
La respuesta breve: no, pero la dirección importa
DiffusionGemma no es una declaración de Google sobre la muerte de la predicción del siguiente token. Es mejor entenderlo como una señal experimental seria: Google está probando un camino diferente para la generación de texto con IA, en el que la velocidad, el paralelismo y los flujos de trabajo locales interactivos importan más que el ritmo familiar de un token a la vez de los LLM estándar.
Google describe DiffusionGemma como un modelo abierto experimental construido en torno a la difusión de texto. En lugar de producir texto estrictamente de izquierda a derecha, genera bloques de texto refinando un lienzo de tokens ruidosos o de marcador de posición. La promesa práctica es simple: si un modelo puede trabajar en muchas posiciones a la vez, puede usar el cómputo de la GPU de forma más eficiente y reducir la latencia de inferencia en algunos casos de uso.
Pero eso no significa que los modelos de lenguaje autorregresivos vayan a ser reemplazados mañana. La propia publicación de lanzamiento de Google es cuidadosa con respecto a la compensación. Afirma que los modelos estándar Gemma 4 siguen siendo la recomendación para aplicaciones que exigen la máxima calidad de producción. Esa frase importa. DiffusionGemma es un modelo de investigación y para desarrolladores enfocado en la velocidad, no un reemplazo universal del paradigma dominante de los LLM.
Por qué la predicción del siguiente token se convirtió en el estándar
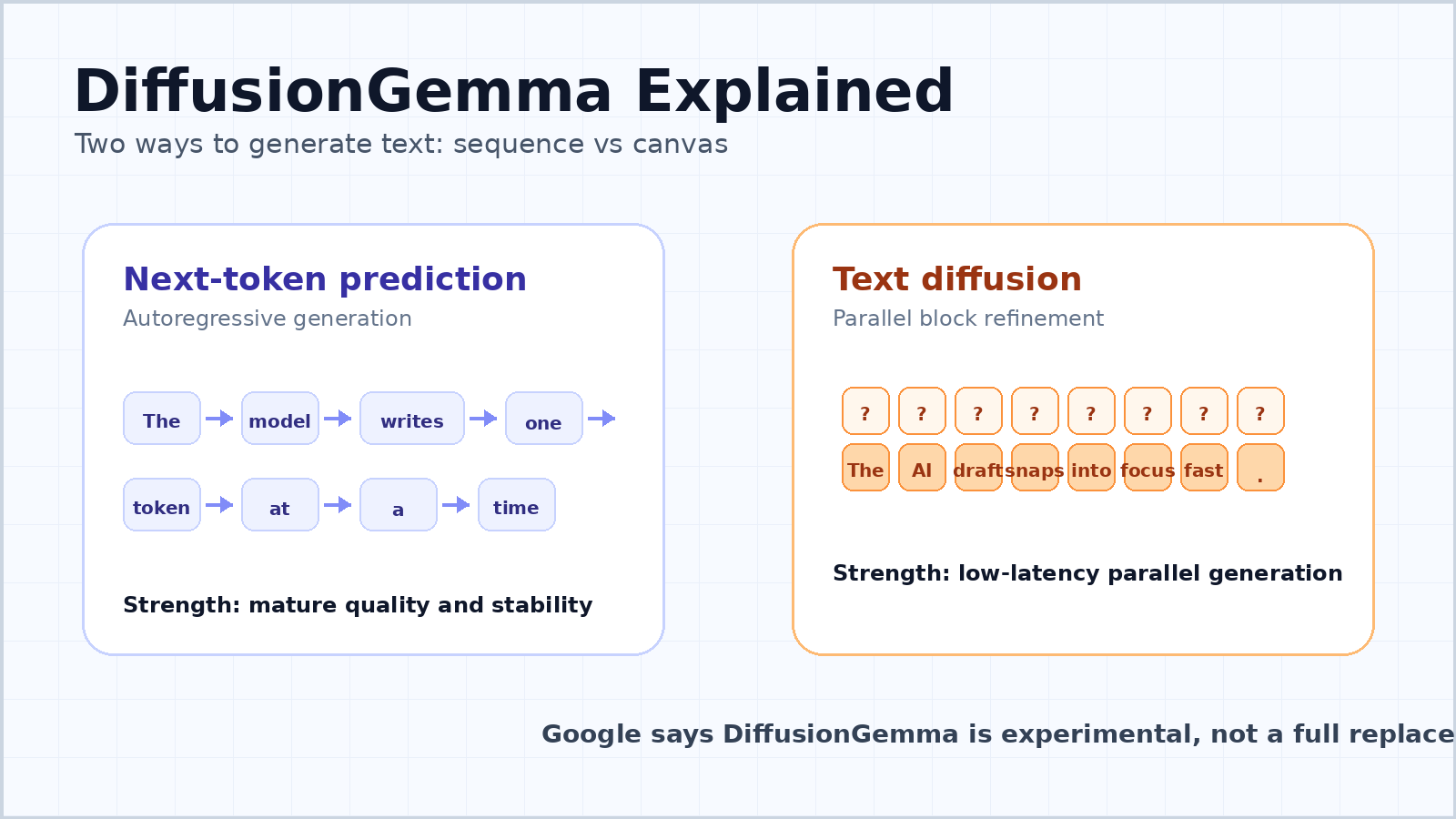
La mayoría de los chatbots y grandes modelos de lenguaje modernos son autorregresivos. Leen el prompt, luego predicen el siguiente token, después el token que sigue, y continúan hasta que la respuesta está completa. Este es el modelo mental simple detrás de la predicción del siguiente token.
La razón por la que se volvió dominante no es accidental. Los modelos autorregresivos son flexibles, estables y fáciles de escalar. Pueden generar texto de longitud variable, preservar la coherencia de izquierda a derecha y funcionar bien en chats, programación, traducción, resumen, razonamiento y uso de herramientas. El enfoque también se alinea de forma natural con cómo se desarrolla el lenguaje escrito.
La debilidad es la latencia. Un modelo token por token tiene una dependencia secuencial: el token 100 depende de los tokens 1 a 99, y el token 101 depende del token 100. Incluso cuando la GPU es potente, el modelo tiene que avanzar paso a paso por la secuencia. Para un usuario que hace una sola pregunta, gran parte del hardware puede quedar infrautilizado porque el modelo está esperando el movimiento de memoria y la decodificación secuencial.
Qué hace diferente DiffusionGemma
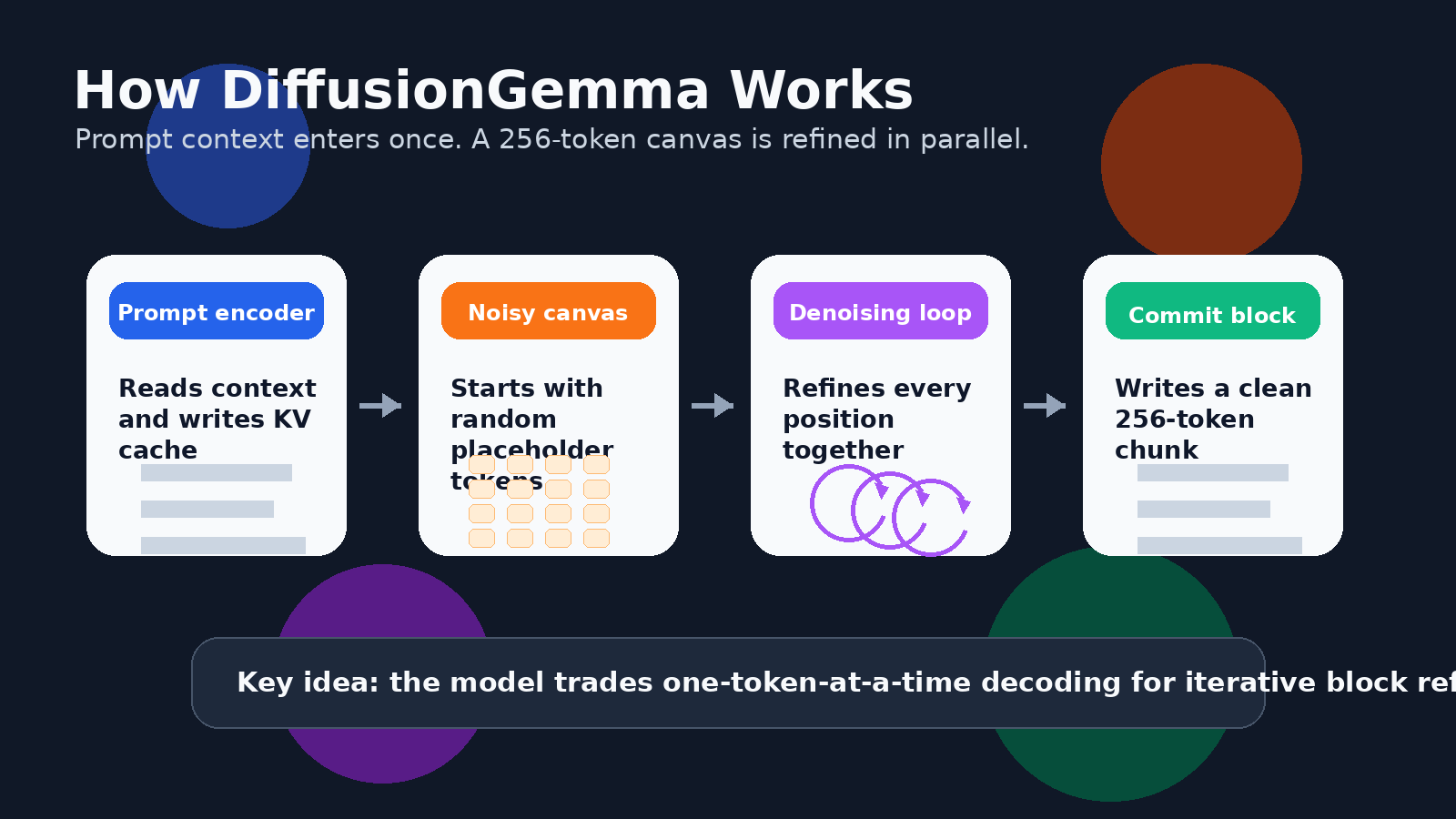
DiffusionGemma se inspira en los modelos de difusión, la familia de modelos generativos que se hizo famosa en la generación de imágenes y videos. En lugar de redactar la respuesta un token a la vez, un modelo de difusión comienza con ruido o incertidumbre y lo refina gradualmente hasta convertirlo en una salida coherente.
Para el texto, eso significa que el modelo puede trabajar en un bloque de tokens en paralelo. La guía para desarrolladores de Google describe un lienzo de 256 tokens. El modelo comienza con un lienzo de tokens aleatorios de marcador de posición y luego elimina el ruido repetidamente de todo el bloque. Las posiciones de tokens seguras se convierten en anclas, las posiciones inciertas se refinan de nuevo y el bloque va tomando forma gradualmente.
Esto no es lo mismo que generar un ensayo largo completo en una sola pasada. DiffusionGemma utiliza un enfoque autorregresivo por bloques para salidas más largas. Una vez que un bloque de 256 tokens está completamente refinado, se confirma en la caché KV y el modelo pasa al siguiente bloque. Así que sigue teniendo una estructura de izquierda a derecha entre bloques, pero dentro de cada bloque puede refinar muchos tokens a la vez.
Por qué puede ser más rápido
La cuestión de la velocidad tiene que ver con el cuello de botella del hardware. Los modelos autorregresivos tradicionales pueden verse limitados por el ancho de banda de memoria porque el modelo carga repetidamente los pesos mientras genera un token a la vez. DiffusionGemma intenta trasladar más trabajo hacia el cómputo proporcionando a la GPU una carga de trabajo paralela mayor dentro de cada bloque.
Google afirma que DiffusionGemma puede ofrecer una generación de tokens hasta cuatro veces más rápida en GPU dedicadas, con ejemplos que incluyen más de 1000 tokens por segundo en una sola NVIDIA H100 y más de 700 tokens por segundo en una RTX 5090. Esas cifras no son una promesa general para todas las tareas, dispositivos o tamaños de lote. Son una señal sobre un patrón de generación específico y favorable para el hardware.
Por eso DiffusionGemma resulta especialmente interesante para flujos de trabajo locales e interactivos. Si un usuario pide ediciones rápidas, completado de código, borradores estructurados o iteraciones veloces, la GPU puede tener capacidad de cómputo libre que un modelo autorregresivo no puede aprovechar por completo. Un modelo de lenguaje de difusión puede encajar mejor con ese tipo de carga de trabajo de bajo lote y sensible a la velocidad.
El papel de la atención bidireccional y la autocorrección
Una de las diferencias más importantes es la atención bidireccional. Durante la eliminación de ruido, los tokens en el lienzo pueden atender a otras posiciones del bloque, no solo a los tokens anteriores. Eso cambia la sensación de la generación. El modelo puede usar contexto de ambos lados de un tramo faltante o incierto.
Esto resulta especialmente útil para problemas de texto no lineales. Google señala la edición en línea, el completado de código, los grafos matemáticos e incluso la generación restringida al estilo Sudoku como ejemplos en los que las posiciones futuras importan. Un modelo autorregresivo estándar puede ser potente en muchas tareas, pero una vez que emite un token temprano, normalmente queda atado a él. La eliminación de ruido al estilo difusión crea espacio para la revisión antes de que el bloque se finalice.
Esta es también la razón por la que la expresión autocorrección aparece constantemente en torno a DiffusionGemma. El modelo no se limita a escribir. Evalúa repetidamente todo el lienzo, conserva las posiciones en las que tiene confianza, reemplaza las inciertas y refina el bloque hasta que converge.
Qué significa el diseño MoE de 26B
DiffusionGemma se basa en un diseño Mixture of Experts de 26B de la familia Gemma 4, con solo un subconjunto activo más pequeño utilizado durante la inferencia. La documentación de IA de Google lo describe como un modelo de 26B con aproximadamente 4B de parámetros activos, mientras que la guía para desarrolladores explica que el modelo está diseñado para ajustarse a límites de 18GB de VRAM cuando se cuantiza.
La idea clave es la eficiencia. Un modelo MoE disperso puede tener un gran número total de parámetros y, aun así, activar solo expertos seleccionados para un token o una tarea determinados. Eso puede mejorar la capacidad sin requerir que el modelo completo esté activo en cada paso.
Para los desarrolladores, esto importa porque DiffusionGemma no es solo una demostración de laboratorio. Se publica como un modelo de pesos abiertos bajo una licencia Apache 2.0, con documentación para vLLM, Hugging Face, Google Cloud Model Garden y otras rutas de despliegue. Google está invitando claramente al ecosistema a probar si la generación basada en difusión puede volverse práctica en aplicaciones reales.
Dónde tiene sentido DiffusionGemma

Los mejores casos de uso no son necesariamente la escritura premium de formato largo. Son tareas críticas en velocidad en las que el usuario se beneficia de una iteración rápida. La edición en línea es un ejemplo. En lugar de esperar a que un modelo reescriba un párrafo token por token, un modelo de difusión puede refinar rápidamente un tramo completo.
El completado de código es otro candidato sólido. Un desarrollador puede necesitar que un modelo rellene la parte central de una función o ajuste un bloque de código teniendo en cuenta lo que viene antes y después. La atención bidireccional es útil aquí porque el modelo puede razonar sobre ambos lados de la sección faltante.
La generación estructurada y restringida también es interesante. Si la salida tiene múltiples dependencias, como una tabla, un rompecabezas, una plantilla o un esquema formal, el refinamiento por bloques puede dar al modelo más margen para coordinarse entre posiciones. Por eso DiffusionGemma no se trata solo de ser más rápido. También apunta hacia un estilo de interacción diferente para la generación.
Dónde siguen ganando los modelos autorregresivos
La contrapartida es la calidad. Google afirma explícitamente que DiffusionGemma prioriza la velocidad y la generación de diseño en paralelo, y que su calidad general de salida es inferior a la de Gemma 4 estándar. Esa es la razón central por la que no debería describirse como un reemplazo directo de la predicción del siguiente token.
Los modelos autorregresivos todavía tienen ventajas importantes. Están profundamente optimizados para producción, son sólidos en muchas tareas de propósito general y cuentan con el respaldo de pilas de servicio maduras. También funcionan de forma natural para flujos conversacionales en los que el modelo extiende el texto en una secuencia constante.
El futuro realista probablemente no sea que un método de decodificación sustituya al otro. Es más probable que los sistemas de IA enruten diferentes tareas a distintas estrategias de generación. Los modelos autorregresivos pueden seguir siendo la opción predeterminada para chat general y razonamiento de alta calidad, mientras que los modelos de lenguaje de difusión pueden impulsar la edición rápida, la generación local, el completado de código y otras cargas de trabajo interactivas.
Qué deberían observar los desarrolladores a continuación
La gran pregunta es si los modelos de lenguaje de difusión pueden cerrar la brecha de calidad manteniendo al mismo tiempo la ventaja de latencia. La velocidad por sí sola no basta si la salida necesita demasiada corrección. Pero si la calidad mejora, la arquitectura podría volverse muy importante para la IA local, los asistentes de IDE, la edición de documentos y las interfaces en tiempo real.
La segunda cuestión es la infraestructura de servicio. El soporte de vLLM es importante porque los modelos de lenguaje de difusión requieren un comportamiento de decodificación diferente: atención bidireccional, eliminación iterativa de ruido, muestreo personalizado y lógica de confirmación a nivel de bloque. Si los marcos de inferencia facilitan esto, más desarrolladores experimentarán.
La tercera cuestión es el diseño de producto. Un modelo de texto de difusión no es solo un chatbot más rápido. Su interfaz natural puede parecerse más a un editor inteligente que revisa un lienzo, rellena huecos y mejora borradores en su lugar. Eso podría cambiar la forma en que los usuarios experimentan las herramientas de escritura y programación con IA.
Conclusión final
DiffusionGemma no significa que Google esté reemplazando hoy la predicción del siguiente token. Significa que Google está haciendo que la difusión de texto sea lo suficientemente práctica para que los desarrolladores la prueben en flujos de trabajo reales.
El cambio importante no es solo texto más rápido. Es la idea de que la generación de lenguaje no siempre tiene que parecerse a un modelo escribiendo de izquierda a derecha. A veces, la mejor interacción es un lienzo que se refina en paralelo.
Si ese patrón mejora, la generación de texto con IA podría volverse más rápida, más interactiva y más adecuada para dispositivos locales. Pero, por ahora, DiffusionGemma debe entenderse como un modelo abierto experimental con un mensaje muy claro: el futuro de la generación de lenguaje puede incluir más de una ruta de decodificación.
Comparación rápida
Pregunta | LLM autorregresivos | DiffusionGemma |
Patrón de generación | Predice el siguiente token de forma secuencial | Refina un lienzo de tokens en paralelo |
Fortaleza | Salidas de producción de alta calidad | Generación interactiva de baja latencia |
Flujo de contexto | Principalmente de izquierda a derecha durante la decodificación | Bidireccional dentro de cada lienzo de eliminación de ruido |
Mejor ajuste | Chat general, razonamiento, servicio maduro | Edición, relleno de código, flujos de trabajo locales rápidos |
Estado | Paradigma de producción dominante | Modelo abierto experimental |
CTA
Si estás creando productos de IA, no trates DiffusionGemma como un simple modelo de reemplazo. Trátalo como un nuevo patrón de generación que conviene probar allí donde la latencia de inferencia, la capacidad de respuesta local y la edición no lineal importan más.
Para los equipos que crean herramientas para desarrolladores, asistentes de escritura, flujos de trabajo de programación o experiencias de IA en el dispositivo, este es el tipo de arquitectura que merece evaluarse temprano con benchmarks.
Preguntas frecuentes
¿Qué es DiffusionGemma?
DiffusionGemma es el modelo abierto experimental de generación de texto de Google que utiliza difusión discreta para refinar bloques de tokens en paralelo en lugar de depender únicamente de la generación token por token.
¿Está Google reemplazando la predicción del siguiente token?
No. Google sigue recomendando Gemma 4 estándar para obtener la máxima calidad en producción. DiffusionGemma es experimental y está optimizado para flujos de trabajo donde la velocidad es crítica.
¿Por qué DiffusionGemma es más rápido?
Trabaja en paralelo sobre un lienzo de 256 tokens, desplazando más trabajo hacia el cómputo de la GPU en lugar de generar estrictamente un token a la vez.
¿Qué es un lienzo de 256 tokens?
Es un bloque de posiciones de tokens que el modelo inicializa, elimina el ruido, refina y luego confirma antes de pasar al siguiente bloque.
¿Quién debería probar DiffusionGemma?
Los desarrolladores que trabajan en inferencia local, edición en línea, completado de código, redacción rápida y otras herramientas de IA interactivas de baja latencia deberían prestar atención.
Herramientas relacionadas
- vLLM
- Colab
- Kaggle
Fuentes
- DeepMind


