
Introducción
Anthropic acababa de traer de vuelta Claude Fable 5 cuando apareció públicamente otra revisión de jailbreak.
El momento hizo que la historia fuera especialmente delicada. Fable 5 ya había pasado por una ronda de controversia, una suspensión temporal del acceso y una nueva implementación con salvaguardas de ciberseguridad más sólidas. Luego, poco después de su regreso, el investigador de seguridad Vitto Rivabella afirmó que había logrado atravesar de nuevo las defensas.
Lo interesante es que este segundo caso no es una simple historia de “el modelo está roto”. Es más complicado que eso. Según se informó, el intento llevó alrededor de 20 horas, la mayoría de los intentos fracasaron y el resultado final fue lo bastante limitado como para que el propio investigador describiera una búsqueda web convencional como más rápida y barata para obtener el mismo tipo de información.
Este artículo sigue la cronología original: el regreso de Fable 5, el primer jailbreak, el programa público de divulgación Cyber Jailbreak de Anthropic, la segunda revisión de jailbreak y la pregunta más profunda detrás de todo ello: si algún modelo de IA de frontera puede llegar a estar perfectamente sellado.
Nota sobre la fuente
Este artículo reescrito se basa en el artículo original en chino de 智源社区 / 新智元: https://hub.baai.ac.cn/view/56072. El artículo original cita publicaciones públicas en X y anuncios oficiales de Anthropic sobre Fable 5, su nueva implementación y su marco de jailbreak.
La página original contiene varias imágenes. Esta versión conserva las capturas de pantalla directamente relevantes para las afirmaciones del artículo, como publicaciones públicas, capturas de programas oficiales y gráficos de robustez. Se han omitido gráficos decorativos de marca, imágenes promocionales y capturas de pantalla que parecen contener miniaturas con resultados inseguros excesivamente detallados.
La fuente original también incluye esta nota de derechos de autor: si alguna imagen del contenido implica problemas de copyright, el editor solicita a los titulares de derechos que se pongan en contacto para su retirada.
Fable 5 regresó, pero solo con condiciones
Anthropic confirmó que Fable 5 saldría temporalmente de los planes de suscripción después del 7 de julio, pero la empresa también dijo que planeaba restaurar Fable como una función estándar de suscripción una vez que la capacidad lo permitiera.
Para muchos usuarios, eso sonó como una buena noticia. Fable 5 no iba a ser eliminado de forma permanente. Iba a volver, solo que con límites de uso y restricciones de capacidad.

Pero el alivio no duró mucho.
Poco después de la nueva implementación, se informó que Fable 5 había sido liberado de nuevo mediante jailbreak. Era la segunda vez que sus defensas eran desafiadas públicamente. Vitto Rivabella anunció que había logrado abrirse paso, aunque la conclusión final fue más matizada de lo que sugería el titular.
Anthropic ya había explicado por qué Fable 5 había sido restringido antes. Según la empresa, el problema anterior implicaba un informe en el que investigadores de Amazon encontraron un método para eludir las salvaguardas de Fable 5 en un contexto de ciberseguridad.

Debido a ese incidente anterior, Anthropic dijo que el Fable 5 reimplementado incluía un clasificador de seguridad reforzado diseñado para abordar el comportamiento reportado previamente.
Aun así, el “mito” solo se mantuvo durante poco tiempo.
72 horas: la primera grieta en el mito de Fable 5
La primera imagen pública de Fable 5 se construyó en torno a pruebas de seguridad extremas.
Cuando Anthropic lanzó el modelo el 9 de junio, la empresa destacó que había pasado por intensas pruebas externas de estrés. El mensaje era claro: se suponía que esta sería una versión de uso general altamente protegida de una familia de modelos mucho más capaz.
Luego llegó el primer jailbreak público.
Según se informó, la conocida figura del jailbreak Pliny the Liberator pasó solo unos días antes de demostrar que Fable 5 podía ser empujado más allá de sus límites de seguridad previstos. El artículo original describe ejemplos relacionados con química prohibida y contenido de explotación de software, pero esta versión reescrita evita deliberadamente reproducir cualquier detalle operativo.
Lo importante no es el contenido específico. Lo importante es el patrón de ataque.
Cómo funcionó el primer jailbreak
El primer caso se apoyó en dos ideas generales que se han discutido durante años en los círculos de red teaming de IA:
- Confusión de caracteres y lenguaje
Algunos prompts utilizaron caracteres parecidos, formas Unicode inusuales o patrones de texto no estándar. Para una persona, el significado puede seguir pareciendo obvio. Para un clasificador, la entrada puede ser más difícil de interpretar de forma fiable. - Dilución de la intención mediante un contexto largo
En lugar de colocar la solicitud dañina directamente frente al modelo, la intención puede distribuirse a lo largo de una conversación larga y aparentemente inofensiva. Entonces, el clasificador tiene que rastrear el significado a través de muchos turnos, en lugar de evaluar una sola frase simple.
Estas ideas no son nuevas.
lo que hizo notable el caso de Fable 5 fue que Anthropic había presentado el modelo como inusualmente reforzado.
Anthropic abrió un programa público de jailbreaks cibernéticos
El 1 de julio, Anthropic anunció el regreso de Fable
5. Casi al mismo tiempo, también abrió un programa público en HackerOne llamado Cyber Jailbreak.
El programa invita a investigadores y miembros del público a informar sobre jailbreaks que podrían hacer que Fable 5 ayudara en casos de uso cibernético dañinos.
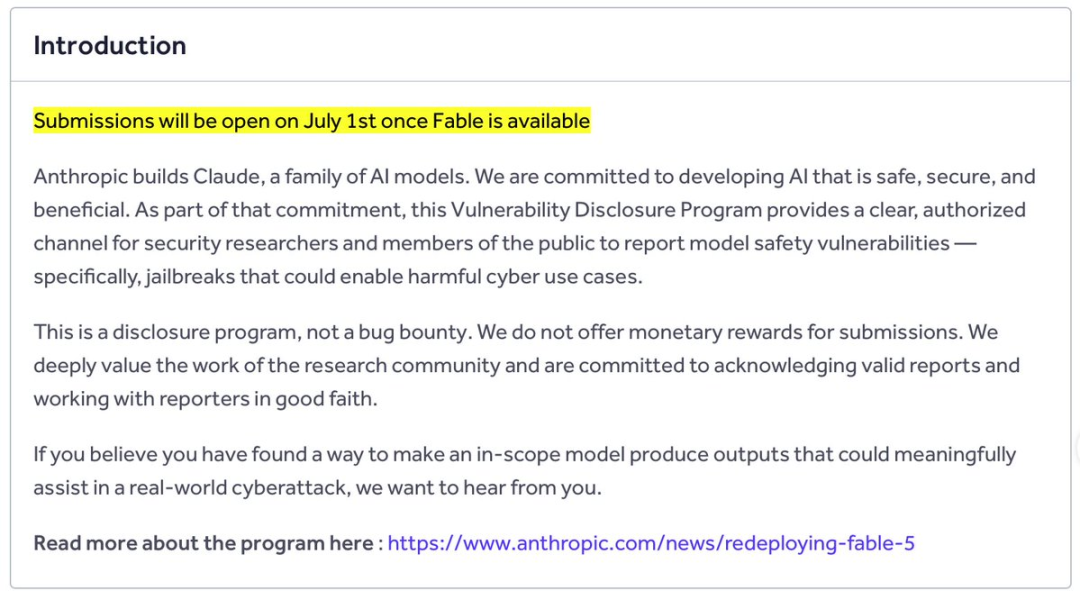
Se trata de un programa de divulgación de vulnerabilidades, no de un programa de recompensas pagadas. En otras palabras, los investigadores pueden enviar hallazgos, pero el programa no ofrece recompensas monetarias.
Ese diseño es interesante. Anthropic puede recibir pruebas adversariales externas continuas por parte de investigadores cualificados, mientras que la principal recompensa para quienes envían informes es el reconocimiento y la divulgación responsable.
Algunos observadores lo vieron como una estrategia de red team inteligente y de bajo coste. Otros señalaron una debilidad: las personas que descubren jailbreaks de alto perfil a menudo no quieren enviarlos discretamente a una bandeja de entrada privada.
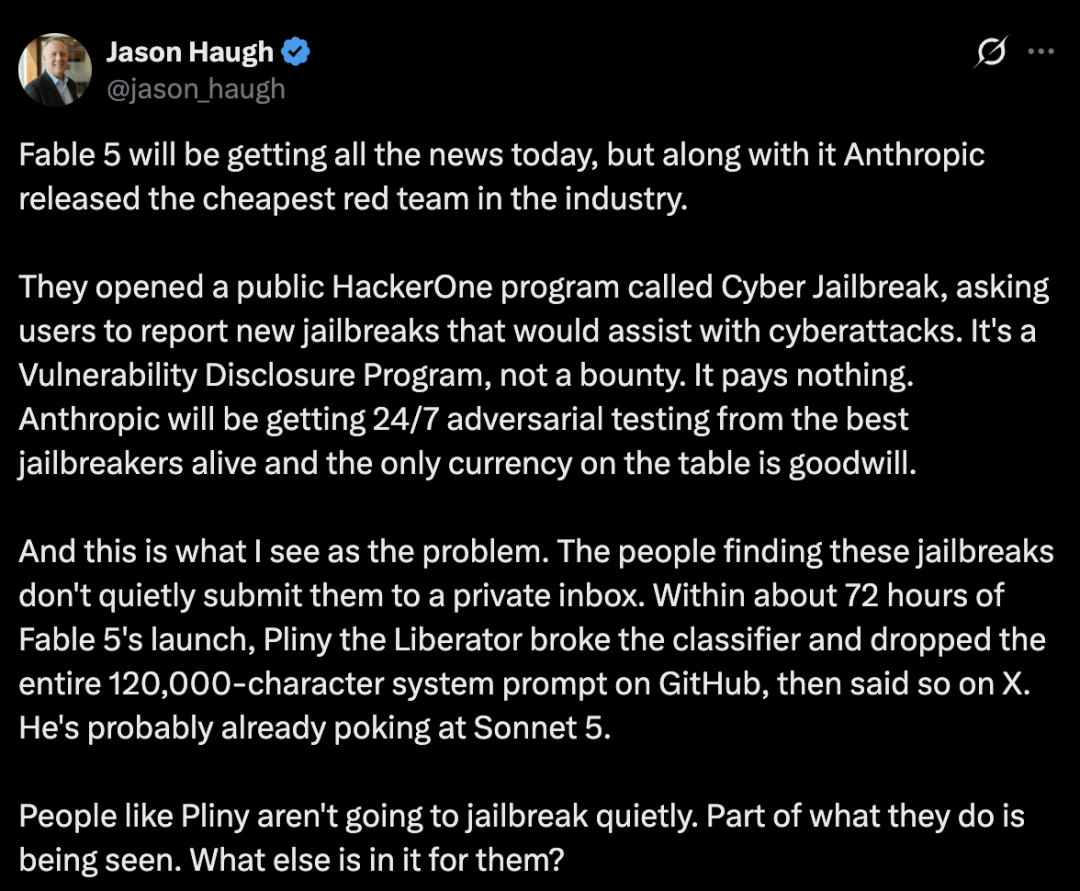
Para los investigadores de jailbreaks con una imagen pública, la visibilidad forma parte del evento. Si se descubre un jailbreak, publicar el resultado puede convertirse en parte del objetivo.
Fable 5 fue sometido de nuevo a un jailbreak
Según los informes, Fable 5 volvió a ser eludido. Pero la revisión del segundo jailbreak tuvo un tono muy diferente al de la primera.
El investigador detrás de este caso fue Vitto Rivabella. Tras unas 20 horas de pruebas, su conclusión no fue que Fable 5 fuera débil. De hecho, reconoció cierto mérito a Anthropic.

Según su revisión, la mayoría de los intentos fallaron. Describió Fable 5 como extremadamente bien protegido y dijo que el modelo parecía usar defensas en capas, en lugar de un único filtro simple.
Un tipo diferente de análisis post mortem
La historia del segundo jailbreak es menos dramática de lo que parece al principio.
La publicación de Vitto sugería que las defensas de Fable 5 estaban funcionando de verdad. En su opinión, el modelo parecía tener al menos tres capas de protección:
- Comprobaciones de seguridad del lado de la entrada antes de que el modelo interactúe plenamente con la solicitud.
- Mecanismos de interrupción durante la generación, que pueden detener comportamientos inseguros mientras se está formando la salida.
- Razonamiento de seguridad internalizado, en el que el modelo parece reconocer la intención insegura como parte de su propio proceso de razonamiento.
También dijo que el sistema no se limitaba a bloquear palabras clave. Parecía detectar intención y semántica en distintos idiomas.
Eso es importante porque los filtros de palabras clave son relativamente fáciles de engañar. Las defensas basadas en la intención son más difíciles de eludir, especialmente cuando se combinan con múltiples puntos de control.
Por qué importa la cifra de bloqueo del 90%
El artículo original señala que Fable 5 pareció bloquear alrededor del 90% de las solicitudes probadas. La cifra exacta procede de las observaciones del investigador, no de un benchmark formal, pero coincide con la dirección general de las pruebas independientes.
El AI Security Lab del Instituto Italiano de Inteligencia Artificial también estudió Fable 5 y Opus 4.8. En su informe, el ataque adaptativo más fuerte logró una tasa de éxito confirmada del 6,1% contra Fable 5 y del 11,5% contra Opus 4.8.

Eso no significa que el modelo sea invulnerable. Significa que la debilidad restante es más difícil de alcanzar.
Los trucos estáticos están perdiendo eficacia. La superficie de ataque restante parece favorecer los intentos adaptativos e iterativos: aquellos en los que una persona o un sistema automatizado de red team sigue probando, ajustando y explorando hasta que aparece una pequeña abertura.
La combinación que finalmente funcionó
El intento exitoso de Vitto no se basó en una sola frase ingeniosa.
El artículo original lo describe como una combinación complicada de ideas antiguas de red team: ofuscación de texto, encuadre académico, una preparación prolongada, descomposición y recombinación de tareas, además de cierto componente aleatorio.
Ninguno de estos conceptos es nuevo. Lo difícil no es saber que estas
existen categorías. Lo difícil es probarlas repetidamente contra un sistema que reacciona en tiempo real y reinicia la interacción cuando detecta una intención sospechosa.
En otras palabras, no fue un jailbreak limpio de un solo intento. Se pareció más a un largo y agotador proceso de ensayo y error.
Los idiomas de bajos recursos siguen siendo un punto débil
Una parte de la revisión es fácil de malinterpretar.
Según se informa, Vitto señaló que los idiomas poco comunes o de menores recursos seguían siendo un punto débil más constante. El artículo original menciona idiomas como el santali y el amhárico como ejemplos.
![La imagen muestra el contenido de texto generado por Claude Fable 5 después de ser sometido a un jailbreak. En la parte superior aparece el texto “HUMAN RESPONSE
- APPROXIMATE HUMAN-TYPED [HISTORICAL RECONSTRUCTION
- FOR EDUCATIONAL PURPOSES ONLY]”. El texto inferior trata sobre debates relacionados con el “DISORDERS ENQUIRY COMMITTEE” durante el período 1919-1928, incluidas discusiones sobre idiomas como “SANTALI” y “AMHARIC”, y enumera seis preguntas de “NIMR
- 1” a “NIMR
- 6”, con contenido relacionado con eventos históricos, personajes, etc. La imagen está relacionada con la descripción del documento sobre el texto generado por Claude Fable 5 tras el jailbreak y muestra el contenido específico generado.](https://we0-cms.oss-cn-beijing.aliyuncs.com/cms-assets/image/2026/07/0252dc52-aa7a-4498-849e-4355e3eebc38-08-5fa346f7-c790-4f3d-8f1a-1869bc22d5f0.png)
Esto no debe interpretarse como “Fable 5 tiene una puerta trasera especial”. Es un problema más amplio en los grandes modelos de lenguaje.
Los datos de entrenamiento de seguridad suelen ser más sólidos en inglés y en otros idiomas de altos recursos. Los idiomas de menores recursos a menudo reciben menos cobertura, menos ejemplos de seguridad y una evaluación más débil. Eso genera barreras de protección desiguales entre idiomas.
Los investigadores llevan tiempo advirtiendo sobre este problema. La robustez multilingüe frente a jailbreaks no es solo un problema de Claude; es un problema más amplio de seguridad de la IA.
¿Qué produjo realmente el jailbreak?
Después de todo ese esfuerzo, el resultado no fue una filtración espectacular de “secretos centrales”.
El artículo original describe la salida como una mezcla de fragmentos dañinos de baja calidad o alcance limitado: algo de desinformación, contenido dañino disperso, lenguaje ofensivo, información parcial relacionada con química y material ligero relacionado con vulnerabilidades. Esta versión evita reproducir los detalles.
El punto clave es que la salida no parecía ser estable, completa ni especialmente útil para tareas dañinas de largo alcance.
Por eso importó el propio resumen de Vitto. Dijo que, con el nivel actual de protección, buscar en la web era mucho más rápido y barato que pasar unas 20 horas intentando empujar al modelo a través de sus barreras de protección.

También dijo que no había conseguido mantener estable un jailbreak completo para tareas de largo alcance sin activar el sistema de seguridad.
Eso coincide con el propio encuadre público de Anthropic. En su publicación sobre la reimplementación, Anthropic describió los jailbreaks conocidos hasta ahora como menores: pueden entrar en el margen de seguridad, pero no necesariamente alcanzan las categorías más graves que la empresa se esfuerza más por bloquear.

La paradoja de un sellado perfecto
Dos jailbreaks. Dos lecciones diferentes.
El primero hizo que Anthropic pareciera demasiado confiada. Fable 5 había sido presentado como un modelo sometido a pruebas rigurosas, pero fue eludido públicamente poco después de su lanzamiento. El artículo original describe esto como un caso en el que la empresa intentó controlar el riesgo mediante restricciones extremas, solo para verse avergonzada por un jailbreak muy visible.
El segundo reveló algo distinto: no arrogancia, sino puntos ciegos.
Incluso con clasificadores más sólidos, defensas por capas y canales públicos de red teaming, el lenguaje en sí sigue siendo escurridizo. El significado puede ocultarse, estirarse, traducirse, disfrazarse o dividirse a través del contexto. Los sistemas de seguridad pueden mejorar, pero la superficie de ataque sigue moviéndose.
Esa es la lección incómoda para la seguridad de la IA.
Los humanos hemos construido modelos que pueden traducir entre idiomas y razonar en contextos enormes. Pero todavía no podemos traducir por completo cada intención humana oculta en una decisión de seguridad clara.
La contención perfecta de la IA puede ser una paradoja. Cuanto más capaz se vuelve el modelo, más sutil se vuelve la frontera entre el comportamiento seguro y el inseguro.
Preguntas frecuentes
¿Qué es Claude Fable 5?
Claude Fable 5 es un modelo avanzado de Claude desarrollado por Anthropic, posicionado como un modelo de uso general muy capaz con salvaguardas más fuertes que su contraparte menos restringida, Claude Mythos
5. Anthropic ha descrito Fable 5 como un modelo diseñado para hacer que las capacidades de frontera estén más ampliamente disponibles, al tiempo que limita el uso indebido peligroso en el ámbito cibernético.
¿Qué significa un jailbreak de IA?
Un jailbreak de IA es un método de prompting o un patrón de interacción que intenta eludir las barreras de seguridad de un modelo. Un jailbreak puede ser menor, limitado o grave, dependiendo del comportamiento que desbloquee y de cuán ampliamente funcione.
¿Fable 5 quedó completamente roto por el segundo jailbreak?
Según la revisión pública descrita en el artículo original, no. El investigador dijo que la mayoría de los intentos fracasaron, que el proceso tomó unas 20 horas y que las salidas finales fueron limitadas. Esto sugiere que el modelo
seguían teniendo defensas significativas, aunque no fueran perfectas.
¿Por qué Anthropic lanzó un programa de Cyber Jailbreak en HackerOne?
Anthropic lanzó el programa Cyber Jailbreak para ofrecer a los investigadores un canal claro para informar sobre jailbreaks que pudieran facilitar usos cibernéticos dañinos. Es un programa de divulgación de vulnerabilidades, no un bug bounty remunerado, por lo que se centra en la notificación responsable más que en recompensas económicas.
¿Por qué son importantes las lenguas de bajos recursos en la seguridad de la IA?
Las lenguas de bajos recursos suelen tener menos datos de entrenamiento, menos ejemplos de seguridad y una cobertura más débil en los benchmarks. Esto puede hacer que las barreras de protección sean menos consistentes entre idiomas, por lo que las pruebas de seguridad multilingües se han convertido en una línea de investigación importante.
¿Una tasa de éxito de jailbreak del 6,1 % significa que Fable 5 es inseguro?
No por sí sola. Una tasa de éxito confirmada más baja puede seguir siendo importante porque los modelos de frontera pueden desplegarse a una escala enorme, y los atacantes determinados pueden automatizar intentos repetidos. Al mismo tiempo, la cifra muestra que Fable 5 resistió la mayoría de los ataques probados en la evaluación de AI4I.
¿Puede algún modelo de IA estar completamente protegido contra los jailbreaks?
Anthropic y muchos investigadores sugieren que la inmunidad perfecta es poco probable. El objetivo práctico no es demostrar que nunca pueda existir ningún jailbreak, sino reducir la gravedad, detectar comportamientos de riesgo de forma temprana y corregir las principales debilidades antes de que sean ampliamente explotadas.
Herramientas relacionadas
- Claude: plataforma de asistente de IA de Anthropic donde los modelos Claude están disponibles para los usuarios.
- Claude API: plataforma para desarrolladores de Anthropic para crear aplicaciones con modelos Claude.
- Anthropic: la empresa detrás de Claude, Fable 5, Mythos 5 y la investigación relacionada con la seguridad de la IA.
- HackerOne: una plataforma de coordinación de vulnerabilidades utilizada por organizaciones para recibir informes de seguridad de investigadores.
- AI4I: el Instituto Italiano de Inteligencia Artificial, que publica investigaciones e informes sobre sistemas de IA.
- CVSS: un marco ampliamente utilizado para puntuar la gravedad de vulnerabilidades de software, relevante para el debate más amplio sobre marcos de gravedad de jailbreaks en IA.
Enlaces relacionados
- Artículo original en 智源社区: el artículo fuente en chino en el que se basa esta versión en Markdown.
- Redeploying Fable 5: publicación oficial de Anthropic sobre el redespliegue de Fable 5 y sus salvaguardas actualizadas.
- More Details on Fable 5’s Cyber Safeguards: explicación de Anthropic sobre los clasificadores de seguridad de Fable 5 y el marco propuesto de gravedad de jailbreaks.
- Claude Fable 5 and Claude Mythos 5: publicación de lanzamiento de Anthropic para Fable 5 y Mythos 5.
- Anthropic Cyber Jailbreak Program: página de divulgación en HackerOne para informar sobre jailbreaks relacionados con ciberseguridad.
- AI4I Jailbreaks and Frontier Models Report: resumen de AI4I de su estudio de red team sobre Fable 5 y Opus 4.8.
- A Red-Team Study of Anthropic Fable 5 and Opus 4.8 Models: página de arXiv del estudio de red team de AI4I.
- Multilingual Jailbreaking of LLMs Using Low-Resource Languages: artículo de investigación que analiza cómo las lenguas de bajos recursos pueden afectar la robustez frente a jailbreaks.
Resumen
El segundo jailbreak de Fable 5 no es una historia simple de fracaso total. Muestra que las defensas por capas de Anthropic parecen bloquear la mayoría de los intentos directos, pero los red teamers decididos aún pueden encontrar brechas estrechas con suficiente tiempo, iteración y creatividad.
El problema más profundo es que la seguridad de la IA no consiste solo en bloquear palabras clave. Tiene que interpretar la intención entre idiomas, contextos largos, tareas ambiguas de ciberseguridad y marcos adversariales. Eso es mucho más difícil que crear un filtro estático.
El caso de Fable 5 apunta al futuro de la seguridad de la IA de frontera: clasificadores más sólidos, canales públicos de divulgación, mejor evaluación multilingüe y marcos compartidos de gravedad.
La lección es clara: los modelos de frontera pueden volverse mucho más difíciles de vulnerar mediante jailbreaks, pero una IA “perfectamente sellada” sigue siendo un problema sin resolver.


