
Qwen-AgentWorld é um modelo de mundo linguístico lançado pela equipe Qwen para simular ambientes de agentes. Em vez de apenas responder a perguntas como um modelo de chat geral, ele foi projetado para prever o que um ambiente retornaria depois que um agente executa uma ação.
Isso o torna especialmente relevante para pesquisas em agentes de IA, aprendizado por reforço simulado, avaliação de benchmarks e experimentos locais envolvendo ambientes de terminal, engenharia de software, busca, MCP, web, sistema operacional e ambientes no estilo Android.
Este artigo é uma versão levemente reescrita e traduzida do artigo original em chinês. A estrutura, o fluxo técnico, os comandos, as tabelas e as ideias principais foram preservados, enquanto a linguagem foi ajustada para uma leitura mais fluida em inglês e para publicação com SEO.
Nota sobre a fonte: O artigo original foi publicado no CSDN e declara seguir a licença CC BY-SA 4.0. Fonte original: Guia completo de implantação do Qwen-AgentWorld: gratuito e de código aberto, desempenho superior ao GPT-5.4, em execução em 5 minutos. Nota de verificação: As páginas oficiais da Qwen confirmam o lançamento público dos pesos do modelo
Qwen-AgentWorld-35B-A3Be doAgentWorldBench. O maiorQwen-AgentWorld-397B-A17Bestá incluído nos resultados oficiais de benchmark, mas a página pública do modelo e o lançamento no GitHub apontam principalmente para os pesos do modelo 35B-A3B.
1. Contexto: por que precisamos de um modelo de mundo linguístico?
Nos últimos dois anos, os agentes de IA evoluíram rapidamente de simples assistentes de chat para ferramentas capazes de operar sites, executar comandos de terminal, controlar aplicativos móveis e concluir tarefas de engenharia de software.
Mas treinar um agente robusto é caro. Muitas vezes, isso exige grandes volumes de interação com ambientes reais, o que cria vários problemas práticos:
Criar e manter ambientes é trabalhoso.
A coleta de dados é lenta e difícil de escalar.
Ambientes reais apresentam riscos, especialmente ao testar casos de falha ou inserir perturbações controladas.
Um Modelo de Mundo Linguístico, ou LWM, é desenvolvido para resolver esse problema. A ideia é simples, mas poderosa: permitir que um modelo desempenhe o papel do ambiente. Dada uma ação do agente e o histórico de interação, o modelo prevê o próximo estado do ambiente.
Com essa configuração, os agentes podem ser treinados e avaliados em simulação, em vez de dependerem sempre de sistemas reais.
Em 24/06/2026, a equipe Qwen lançou o Qwen-AgentWorld, um modelo de mundo linguístico nativo que unifica sete domínios de interação de agentes em um único modelo. O benchmark complementar, AgentWorldBench, também foi lançado.
Recursos oficiais:
GitHub: QwenLM/Qwen-AgentWorld
2. Ideia central: O que o torna um modelo de mundo “nativo”?
A palavra nativo é importante aqui. O Qwen-AgentWorld não é apenas um LLM de propósito geral adaptado após o treinamento para imitar um ambiente. Seu objetivo de modelagem de mundo é incorporado ao processo de treinamento desde o início.
Dimensão de comparação | Abordagem tradicional | Qwen-AgentWorld |
Ponto de partida do treinamento | Ajustar finamente um LLM geral | Tratar a modelagem do ambiente como o objetivo desde o CPT |
Processo de treinamento | Geralmente apenas SFT ou RL | CPT → SFT → RL |
Conhecimento do ambiente | Adicionado por meio de dados extras ou adaptação | Internalizado durante o treinamento |
Um ou alguns domínios | Sete domínios em um único modelo |
Em outras palavras, o Qwen-AgentWorld não é apenas um modelo geral envolto em prompts. Ele é treinado desde as camadas inferiores do pipeline para prever o próximo estado de um ambiente.
Isso dá ao modelo uma compreensão mais estruturada da dinâmica do ambiente, especialmente ao simular longas trajetórias de interação.
3. Sete domínios: ambientes de texto e GUI em um único modelo
O Qwen-AgentWorld divide os cenários de interação de agentes em dois grandes grupos: ambientes baseados em texto e ambientes baseados em GUI.
┌──────────────────────────────────────────┐
│ Qwen-AgentWorld │
│ │
│ Ambientes de texto Ambientes GUI │
│ ┌──────────┐ ┌──────────────────┐ │
│ │ MCP │ │ Web │ │
│ │ Pesquisa│ │ SO │ │
│ │ Terminal│ │ Android │ │
│ │ SWE │ └──────────────────┘ │
│ └──────────┘ │
└──────────────────────────────────────────┘Domínio | Tipo | Descrição |
MCP | Texto | Chamadas de ferramentas e interações do Protocolo de Contexto do Modelo |
Pesquisa | Texto | Interação com mecanismos de busca e comportamento de recuperação |
Terminal | Texto | Execução de comandos no terminal Linux |
SWE | Tarefas de engenharia de software, como correções de código | |
Web | GUI | Interação com navegador e páginas da web |
SO | GUI | Interação com sistema operacional de desktop |
Android | GUI | Interação com aplicativos móveis e interfaces no estilo Android |
Para os três domínios de GUI, as observações são representadas como código renderizável em vez de quadros de pixels brutos. Isso permite que um modelo de mundo baseado em texto abranja ambientes visuais sem processar diretamente sequências completas de imagens.
O modelo foi treinado com mais de 10 milhões de trajetórias de interação do mundo real nos sete domínios.
4. Pipeline de treinamento em três estágios
O Qwen-AgentWorld usa um pipeline de treinamento conectado em três estágios: CPT → SFT → RL.
Estágio 1: CPT — Injetando conhecimento do ambiente
Durante o pré-treinamento contínuo, o modelo aprende a partir de trajetórias de interação em ambientes reais em larga escala. Esse estágio incorpora a dinâmica do ambiente aos pesos do modelo.
O artigo original também menciona uma máscara de perda informacional em nível de turno. O objetivo é identificar quais turnos de diálogo realmente carregam informações sobre o estado do ambiente e reduzir o ruído de turnos menos úteis.
Estágio 2: SFT — Ativando o raciocínio em cadeia de pensamento
O ajuste fino supervisionado transforma a previsão do próximo estado em um padrão de raciocínio no estilo cadeia de pensamento.
Em vez de produzir diretamente um resultado previsto, o modelo aprende a raciocinar sobre por que um estado deve mudar antes de gerar a próxima observação.
Estágio 3: RL — Refinando a fidelidade da simulação
O estágio de aprendizagem por reforço usa sinais de recompensa híbridos, incluindo o algoritmo GSPO, para melhorar a qualidade da saída.
A otimização se concentra em:
Correção do formato
Precisão factual
Consistência de contexto
Realismo
Qualidade geral da simulação
Comportamentos emergentes mencionados no artigo original: Segundo relatos, o Qwen-AgentWorld apresenta comportamento de autocorreção, prevenção de vazamento de informações em cenários de busca e raciocínio causal em múltiplas etapas para algumas previsões de saída de comandos.
5. Lista de modelos de código aberto
Lançamento | Parâmetros | Parâmetros ativados | Comprimento do contexto | Posicionamento |
Qwen-AgentWorld-35B-A3B | 35B | 3B | 256 mil tokens | Modelo aberto público e eficiente |
Qwen-AgentWorld-397B-A17B | 397B | 17B | Não está claramente listado na tabela original | Modelo de referência principal |
AgentWorldBench | — | — | — | Benchmark de avaliação |
Detalhes da arquitetura 35B-A3B
Modelo base: Qwen3.5-35B-A3B-Base
Tipo de modelo: Modelo de Linguagem Causal / Modelo de Mundo Linguístico
Estilo de arquitetura: atenção linear híbrida + MoE
Dimensão oculta: 2048
Camadas: 40 camadas
Disposição das camadas: grupos repetidos com componentes Gated DeltaNet, Gated Attention e MoE
Especialistas: 256 especialistas
Especialistas ativados: 8 especialistas roteados + 1 especialista compartilhado
Comprimento do contexto: 262.144 tokens
Contexto mínimo recomendado: 128K tokens para melhor qualidade de simulação de trajetórias longas
A documentação oficial do Hugging Face também observa que o modelo é compatível com Transformers, vLLM e SGLang.
6. Comparação de desempenho: resultados do AgentWorldBench
O AgentWorldBench avalia cada modelo em cinco dimensões: Formato, Factualidade, Consistência, Realismo e Qualidade. As pontuações são normalizadas para uma escala de 0 a 100, em que quanto maior, melhor.
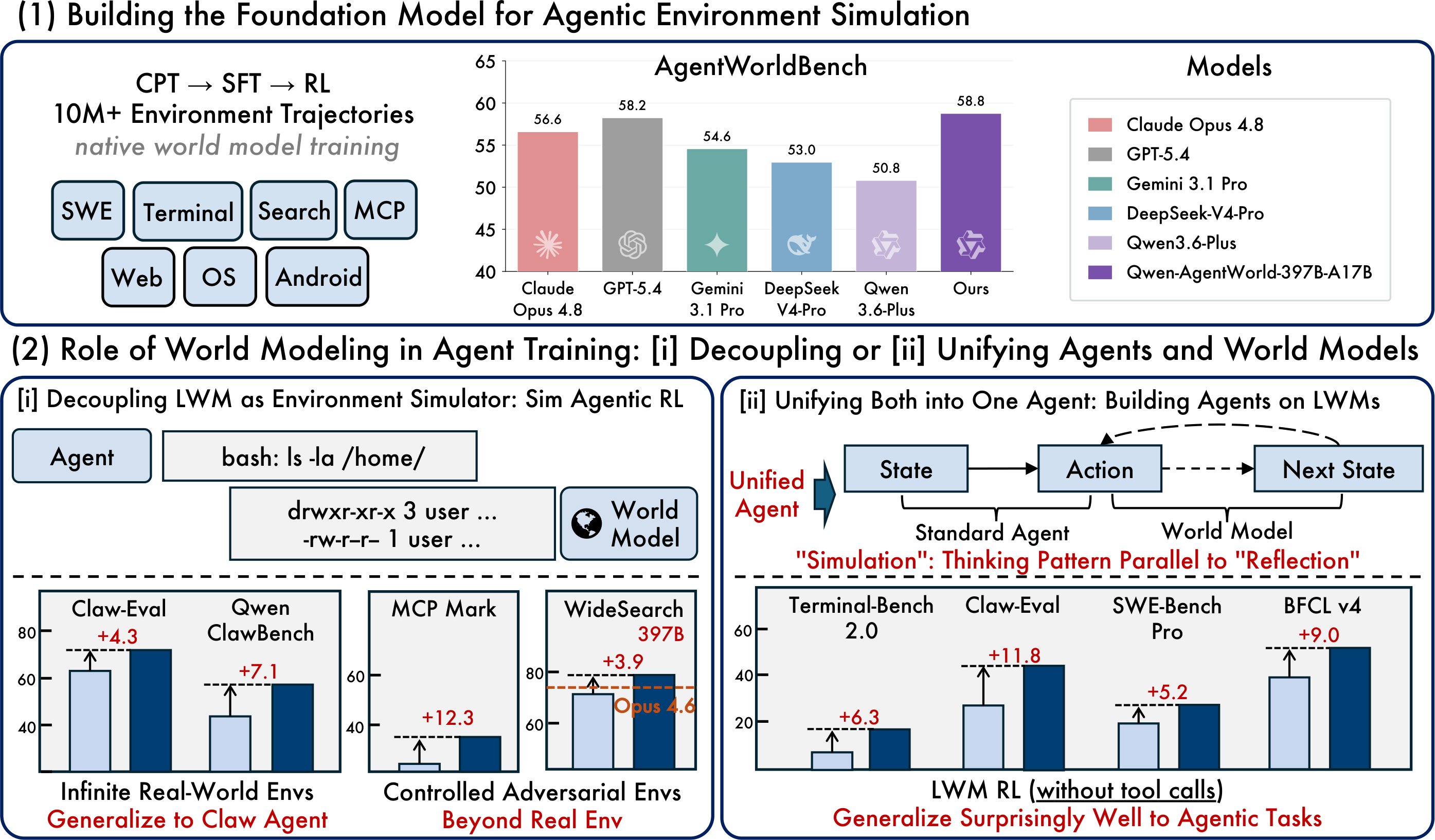
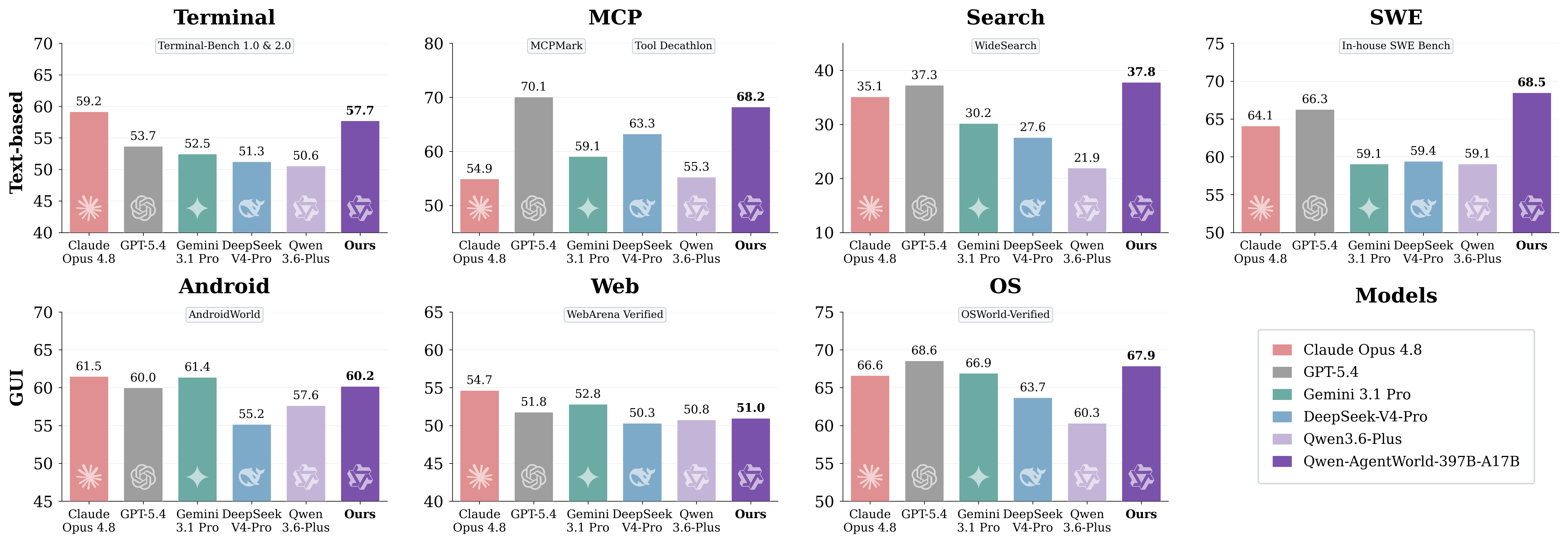
Classificação completa por pontuação geral
Modelo | MCP | Pesquisa | Terminal | SWE | Android | Web | SO | Geral |
Qwen-AgentWorld-397B-A17B | 68.24 | 37.82 | 57.73 | 68.49 | 60.20 | 50.98 | 67.89 | 58.71 |
GPT-5.4 | 70.10 | 37.26 | 53.69 | 66.29 | 60.00 | 51.80 | 68.58 | 58.25 |
Claude Opus 4.6 | 69.90 | 29.30 | 57.51 | 64.55 | 61.74 | 51.42 | 70.20 | 57.80 |
Claude Opus 4.8 | 54.93 | 35.14 | 59.18 | 64.10 | 61.50 | 54.66 | 66.62 | 56.59 |
Qwen-AgentWorld-35B-A3B | 64.79 | 36.69 | 53.96 | 65.63 | 58.17 | 49.55 | 65.92 | 56.39 |
Claude Sonnet 4.6 | 70.00 | 28.79 | 56.98 | 64.52 | 58.03 | 50.78 | 63.17 | 56.04 |
Qwen3.5-397B-A17B | 68.31 | 30.81 | 55.30 | 64.44 | 54.90 | 48.55 | 54.74 | |
Gemini 3.1 Pro | 59.07 | 30.21 | 52.47 | 59.07 | 61.40 | 52.83 | 66.92 | 54.57 |
DeepSeek-V4-Pro | 63.27 | 27.61 | 51.26 | 59.44 | 55.17 | 50.32 | 63.70 | 52.97 |
Qwen3.5-35B-A3B | 57.87 | 25.98 | 46.13 | 47.58 | 53.18 | 47.10 | 56.27 | 47.73 |
Principais conclusões do artigo original:
Qwen-AgentWorld-397B-A17Batinge uma pontuação geral de 58.71 e ocupa o primeiro lugar na tabela AgentWorldBench listada.Qwen-AgentWorld-35B-A3Bmelhora em +8.66 pontos em relação ao modelo baseQwen3.5-35B-A3B.
Nota prática: Trate os números de benchmark como dados de referência da configuração oficial do benchmark. Os resultados reais dependerão do hardware, do design do prompt, da estrutura de serviço, do comprimento do contexto e do ambiente simulado.
7. Quatro padrões de aplicação e resultados experimentais
Padrão 1: Expansão generalizável de ambientes OOD
O artigo original descreve o uso do Qwen-AgentWorld-397B-A17B para RL simulado em 4.000 ambientes OpenClaw fora da distribuição e, em seguida, o teste da generalização zero-shot em novos domínios.
Método de treinamento | Claw-Eval | QwenClawBench |
SFT base | 65.4 | 47.9 |
RL simulado com um simulador de modelo geral | 66.7 | 47.8 |
RL simulado com simulador Qwen-AgentWorld | 69.7 | 55.0 |
Melhoria | +4.3 | +7.1 |
Padrão 2: Simulação controlável — Perturbação direcionada por MCP
Perturbações controladas podem expor pontos fracos em um agente de forma mais eficaz do que o treinamento padrão em ambiente real.
Configuração | Decatlo de Ferramentas | MCPMark |
SFT base | 32.4 | 21.5 |
RL Sim sem controle | 31.5 | 24.6 |
RL Sim com controle | 36.1 | 33.8 |
Melhoria | +3.7 | +12.3 |
Padrão 3: Construção de Mundo Ficcional — Domínio de Busca
O experimento no domínio de busca usa um mundo de busca fictício, mas autoconsistente, para treinamento, e depois avalia a generalização em tarefas de busca reais.
Configuração | WideSearch F1 Item | WideSearch F1 Linha |
SFT base, 35B | 34.02 | 13.72 |
+ mundo ficcional Sim RL | 50.31 | 24.21 |
Melhoria | +16.29 | +10.49 |
Padrão 4: Modelo de Fundação de Agente — Transferência de Aquecimento LWM RL
O artigo também descreve o aquecimento de RL do LWM como uma forma de melhorar o desempenho do agente em tarefas posteriores sem ajuste fino adicional de RL nessas tarefas específicas.
Métrica | Terminal-Bench 2.0 | SWE-Bench Verified | SWE-Bench Pro | WideSearch F1 | Claw-Eval | BFCL v4 |
SFT base | 33.25 | 64.47 | 42.18 | 33.38 | 53.60 | 62.29 |
+ aquecimento LWM RL | 39.55 | 67.86 | 47.42 | 46.17 | 64.88 | 71.25 |
Melhoria | +6.30 | +3.39 | +5.24 | +12.79 | +11.28 | +8.96 |
Destaque: Os dados de aquecimento vêm de trajetórias de turno único e não agentivas, mas a melhoria é transferida para tarefas agentivas mais complexas de múltiplos turnos com chamada de ferramentas. Isso sugere que o conhecimento de modelagem do mundo pode ser transferido para além de seu formato de treinamento original.
8. Guia rápido de implantação
Método 1: Implantar com SGLang
O SGLang é recomendado no artigo original para servir rapidamente.
pip install sglangpython -m sglang.launch_server \
--model-path Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tp-size 4 \
--context-length 262144 \
--reasoning-parser qwen3Após a inicialização, o endpoint da API compatível com OpenAI é:
http://localhost:8000/v1Método 2: Implantar com vLLM
pip install vllmvllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--trust-remote-codeNota da documentação oficial: O cartão do modelo atual no Hugging Face também recomenda usar
--language-model-onlycom vLLM porque a arquitetura do modelo inclui definições de componentes visuais, enquanto o checkpoint contém pesos do modelo de linguagem. Se a inicialização do vLLM falhar, tente adicionar essa flag.
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--language-model-only \
--trust-remote-codeMétodo 3: Inferência local com Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
messages = [
{
"role": "system",
"content": "Você é um modelo de mundo linguístico que simula um ambiente de terminal Linux. "
"Dado o comando do usuário, preveja a saída do terminal."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)Método 4: Chamar por meio de uma API compatível com a OpenAI
Este método funciona depois de servir o modelo por meio do SGLang ou do vLLM.
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
messages = [
{
"role": "system",
"content": "Você é um modelo de mundo linguístico que simula um ambiente de terminal Linux."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: pwd"
}
]
response = client.chat.completions.create(
model="Qwen/Qwen-AgentWorld-35B-A3B",
messages=messages,
max_tokens=32768,
temperature=0.6,
)
print(response.choices[0].message.content)Boas práticas
Amostragem recomendada:
temperature=0.6,top_p=0.95,top_k=20
Tamanho de saída recomendado: cerca de 32,768 tokens para a maioria das observações longas
Use os prompts de sistema específicos do domínio do diretório
prompts/do repositório para obter melhor qualidade de simulaçãoMantenha o comprimento do contexto em pelo menos
128Kquando possível; o contexto padrão do modelo é256K
9. Fluxo de trabalho de avaliação do AgentWorldBench
Se você quiser testar seu próprio modelo de mundo no AgentWorldBench, o artigo original apresenta um fluxo de trabalho em três etapas.
# 1. Clonar o repositório de avaliação
git clone https://github.com/QwenLM/Qwen-AgentWorld.git
cd Qwen-AgentWorld
# 2. Baixar o conjunto de dados de avaliação
huggingface-cli download Qwen/AgentWorldBench --repo-type dataset --local-dir ./AgentWorldBench
# 3. Instalar dependências
pip install openai
cd eval
# Etapa 1: inferência do modelo de mundo
python eval.py infer \
--data-dir ../AgentWorldBench \
--model-base-url http://localhost:8000/v1 \
--model-name Qwen/Qwen-AgentWorld-35B-A3B \
--output-dir ./results
# Etapa 2: pontuação por juiz LLM. Isso requer uma chave de API da OpenAI.
export OPENAI_API_KEY="your-api-key"
python eval.py judge \
--predictions ./results/predictions.jsonl \
--judge-base-url https://api.openai.com/v1 \
--judge-model gpt-5.2-2025-12-11 \
--output-dir ./results
# Etapa 3: agregar pontuações
python eval.py score --predictions ./results/judged.jsonlCada amostra de teste inclui dados de observação de referência obtidos da execução em um ambiente real. O benchmark avalia a capacidade de modelagem de mundo em termos de formato, factualidade, consistência, realismo e qualidade.
10. Sugestões de ajuste fino
Se você quiser personalizar o Qwen-AgentWorld para um domínio específico, o artigo original recomenda três frameworks comuns de ajuste fino.
Framework | Ponto forte | Cenário adequado |
Alta integração com o ModelScope | Experimentos rápidos e fluxos de trabalho do ecossistema Alibaba | |
Comunidade ativa e amplo suporte a estratégias de treinamento | Implantação prática em engenharia | |
Forte otimização de memória | Ajuste fino com recursos limitados |
11. Notas sobre a fonte e tratamento de imagens
O artigo original inclui várias imagens relacionadas aos domínios do Qwen-AgentWorld e aos resultados de benchmarks. Elas foram mantidas nas seções relevantes.
Ícones da plataforma CSDN, módulos de promoção, blocos de assinatura do autor, códigos QR, botões de recompensa e imagens de recomendação não relacionadas foram removidos de acordo com os requisitos de publicação.
Perguntas frequentes
O que é o Qwen-AgentWorld?
Qwen-AgentWorld é um modelo de mundo linguístico da equipe Qwen. Ele prevê o próximo estado do ambiente depois que um agente executa uma ação, o que o torna útil para simulação, treinamento e avaliação de agentes.
O Qwen-AgentWorld é igual a um modelo de chat normal?
Não. Um modelo de chat normal é otimizado principalmente para conversação e seguimento de instruções. O Qwen-AgentWorld é treinado como um simulador de ambiente, portanto seu principal caso de uso é prever observações em ambientes de interação de agentes.
Qual modelo Qwen-AgentWorld está disponível publicamente?
As páginas oficiais listam Qwen-AgentWorld-35B-A3B como os pesos do modelo lançados publicamente. AgentWorldBench também está disponível como benchmark de avaliação. O modelo maior de 397B aparece em tabelas de benchmark, mas o lançamento público do modelo aponta principalmente para a versão 35B-A3B.
O Qwen-AgentWorld pode ser implantado com vLLM?
Sim. O cartão do modelo no Hugging Face inclui um exemplo de serviço com vLLM. Se você encontrar problemas de inicialização, o cartão oficial do modelo recomenda adicionar --language-model-only, porque o checkpoint contém pesos do modelo de linguagem.
O Qwen-AgentWorld pode ser implantado com SGLang?
Sim. O SGLang é uma das opções de serviço recomendadas e pode expor um endpoint de API compatível com OpenAI. O modelo pode então ser chamado por meio de solicitações de API locais.
Por que o Qwen-AgentWorld precisa de uma janela de contexto longa?
A simulação de ambientes de agentes geralmente depende de longos históricos de interação. Uma janela de contexto mais curta pode perder informações importantes de estado, portanto a orientação oficial recomenda manter pelo menos 128K tokens sempre que possível.
Para que o AgentWorldBench é usado?
O AgentWorldBench é o benchmark lançado com o Qwen-AgentWorld. Ele avalia modelos de mundo linguísticos em sete domínios usando dimensões como formato, factualidade, consistência, realismo e qualidade.
O Qwen-AgentWorld é adequado para uso em produção?
Ele pode ser útil para pesquisa, avaliação, simulação e experimentos internos. Para sistemas de produção, você ainda precisa avaliar latência, custo de hardware, segurança, confiabilidade dos prompts e se os resultados simulados correspondem de forma suficientemente próxima ao seu ambiente real.
Ferramentas relacionadas
GitHub do Qwen-AgentWorld: Repositório oficial do código, prompts e fluxo de trabalho de avaliação do Qwen-AgentWorld.
Qwen-AgentWorld-35B-A3B no Hugging Face: Página oficial do modelo para os pesos públicos 35B-A3B.
AgentWorldBench: Conjunto de dados de benchmark oficial para avaliar modelos de mundo linguísticos.
SGLang: Uma estrutura de serving rápida para grandes modelos de linguagem.
vLLM: Um mecanismo de inferência de alta vazão para servir LLMs.
Transformers: Biblioteca da Hugging Face para carregamento e inferência de modelos locais.
SDK Python da OpenAI: Cliente Python que pode chamar servidores de modelos locais compatíveis com a OpenAI.
ms-swift: framework de treinamento e ajuste fino da ModelScope para fluxos de trabalho de LLM.
Links relacionados
Relatório Técnico do Qwen-AgentWorld: O artigo oficial no arXiv que apresenta o modelo, o benchmark e a configuração de treinamento.
Blog Oficial do Qwen-AgentWorld: Publicação oficial de lançamento do projeto pela Qwen.
Repositório GitHub do Qwen-AgentWorld: Fonte principal para prompts, scripts de avaliação e documentação do projeto.
Cartão do Modelo Qwen-AgentWorld-35B-A3B: Página oficial no Hugging Face com exemplos de implantação e inferência.
Conjunto de Dados AgentWorldBench: Conjunto de dados oficial de benchmark usado para avaliação do modelo.
Documentação do SGLang: Documentação para disponibilizar LLMs com o SGLang.
Documentação do vLLM: Documentação para inferência de LLM de alto desempenho e disponibilização compatível com OpenAI.
LLaMA-Factory: Framework open-source popular para experimentos de ajuste fino e implantação de LLM.


