
Qwen-AgentWorld est un modèle de monde linguistique publié par l’équipe Qwen pour simuler des environnements d’agents. Au lieu de se contenter de répondre à des questions comme un modèle de chat généraliste, il est conçu pour prédire ce qu’un environnement renverrait après qu’un agent a effectué une action.
Cela le rend particulièrement pertinent pour la recherche sur les agents d’IA, l’apprentissage par renforcement simulé, l’évaluation de benchmarks et les expérimentations locales autour des environnements de terminal, de génie logiciel, de recherche, de MCP, web, de système d’exploitation et de type Android.
Cet article est une version légèrement réécrite et traduite de l’article chinois original. La structure, le déroulé technique, les commandes, les tableaux et les idées clés sont conservés, tandis que la langue a été adaptée pour une lecture plus fluide en anglais et une publication optimisée pour le SEO.
Note sur la source : L’article original a été publié sur CSDN et indique qu’il suit la licence CC BY-SA 4.0. Source originale : Guide complet de déploiement de Qwen-AgentWorld : gratuit et open source, performances supérieures à GPT-5.4, opérationnel en 5 minutes. Note de vérification : Les pages officielles de Qwen confirment la publication publique des poids du modèle
Qwen-AgentWorld-35B-A3Bet deAgentWorldBench. Le modèle plus grandQwen-AgentWorld-397B-A17Best inclus dans les résultats de benchmark officiels, mais la page publique du modèle et la publication GitHub renvoient principalement aux poids du modèle 35B-A3B.
1. Contexte : pourquoi avons-nous besoin d’un modèle de monde linguistique ?
Au cours des deux dernières années, les agents d’IA sont rapidement passés de simples assistants conversationnels à des outils capables d’utiliser des sites web, d’exécuter des commandes dans un terminal, de contrôler des applications mobiles et d’accomplir des tâches de génie logiciel.
Mais entraîner un agent performant coûte cher. Cela nécessite souvent de grands volumes d’interactions avec des environnements réels, ce qui crée plusieurs problèmes pratiques :
Créer et maintenir des environnements est fastidieux.
La collecte de données est lente et difficile à mettre à l’échelle.
Les environnements réels comportent des risques, en particulier lorsqu’il s’agit de tester des cas d’échec ou d’injecter des perturbations contrôlées.
Un Language World Model, ou LWM, est conçu pour résoudre ce problème. L’idée est simple mais puissante : laisser un modèle jouer le rôle de l’environnement. À partir d’une action de l’agent et de l’historique des interactions, le modèle prédit l’état suivant de l’environnement.
Avec cette configuration, les agents peuvent être entraînés et évalués en simulation au lieu de dépendre constamment de systèmes réels.
Le 24/06/2026, l’équipe Qwen a publié Qwen-AgentWorld, un modèle de monde linguistique natif qui unifie sept domaines d’interaction d’agents dans un seul modèle. Le benchmark associé, AgentWorldBench, a également été publié.
Ressources officielles :
GitHub : QwenLM/Qwen-AgentWorld
2. Idée centrale : qu’est-ce qui en fait un modèle du monde « natif » ?
Le mot natif est important ici. Qwen-AgentWorld n’est pas simplement un LLM à usage général adapté après l’entraînement pour imiter un environnement. Son objectif de modélisation du monde est intégré au processus d’entraînement dès le départ.
Dimension de comparaison | Approche traditionnelle | Qwen-AgentWorld |
Point de départ de l’entraînement | Ajuster finement un LLM généraliste | Considérer la modélisation de l’environnement comme l’objectif dès le CPT |
Processus d’entraînement | Généralement uniquement SFT ou RL | CPT → SFT → RL |
Connaissance de l’environnement | Ajoutée via des données supplémentaires ou une adaptation | Internalisée pendant l’entraînement |
Couverture des domaines | Un ou quelques domaines | Sept domaines dans un seul modèle |
Autrement dit, Qwen-AgentWorld n’est pas simplement un modèle général enveloppé dans des prompts. Il est entraîné dès les couches inférieures du pipeline à prédire l’état suivant d’un environnement.
Cela donne au modèle une compréhension plus structurée de la dynamique des environnements, en particulier lors de la simulation de longues trajectoires d’interaction.
3. Sept domaines : environnements textuels et graphiques dans un seul modèle
Qwen-AgentWorld divise les scénarios d’interaction des agents en deux grands groupes : les environnements textuels et les environnements graphiques.
┌──────────────────────────────────────────┐
│ Qwen-AgentWorld │
│ │
│ Environnements textuels Environnements graphiques │
│ ┌──────────┐ ┌──────────────────┐ │
│ │ MCP │ │ Web │ │
│ │ Recherche│ │ OS │ │
│ │ Terminal │ │ Android │ │
│ │ SWE │ └──────────────────┘ │
│ └──────────┘ │
└──────────────────────────────────────────┘Domaine | Type | Description |
MCP | Texte | Appels d’outils et interactions avec le Model Context Protocol |
Recherche | Texte | Interaction avec les moteurs de recherche et comportement de récupération |
Terminal | Texte | Exécution de commandes dans le terminal Linux |
SWE | Texte |
Tâches de génie logiciel, telles que les corrections de code
Web
Interface graphique
Interaction avec le navigateur et les pages web
OS
Interface graphique
Interaction avec le système d’exploitation de bureau
Android
Interface graphique
Interaction avec les applications mobiles et les interfaces utilisateur de type Android
Pour les trois domaines d’interface graphique, les observations sont représentées sous forme de code pouvant être rendu plutôt que d’images brutes en pixels. Cela permet à un modèle du monde textuel de couvrir des environnements visuels sans traiter directement des séquences complètes d’images.
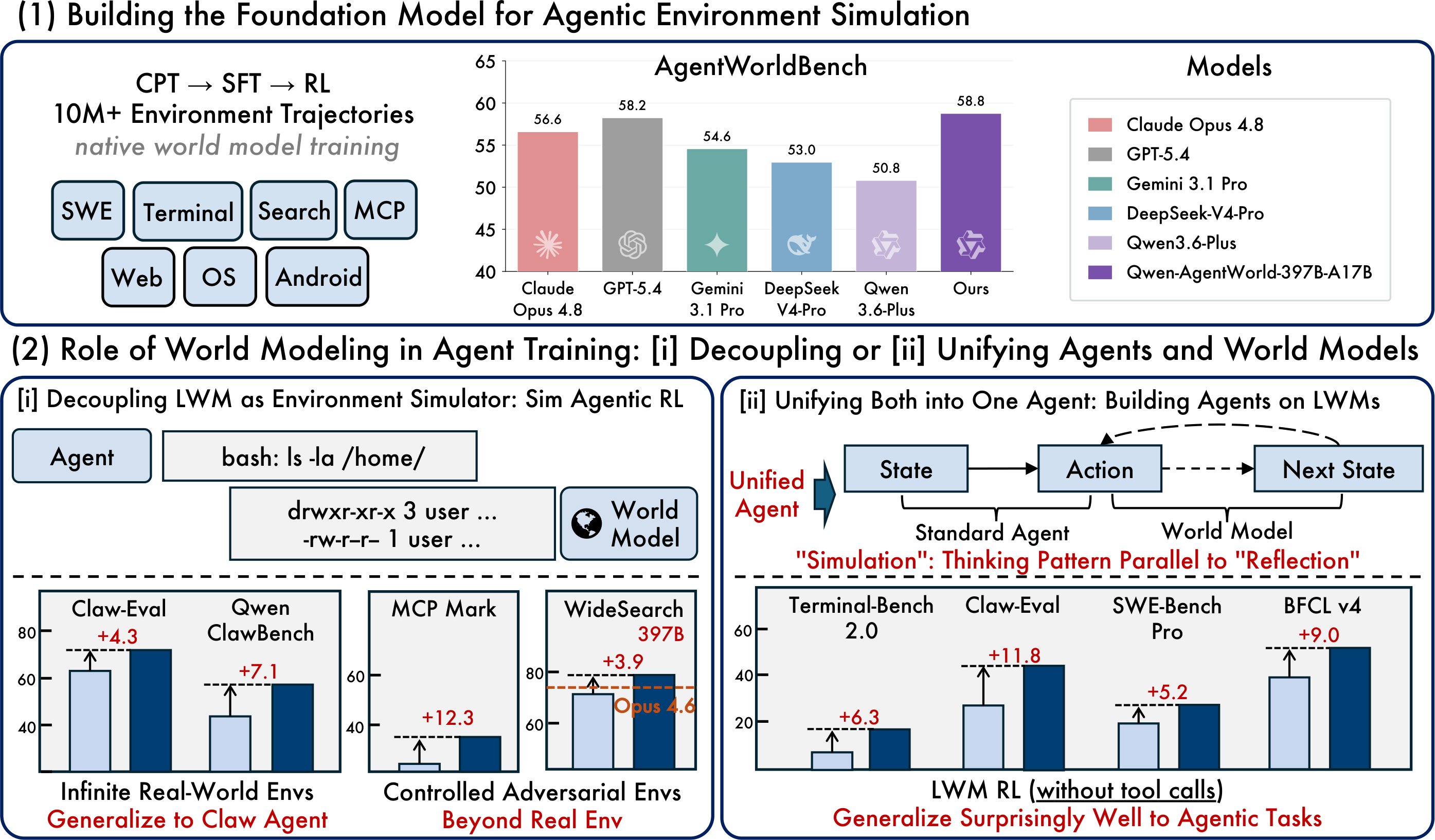
Le modèle a été entraîné sur plus de 10 millions de trajectoires d’interaction réelles dans les sept domaines.
4. Pipeline d’entraînement en trois étapes
Qwen-AgentWorld utilise un pipeline d’entraînement connecté en trois étapes : CPT → SFT → RL.
Étape 1 : CPT — Injection de connaissances sur l’environnement
Lors du pré-entraînement continu, le modèle apprend à partir de trajectoires d’interaction avec des environnements réels à grande échelle. Cette étape intègre la dynamique de l’environnement dans les poids du modèle.
L’article original mentionne également un masque de perte informationnel au niveau des tours de dialogue. L’objectif est d’identifier quels tours de dialogue véhiculent réellement des informations sur l’état de l’environnement et de réduire le bruit provenant des tours moins utiles.
Étape 2 : SFT — Activation du raisonnement en chaîne de pensée
Le réglage fin supervisé transforme la prédiction de l’état suivant en un schéma de raisonnement de type chaîne de pensée.
Au lieu de produire directement un résultat prédit, le modèle apprend à raisonner sur les raisons pour lesquelles un état devrait changer avant de générer l’observation suivante.
Étape 3 : RL — Amélioration de la fidélité de simulation
L’étape d’apprentissage par renforcement utilise des signaux de récompense hybrides, notamment l’algorithme GSPO, afin d’améliorer la qualité des sorties.
L’optimisation se concentre sur :
La correction du format
L’exactitude factuelle
Cohérence du contexte
Réalisme
Qualité globale de la simulation
Comportements émergents mentionnés dans l’article original : Qwen-AgentWorld présenterait un comportement d’auto-correction, une prévention des fuites d’informations dans les scénarios de recherche et un raisonnement causal en plusieurs étapes pour certaines prédictions de sorties de commandes.
5. Liste des modèles open source
Version | Paramètres | Paramètres activés | Longueur du contexte | Positionnement |
Qwen-AgentWorld-35B-A3B | 35B | 3B | 256K jetons | Modèle ouvert public et efficace |
Qwen-AgentWorld-397B-A17B | 397B | 17B | Pas clairement indiqué dans le tableau d’origine | Modèle de référence phare |
AgentWorldBench | — | — | — | Benchmark d’évaluation |
Détails de l’architecture 35B-A3B
Modèle de base : Qwen3.5-35B-A3B-Base
Type de modèle : Modèle de langage causal / Modèle de monde linguistique
Style d’architecture : Attention linéaire hybride + MoE
Dimension cachée : 2048
Couches : 40 couches
Disposition des couches : groupes répétés avec des composants Gated DeltaNet, Gated Attention et MoE
Experts : 256 experts
Experts activés : 8 experts routés + 1 expert partagé
Longueur du contexte : 262 144 tokens
Contexte minimal recommandé : 128K tokens pour une meilleure qualité de simulation de longues trajectoires
La documentation officielle de Hugging Face indique également que le modèle est compatible avec Transformers, vLLM et SGLang.
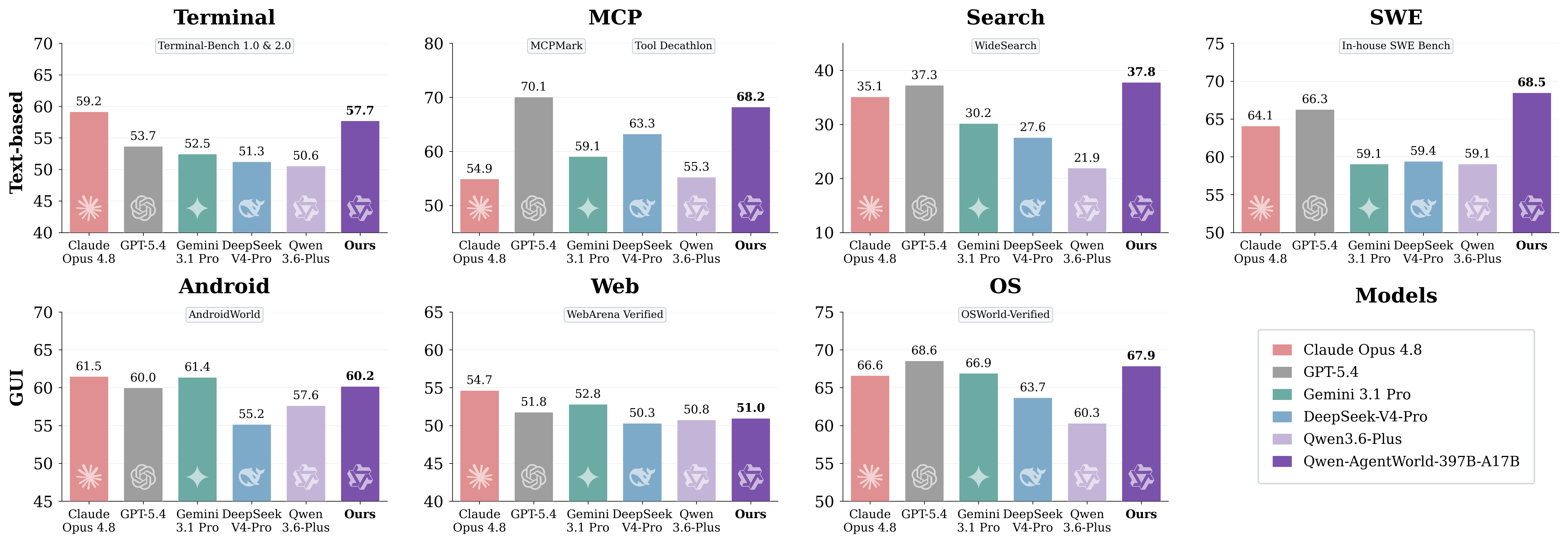
6. Comparaison des performances : résultats d’AgentWorldBench
AgentWorldBench évalue chaque modèle selon cinq dimensions : Format, Factualité, Cohérence, Réalisme et Qualité. Les scores sont normalisés sur une échelle de 0 à 100, où un score plus élevé est meilleur.
Classement complet par score global
Modèle | MCP | Recherche | Terminal | SWE | Android | Web | SE | Global |
Qwen-AgentWorld-397B-A17B | 68.24 | 37.82 | 57.73 | 68.49 | 60.20 | 50.98 | 67.89 | 58.71 |
GPT-5.4 | 70.10 | 37.26 | 53.69 | 66.29 | 60.00 | 51.80 | 68.58 | 58.25 |
Claude Opus 4.6 | 69.90 | 29.30 | 57.51 | 64.55 | 61.74 | 51.42 | 70.20 | 57.80 |
Claude Opus 4.8 | 54.93 | 35.14 | 59.18 | 64.10 | 61.50 | 54.66 | 66.62 | 56.59 |
Qwen-AgentWorld-35B-A3B | 64.79 | 36.69 | 53.96 | 65.63 | 58.17 | 49.55 | 65.92 | 56.39 |
Claude Sonnet 4.6 | 70.00 | 28.79 | 56.98 | 64.52 | 58.03 | 50.78 | 63.17 | 56.04 |
Qwen3.5-397B-A17B | 68.31 | 30.81 | 55.30 | 64.44 | 54.90 | 48.55 | 54.74 | |
Gemini 3.1 Pro | 59.07 | 30.21 | 52.47 | 59.07 | 61.40 | 52.83 | 66.92 | 54.57 |
DeepSeek-V4-Pro | 63.27 | 27.61 | 51.26 | 59.44 | 55.17 | 50.32 | 63.70 | 52.97 |
Qwen3.5-35B-A3B | 57.87 | 25.98 | 46.13 | 47.58 | 53.18 | 47.10 | 56.27 | 47.73 |
Principaux enseignements de l’article original :
Qwen-AgentWorld-397B-A17Batteint un score global de 58.71 et se classe premier dans le tableau AgentWorldBench présenté.Qwen-AgentWorld-35B-A3Bprogresse de +8.66 points par rapport au modèle de baseQwen3.5-35B-A3B.
Note pratique : Considérez les scores de référence comme des données indicatives issues de la configuration officielle du benchmark. Les résultats réels dépendront du matériel, de la conception des prompts, du framework de déploiement, de la longueur du contexte et de l’environnement simulé.
7. Quatre schémas d’application et résultats expérimentaux
Schéma 1 : extension généralisable à des environnements OOD
L’article original décrit l’utilisation de Qwen-AgentWorld-397B-A17B pour l’apprentissage par renforcement simulé dans 4 000 environnements OpenClaw hors distribution, puis l’évaluation de la généralisation zéro-shot dans de nouveaux domaines.
Méthode d’entraînement | Claw-Eval | QwenClawBench |
SFT de base | 65.4 | 47.9 |
RL simulé avec un simulateur de modèle général | 66.7 | 47.8 |
RL simulé avec le simulateur Qwen-AgentWorld | 69.7 | 55.0 |
Amélioration | +4.3 | +7.1 |
Modèle 2 : Simulation contrôlable — Perturbation ciblée par MCP
Les perturbations contrôlées peuvent révéler les points faibles d’un agent plus efficacement que l’entraînement standard en environnement réel.
Configuration | Tool Decathlon | MCPMark |
SFT de base | 32.4 | 21.5 |
RL sim. sans contrôle | 31.5 | 24.6 |
RL sim. avec contrôle | 36.1 | 33.8 |
Amélioration | +3.7 | +12.3 |
Modèle 3 : Construction d’un monde fictionnel — Domaine de recherche
L’expérience du domaine de recherche utilise un monde de recherche fictionnel mais cohérent en interne pour l’entraînement, puis évalue la généralisation sur des tâches de recherche réelles.
Configuration | WideSearch F1 élément | WideSearch F1 ligne |
SFT de base, 35B | 34.02 | 13.72 |
+ RL simulé dans un monde fictionnel | 50.31 | 24.21 |
Amélioration | +16.29 | +10.49 |
Modèle 4 : Modèle fondamental d’agent — Transfert de préchauffage RL LWM
L’article décrit également le préchauffage RL de LWM comme un moyen d’améliorer les performances de l’agent en aval sans réglage fin RL supplémentaire sur ces tâches spécifiques.
Indicateur | Terminal-Bench 2.0 | SWE-Bench Verified | SWE-Bench Pro | WideSearch F1 | Claw-Eval | BFCL v4 |
SFT de base | 33.25 | 64.47 | 42.18 | 33.38 | 53.60 | 62.29 |
+ échauffement RL LWM | 39.55 | 67.86 | 47.42 | 46.17 | 64.88 | 71.25 |
Amélioration | +6.30 | +3.39 | +5.24 | +12.79 | +11.28 | +8.96 |
Point clé : Les données d’échauffement proviennent de trajectoires à tour unique et non agentiques, mais l’amélioration se transfère à des tâches d’agents plus complexes, multi-tours et faisant appel à des outils. Cela suggère que les connaissances de modélisation du monde peuvent se transférer au-delà de leur format d’entraînement initial.
8. Guide de déploiement rapide
Méthode 1 : Déployer avec SGLang
SGLang est recommandé dans l’article original pour un service rapide.
pip install sglangpython -m sglang.launch_server \
--model-path Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tp-size 4 \
--context-length 262144 \
--reasoning-parser qwen3Après le démarrage, le point de terminaison de l’API compatible avec OpenAI est :
http://localhost:8000/v1Méthode 2 : Déployer avec vLLM
pip install vllmvllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--trust-remote-codeNote de la documentation officielle : La fiche de modèle Hugging Face actuelle recommande également d’utiliser
--language-model-onlyavec vLLM, car l’architecture du modèle inclut des définitions de composants visuels tandis que le checkpoint contient les poids du modèle de langage. Si l’initialisation de vLLM échoue, essayez d’ajouter cet indicateur.
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--language-model-only \
--trust-remote-codeMéthode 3 : Inférence locale avec Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
messages = [
{
"role": "system",
"content": "Vous êtes un modèle de monde linguistique simulant un environnement de terminal Linux. "
"Étant donné la commande de l’utilisateur, prédisez la sortie du terminal."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)Méthode 4 : appel via une API compatible avec OpenAI
Cette méthode fonctionne après avoir servi le modèle via SGLang ou vLLM.
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
messages = [
{
"role": "system",
"content": "Vous êtes un modèle de monde linguistique simulant un environnement de terminal Linux."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: pwd"
}
]
response = client.chat.completions.create(
model="Qwen/Qwen-AgentWorld-35B-A3B",
messages=messages,
max_tokens=32768,
temperature=0.6,
)
print(response.choices[0].message.content)Bonnes pratiques
Échantillonnage recommandé :
temperature=0.6,top_p=0.95,top_k=20
Longueur de sortie recommandée : environ 32,768 jetons pour la plupart des longues observations
Utilisez les invites système spécifiques au domaine depuis le répertoire
prompts/du dépôt pour une meilleure qualité de simulationMaintenez la longueur du contexte à au moins
128Klorsque c’est possible ; le contexte par défaut du modèle est de256K
9. Flux de travail d’évaluation d’AgentWorldBench
Si vous souhaitez tester votre propre modèle de monde sur AgentWorldBench, l’article original propose un flux de travail en trois étapes.
# 1. Cloner le dépôt d’évaluation
git clone https://github.com/QwenLM/Qwen-AgentWorld.git
cd Qwen-AgentWorld
# 2. Télécharger le jeu de données d’évaluation
huggingface-cli download Qwen/AgentWorldBench --repo-type dataset --local-dir ./AgentWorldBench
# 3. Installer les dépendances
pip install openai
cd eval
# Étape 1 : inférence du modèle de monde
python eval.py infer \
--data-dir ../AgentWorldBench \
--model-base-url http://localhost:8000/v1 \
--model-name Qwen/Qwen-AgentWorld-35B-A3B \
--output-dir ./results
# Étape 2 : notation par juge LLM. Cela nécessite une clé API OpenAI.
export OPENAI_API_KEY="your-api-key"
python eval.py judge \
--predictions ./results/predictions.jsonl \
--judge-base-url https://api.openai.com/v1 \
--judge-model gpt-5.2-2025-12-11 \
--output-dir ./results
# Étape 3 : agréger les scores
python eval.py score --predictions ./results/judged.jsonlChaque échantillon de test inclut des données d’observation de référence issues d’une exécution en environnement réel. Le benchmark évalue la capacité de modélisation du monde selon le format, la factualité, la cohérence, le réalisme et la qualité.
10. Suggestions d’affinage
Si vous souhaitez personnaliser Qwen-AgentWorld pour un domaine spécifique, l’article original recommande trois cadres d’affinage courants.
Framework | Point fort | Scénario adapté |
Forte intégration avec ModelScope | Expérimentations rapides et flux de travail de l’écosystème Alibaba | |
Communauté active et large prise en charge des stratégies d’entraînement | Déploiement d’ingénierie pratique | |
Forte optimisation de la mémoire | Ajustement fin avec ressources limitées |
11. Notes sur les sources et gestion des images
L’article original comprend plusieurs images liées aux domaines de Qwen-AgentWorld et aux résultats des benchmarks. Elles ont été conservées dans les sections pertinentes.
Les icônes de la plateforme CSDN, les modules promotionnels, les blocs d’abonnement à l’auteur, les codes QR, les boutons de récompense et les images de recommandation sans rapport ont été supprimés conformément aux exigences de publication.
FAQ
Qu’est-ce que Qwen-AgentWorld ?
Qwen-AgentWorld est un modèle de monde linguistique développé par l’équipe Qwen. Il prédit l’état suivant de l’environnement après qu’un agent a effectué une action, ce qui le rend utile pour la simulation, l’entraînement et l’évaluation d’agents.
Qwen-AgentWorld est-il identique à un modèle de chat classique ?
Non. Un modèle de chat classique est principalement optimisé pour la conversation et le suivi des instructions. Qwen-AgentWorld est entraîné comme simulateur d’environnement ; son principal cas d’utilisation est donc la prédiction des observations dans des environnements d’interaction avec des agents.
Quel modèle Qwen-AgentWorld est disponible publiquement ?
Les pages officielles indiquent Qwen-AgentWorld-35B-A3B comme les poids du modèle publiquement disponibles. AgentWorldBench est également disponible en tant que benchmark d’évaluation. Le modèle plus grand de 397B apparaît dans les tableaux de benchmarks, mais la publication publique du modèle renvoie principalement à la version 35B-A3B.
Qwen-AgentWorld peut-il être déployé avec vLLM ?
Oui. La fiche du modèle Hugging Face inclut un exemple de déploiement avec vLLM. Si vous rencontrez des problèmes d’initialisation, la fiche officielle du modèle recommande d’ajouter --language-model-only, car le checkpoint contient les poids du modèle de langage.
Qwen-AgentWorld peut-il être déployé avec SGLang ?
Oui. SGLang fait partie des options de déploiement recommandées et peut exposer un point de terminaison d’API compatible avec OpenAI. Le modèle peut ensuite être appelé via des requêtes d’API locales.
Pourquoi Qwen-AgentWorld a-t-il besoin d’une longue fenêtre de contexte ?
La simulation d’environnements d’agents dépend souvent de longs historiques d’interactions. Une fenêtre de contexte plus courte peut faire perdre des informations d’état importantes ; les recommandations officielles conseillent donc de conserver au moins 128K jetons lorsque c’est possible.
À quoi sert AgentWorldBench ?
AgentWorldBench est le benchmark publié avec Qwen-AgentWorld. Il évalue les modèles de mondes linguistiques dans sept domaines selon des dimensions telles que le format, la factualité, la cohérence, le réalisme et la qualité.
Qwen-AgentWorld est-il adapté à une utilisation en production ?
Il peut être utile pour la recherche, l’évaluation, la simulation et les expérimentations internes. Pour les systèmes de production, vous devez néanmoins évaluer la latence, le coût matériel, la sécurité, la fiabilité des prompts et déterminer si les résultats simulés correspondent suffisamment à votre environnement réel.
Outils associés
Qwen-AgentWorld GitHub : dépôt officiel du code, des prompts et du flux de travail d’évaluation de Qwen-AgentWorld.
Qwen-AgentWorld-35B-A3B sur Hugging Face : page officielle du modèle pour les poids publics 35B-A3B.
AgentWorldBench : jeu de données de référence officiel pour l’évaluation des modèles de monde linguistiques.
SGLang : framework de service rapide pour les grands modèles de langage.
vLLM : moteur d’inférence à haut débit pour le service des LLM.
Transformers : bibliothèque Hugging Face pour le chargement et l’inférence de modèles en local.
SDK Python OpenAI : client Python capable d’appeler des serveurs de modèles locaux compatibles avec OpenAI.
ms-swift : le framework d’entraînement et de réglage fin de ModelScope pour les flux de travail LLM.
Liens connexes
Rapport technique Qwen-AgentWorld : l’article officiel arXiv présentant le modèle, le benchmark et la configuration d’entraînement.
Blog officiel de Qwen-AgentWorld : l’article officiel de Qwen annonçant le lancement du projet.
Dépôt GitHub de Qwen-AgentWorld : source principale pour les prompts, les scripts d’évaluation et la documentation du projet.
Fiche du modèle Qwen-AgentWorld-35B-A3B : page officielle Hugging Face avec des exemples de déploiement et d’inférence.
Jeu de données AgentWorldBench : jeu de données de benchmark officiel utilisé pour l’évaluation du modèle.
Documentation de SGLang : documentation pour servir des LLM avec SGLang.
Documentation de vLLM : documentation pour l’inférence LLM à haut débit et le service compatible avec OpenAI.
LLaMA-Factory : framework open source populaire pour le fine-tuning des LLM et les expériences de déploiement.


