybride lineare Attention + MoE
Verborgene Dimension: 2048
Schichten: 40 Schichten
Schichtlayout: wiederholte Gruppen mit Gated DeltaNet-, Gated Attention- und MoE-Komponenten
Experten: 256 Experten
Aktivierte Experten: 8 geroutete Experten + 1 gemeinsamer Experte
Kontextlänge: 262.144 Token
Empfohlener Mindestkontext: 128K Token für eine bessere Simulationsqualität bei langen Trajektorien
Die offizielle Hugging-Face-Dokumentation weist außerdem darauf hin, dass das Modell mit Transformers, vLLM und SGLang kompatibel ist.
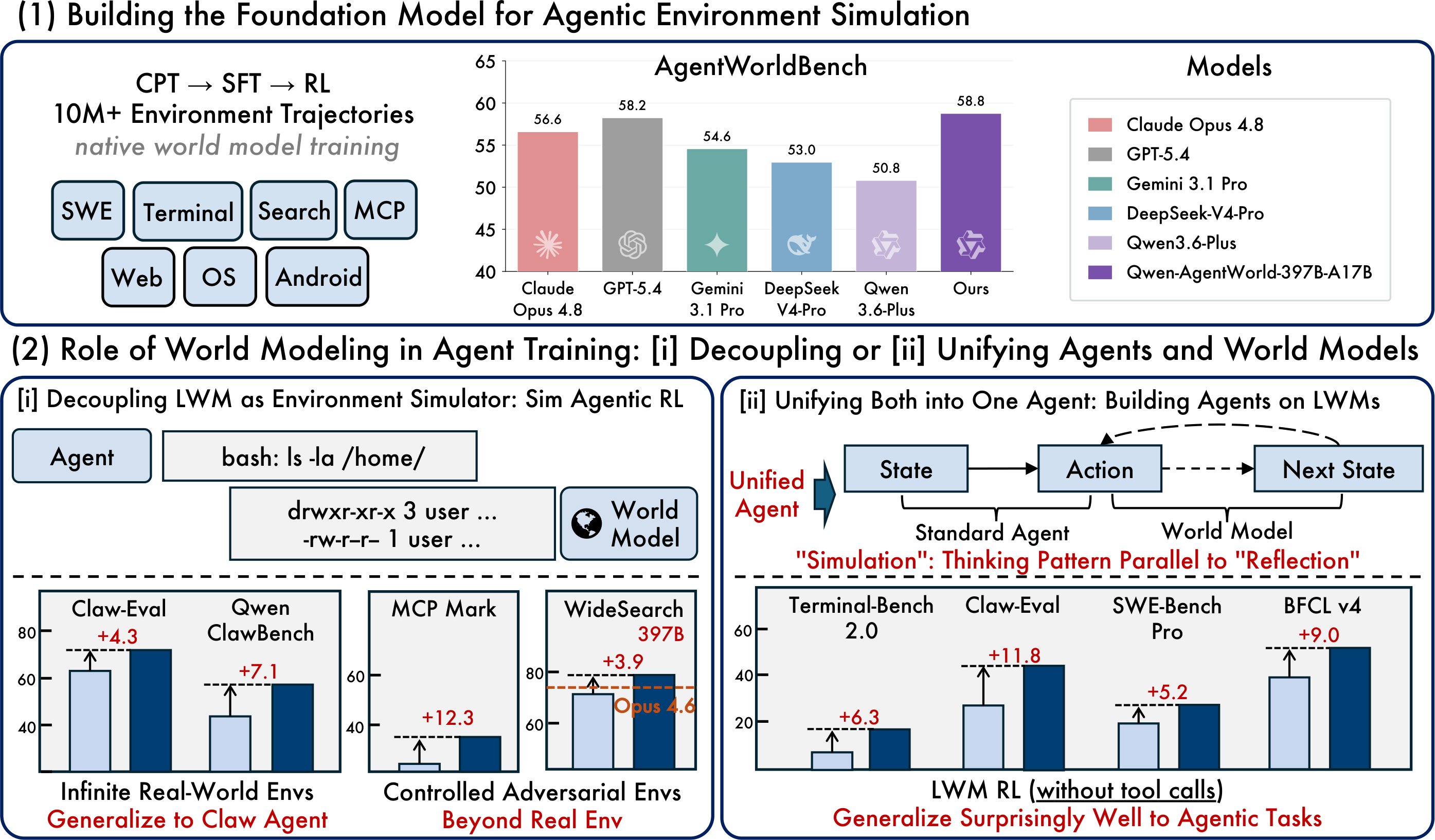
6. Leistungsvergleich: AgentWorldBench-Ergebnisse
AgentWorldBench bewertet jedes Modell anhand von fünf Dimensionen: Format, Faktizität, Konsistenz, Realismus und Qualität. Die Punktzahlen werden auf eine Skala von 0 bis 100 normalisiert, wobei höher besser ist.
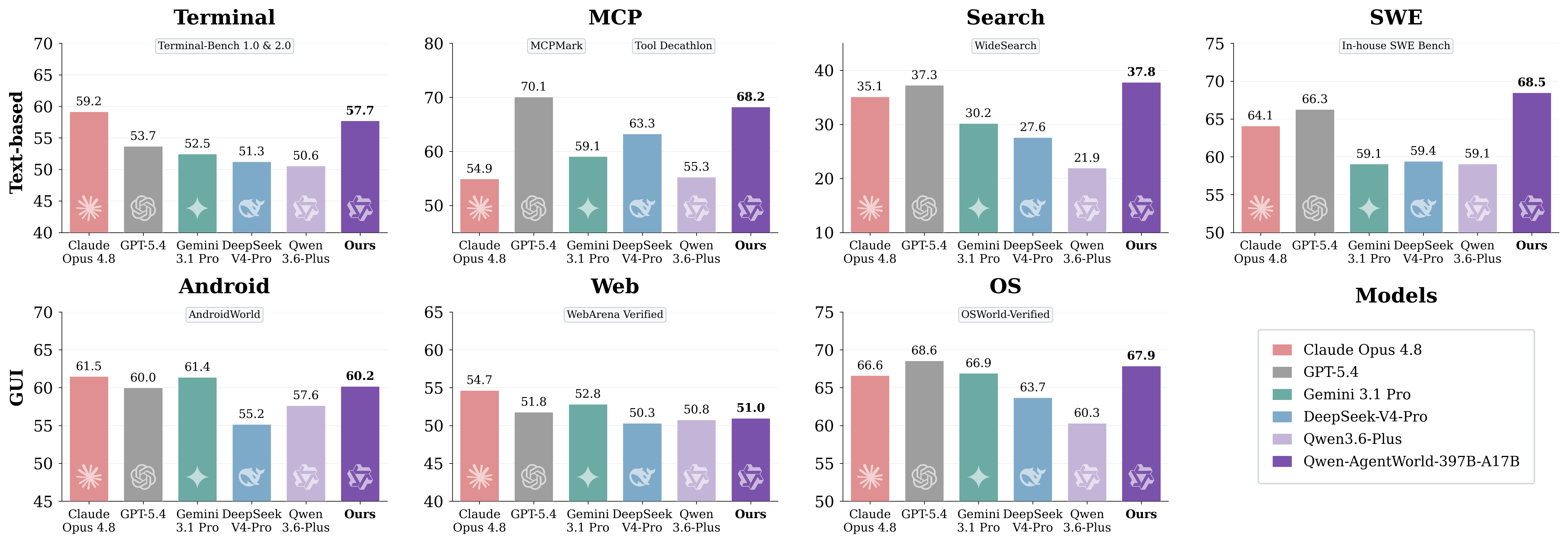
Vollständige Rangliste nach Gesamtpunktzahl
Modell | MCP | Suche | Terminal | SWE | Android | Web | OS | Gesamt |
Qwen-AgentWorld-397B-A17B | 68.24 | 37.82 | 57.73 | 68.49 | 60.20 | 50.98 | 67.89 | 58.71 |
GPT-5.4 | 70.10 | 37.26 | 53.69 | 66.29 | 60.00 | 51.80 | 68.58 | 58.25 |
Claude Opus 4.6 | 69.90 | 29.30 | 57.51 | 64.55 | 61.74 | 51.42 | 70.20 | 57.80 |
Claude Opus 4.8 | 54.93 | 35.14 | 59.18 | 64.10 | 61.50 | 54.66 | 66.62 | 56.59 |
Qwen-AgentWorld-35B-A3B | 64.79 | 36.69 | 53.96 | 65.63 | 58.17 | 49.55 | 65.92 | 56.39 |
Claude Sonnet 4.6 | 70.00 | 28.79 | 56.98 | 64.52 | 58.03 | 50.78 | 63.17 | 56.04 |
Qwen3.5-397B-A17B | 68.31 | 30.81 | 55.30 | 64.44 | 54.90 | 48.55 | 54.74 | |
Gemini 3.1 Pro | 59.07 | 30.21 | 52.47 | 59.07 | 61.40 | 52.83 | 66.92 | 54.57 |
DeepSeek-V4-Pro | 63.27 | 27.61 | 51.26 | 59.44 | 55.17 | 50.32 | 63.70 | 52.97 |
Qwen3.5-35B-A3B | 57.87 | 25.98 | 46.13 | 47.58 | 53.18 | 47.10 | 56.27 | 47.73 |
Wichtige Erkenntnisse aus dem Originalartikel:
Qwen-AgentWorld-397B-A17Berreicht eine Gesamtpunktzahl von 58.71 und belegt in der aufgeführten AgentWorldBench-Tabelle den ersten Platz.Qwen-AgentWorld-35B-A3Bverbessert sich gegenüber dem BasismodellQwen3.5-35B-A3Bum +8.66 Punkte.
Praktischer Hinweis: Betrachten Sie Benchmark-Zahlen als Referenzdaten aus dem offiziellen Benchmark-Setup. Reale Ergebnisse hängen von Hardware, Prompt-Design, Serving-Framework, Kontextlänge und der simulierten Umgebung ab.
7. Vier Anwendungsmuster und experimentelle Ergebnisse
Muster 1: Generalisierbare OOD-Umgebungserweiterung
Der Originalartikel beschreibt die Verwendung von Qwen-AgentWorld-397B-A17B für simuliertes RL in 4.000 OpenClaw-Umgebungen außerhalb der Verteilung und anschließend das Testen der Zero-Shot-Generalisation in neuen Domänen.
Trainingsmethode | Claw-Eval | QwenClawBench |
Basis-SFT | 65.4 | 47.9 |
Sim-RL mit einem allgemeinen Modellsimulator | 66.7 | 47.8 |
Sim-RL mit dem Qwen-AgentWorld-Simulator | 69.7 | 55.0 |
Verbesserung | +4.3 | +7. |
Muster 2: Steuerbare Simulation — gezielte MCP-Störung
Kontrollierte Störungen können Schwachstellen in einem Agenten wirksamer aufdecken als standardmäßiges Training in realen Umgebungen.
Konfiguration | Tool-Decathlon | MCPMark |
Basis-SFT | 32.4 | 21.5 |
Sim-RL ohne Steuerung | 31.5 | 24.6 |
Sim-RL mit Steuerung | 36.1 | 33.8 |
Verbesserung | +3.7 | +12.3 |
Muster 3: Konstruktion einer fiktiven Welt — Suchdomäne
Das Experiment in der Suchdomäne verwendet für das Training eine fiktive, aber in sich konsistente Suchwelt und bewertet anschließend die Generalisierung bei realen Suchaufgaben.
Konfiguration | WideSearch F1 Element | WideSearch F1 Zeile |
Basis-SFT, 35B | 34.02 | 13.72 |
+ Sim-RL fiktive Welt | 50.31 | 24.21 |
Verbesserung | +16.29 | +10.49 |
Muster 4: Agenten-Grundlagenmodell — LWM-RL-Warm-up-Transfer
Der Artikel beschreibt außerdem das LWM-RL-Warm-up als eine Möglichkeit, die Leistung nachgelagerter Agenten zu verbessern, ohne zusätzliches RL-Feintuning für diese spezifischen Aufgaben.
Metrik | Terminal-Bench 2.0 | SWE-Bench Verified | SWE-Bench Pro | WideSearch F1 | Claw-Eval | BFCL v4 |
Basis-SFT | 33.25 | 64.47 | 42.18 | 33.38 | 53.60 | 62.29 |
+ LWM RL-Aufwärmphase | 39.55 | 67.86 | 47.42 | 46.17 | 64.88 | 71.25 |
Verbesserung | +6.30 | +3.39 | +5.24 | +12.79 | +11.28 | +8.96 |
Highlight: Die Aufwärmdaten stammen aus einstufigen, nicht-agentischen Trajektorien, dennoch überträgt sich die Verbesserung auf komplexere mehrstufige Agentenaufgaben mit Tool-Aufrufen. Das deutet darauf hin, dass Wissen aus der Weltmodellierung über sein ursprüngliches Trainingsformat hinaus übertragen werden kann.
8. Kurzanleitung zur Bereitstellung
Methode 1: Bereitstellung mit SGLang
SGLang wird im Originalartikel für schnelles Serving empfohlen.
pip install sglangpython -m sglang.launch_server \
--model-path Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tp-size 4 \
--context-length 262144 \
--reasoning-parser qwen3Nach dem Start ist der OpenAI-kompatible API-Endpunkt:
http://localhost:8000/v1Methode 2: Bereitstellung mit vLLM
pip install vllmvllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--trust-remote-codeHinweis aus der offiziellen Dokumentation: Die aktuelle Hugging-Face-Modellkarte empfiehlt außerdem,
--language-model-onlymit vLLM zu verwenden, da die Modellarchitektur Definitionen visueller Komponenten enthält, während der Checkpoint Gewichte des Sprachmodells enthält. Wenn die Initialisierung von vLLM fehlschlägt, versuchen Sie, dieses Flag hinzuzufügen.
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--language-model-only \
--trust-remote-codeMethode 3: Lokale Inferenz mit Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
messages = [
{
"role": "system",
"content": "Du bist ein Sprach-Weltmodell, das eine Linux-Terminalumgebung simuliert. "
"Sage anhand des Befehls des Benutzers die Terminalausgabe voraus."
},
{
"role": "user",
"content": "Aktion: execute_bash\nBefehl: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)Methode 4: Aufruf über eine OpenAI-kompatible API
Diese Methode funktioniert, nachdem das Modell über SGLang oder vLLM bereitgestellt wurde.
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
messages = [
{
"role": "system",
"content": "Du bist ein Sprach-Weltmodell, das eine Linux-Terminalumgebung simuliert."
},
{
"role": "user",
"content": "Aktion: execute_bash\nBefehl: pwd"
}
]
response = client.chat.completions.create(
model="Qwen/Qwen-AgentWorld-35B-A3B",
messages=messages,
max_tokens=32768,
temperature=0.6,
)
print(response.choices[0].message.content)Best Practices
Empfohlenes Sampling:
temperature=0.6,top_p=0.95,top_k=20
Empfohlene Ausgabelänge: etwa 32,768 Tokens für die meisten langen Beobachtungen
Verwenden Sie die domänenspezifischen System-Prompts aus dem Verzeichnis
prompts/des Repositorys, um eine bessere Simulationsqualität zu erzielenHalten Sie die Kontextlänge nach Möglichkeit bei mindestens
128K; der Standardkontext des Modells beträgt256K
9. Evaluierungsworkflow für AgentWorldBench
Wenn Sie Ihr eigenes Weltmodell auf AgentWorldBench testen möchten, beschreibt der Originalartikel einen dreistufigen Workflow.
# 1. Evaluierungs-Repository klonen
git clone https://github.com/QwenLM/Qwen-AgentWorld.git
cd Qwen-AgentWorld
# 2. Evaluierungsdatensatz herunterladen
huggingface-cli download Qwen/AgentWorldBench --repo-type dataset --local-dir ./AgentWorldBench
# 3. Abhängigkeiten installieren
pip install openai
cd eval
# Schritt 1: Inferenz des Weltmodells
python eval.py infer \
--data-dir ../AgentWorldBench \
--model-base-url http://localhost:8000/v1 \
--model-name Qwen/Qwen-AgentWorld-35B-A3B \
--output-dir ./results
# Schritt 2: Bewertung durch LLM-Judge. Dies erfordert einen OpenAI-API-Schlüssel.
export OPENAI_API_KEY="your-api-key"
python eval.py judge \
--predictions ./results/predictions.jsonl \
--judge-base-url https://api.openai.com/v1 \
--judge-model gpt-5.2-2025-12-11 \
--output-dir ./results
# Schritt 3: Scores aggregieren
python eval.py score --predictions ./results/judged.jsonlJedes Testbeispiel enthält Ground-Truth-Beobachtungsdaten aus einer realen Umgebungsausführung. Der Benchmark bewertet die Fähigkeit zur Weltmodellierung in Bezug auf Format, Faktentreue, Konsistenz, Realismus und Qualität.
10. Vorschläge zur Feinabstimmung
Wenn Sie Qwen-AgentWorld für einen bestimmten Bereich anpassen möchten, empfiehlt der ursprüngliche Artikel drei gängige Frameworks zur Feinabstimmung.
Framework | Stärke | Geeignetes Szenario |
Hohe Integration mit ModelScope | Schnelle Experimente und Workflows im Alibaba-Ökosystem | |
Aktive Community und breite Unterstützung für Trainingsstrategien | Praktische technische Bereitstellung | |
Starke Speicheroptimierung | Feinabstimmung bei begrenzten Ressourcen |
11. Quellenhinweise und Bildhandhabung
Der ursprüngliche Artikel enthält mehrere Bilder zu Qwen-AgentWorld-Domänen und Benchmark-Ergebnissen. Diese wurden in den relevanten Abschnitten beibehalten.
CSDN-Plattformsymbole, Werbemodule, Autoren-Abonnementblöcke, QR-Codes, Belohnungsschaltflächen und nicht verwandte Empfehlungsbilder wurden gemäß den Veröffentlichungsanforderungen entfernt.
FAQ
Was ist Qwen-AgentWorld?
Qwen-AgentWorld ist ein Sprach-Weltmodell des Qwen-Teams. Es sagt den nächsten Umgebungszustand voraus, nachdem ein Agent eine Aktion ausgeführt hat, und ist daher nützlich für Agentensimulation, Training und Bewertung.
Ist Qwen-AgentWorld dasselbe wie ein normales Chatmodell?
Nein. Ein normales Chatmodell ist hauptsächlich für Gespräche und das Befolgen von Anweisungen optimiert. Qwen-AgentWorld wird als Umgebungssimulator trainiert, daher besteht sein Hauptanwendungsfall darin, Beobachtungen in Interaktionsumgebungen von Agenten vorherzusagen.
Welches Qwen-AgentWorld-Modell ist öffentlich verfügbar?
Offizielle Seiten führen Qwen-AgentWorld-35B-A3B als die öffentlich veröffentlichte Modellgewichtung auf. AgentWorldBench ist ebenfalls als Bewertungsbenchmark verfügbar. Das größere 397B-Modell erscheint in Benchmark-Tabellen, aber die öffentliche Modellveröffentlichung verweist hauptsächlich auf die 35B-A3B-Version.
Kann Qwen-AgentWorld mit vLLM bereitgestellt werden?
Ja. Die Hugging-Face-Modellkarte enthält ein Beispiel für die Bereitstellung mit vLLM. Wenn Initialisierungsprobleme auftreten, empfiehlt die offizielle Modellkarte, --language-model-only hinzuzufügen, da der Checkpoint Gewichte des Sprachmodells enthält.
Kann Qwen-AgentWorld mit SGLang bereitgestellt werden?
Ja. SGLang ist eine der empfohlenen Bereitstellungsoptionen und kann einen OpenAI-kompatiblen API-Endpunkt bereitstellen. Das Modell kann dann über lokale API-Anfragen aufgerufen werden.
Warum benötigt Qwen-AgentWorld ein langes Kontextfenster?
Die Simulation von Agentenumgebungen hängt oft von langen Interaktionsverläufen ab. Ein kürzeres Kontextfenster kann wichtige Zustandsinformationen verlieren, daher empfiehlt die offizielle Anleitung, nach Möglichkeit mindestens 128K Tokens beizubehalten.
Wofür wird AgentWorldBench verwendet?
AgentWorldBench ist der zusammen mit Qwen-AgentWorld veröffentlichte Benchmark. Er bewertet sprachbasierte Weltmodelle in sieben Domänen anhand von Dimensionen wie Format, Faktentreue, Konsistenz, Realismus und Qualität.
Ist Qwen-AgentWorld für den produktiven Einsatz geeignet?
Es kann für Forschung, Evaluierung, Simulation und interne Experimente nützlich sein. Für Produktionssysteme müssen Sie jedoch weiterhin Latenz, Hardwarekosten, Sicherheit, Zuverlässigkeit von Prompts und die Frage bewerten, ob simulierte Ergebnisse Ihrer realen Umgebung ausreichend genau entsprechen.
Verwandte Tools
Qwen-AgentWorld GitHub: Offizielles Repository für Qwen-AgentWorld-Code, Prompts und Evaluierungsworkflow.
Qwen-AgentWorld-35B-A3B auf Hugging Face: Offizielle Modellseite für die öffentlichen 35B-A3B-Gewichte.
AgentWorldBench: Offizieller Benchmark-Datensatz zur Evaluierung von Language World Models.
SGLang: Ein schnelles Serving-Framework für große Sprachmodelle.
vLLM: Eine Inferenz-Engine mit hohem Durchsatz für das Bereitstellen von LLMs.
Transformers: Hugging-Face-Bibliothek zum lokalen Laden von Modellen und für lokale Inferenz.
OpenAI Python SDK: Python-Client, der OpenAI-kompatible lokale Modellserver aufrufen kann.
ms-swift: ModelScopes Trainings- und Fine-Tuning-Framework für LLM-Workflows.
Verwandte Links
Technischer Bericht zu Qwen-AgentWorld: Das offizielle arXiv-Paper, das das Modell, den Benchmark und den Trainingsaufbau vorstellt.
Offizieller Qwen-AgentWorld-Blog: Qwens offizieller Veröffentlichungsbeitrag zum Projekt.
Qwen-AgentWorld-GitHub-Repository: Hauptquelle für Prompts, Evaluierungsskripte und Projektdokumentation.
Modellkarte zu Qwen-AgentWorld-35B-A3B: Offizielle Hugging-Face-Seite mit Beispielen für Bereitstellung und Inferenz.
AgentWorldBench-Datensatz: Offizieller Benchmark-Datensatz, der zur Modellevaluierung verwendet wird.
SGLang-Dokumentation: Dokumentation zum Bereitstellen von LLMs mit SGLang.
vLLM-Dokumentation: Dokumentation für hochdurchsatzfähige LLM-Inferenz und OpenAI-kompatible Bereitstellung.
LLaMA-Factory: Beliebtes Open-Source-Framework für Experimente zur Feinabstimmung und Bereitstellung von LLMs.


