
Qwen-AgentWorldは、エージェント環境のシミュレーションを目的としてQwenチームが公開した言語ワールドモデルです。一般的なチャットモデルのように質問に答えるだけでなく、エージェントが行動を取った後に環境が何を返すかを予測するように設計されています。
そのため、AIエージェント研究、シミュレーションによる強化学習、ベンチマーク評価、そしてターミナル、ソフトウェアエンジニアリング、検索、MCP、Web、オペレーティングシステム、Android風環境に関するローカル実験に特に適しています。
この記事は、元の中国語記事を軽く書き直し、翻訳したものです。構成、技術的な流れ、コマンド、表、主要な考え方は維持しつつ、英語で読みやすく、SEO向けに公開しやすいよう言語を調整しています。
出典注記: 元記事はCSDNで公開されており、CC BY-SA 4.0ライセンスに従うと記載されています。元の出典:Qwen-AgentWorld完全デプロイガイド:無料オープンソース、性能はGPT-5.4超え、5分で起動。 検証注記: Qwenの公式ページでは、
Qwen-AgentWorld-35B-A3Bのモデル重みとAgentWorldBenchの公開リリースが確認されています。より大規模なQwen-AgentWorld-397B-A17Bは公式ベンチマーク結果に含まれていますが、公開モデルページおよびGitHubリリースでは主に35B-A3Bモデルの重みが示されています。
1. 背景:なぜ言語ワールドモデルが必要なのか?
過去2年間で、AIエージェントは単純なチャットアシスタントから、ウェブサイトの操作、ターミナルコマンドの実行、モバイルアプリの制御、ソフトウェアエンジニアリングタスクの完了まで行えるツールへと急速に進化してきました。
しかし、強力なエージェントを訓練するには費用がかかります。多くの場合、実際の環境との大量のインタラクションが必要であり、それによっていくつかの実務上の問題が生じます。
環境の構築と維持には手間がかかります。
データ収集は遅く、スケールさせるのが困難です。
実環境にはリスクが伴います。特に、失敗ケースをテストしたり、制御された障害を注入したりする場合はなおさらです。
Language World Model、すなわちLWMは、この問題を解決するために構築されています。その考え方はシンプルですが強力です。モデルに環境の役割を担わせるのです。エージェントの行動とインタラクション履歴が与えられると、モデルは次の環境状態を予測します。
この仕組みにより、エージェントは常に実システムに依存するのではなく、シミュレーション内で訓練および評価できます。
2026年6月24日、Qwenチームは、7つのエージェントインタラクション領域を1つのモデルに統合したネイティブな言語世界モデルであるQwen-AgentWorldをリリースしました。併せて、関連ベンチマークであるAgentWorldBenchもリリースされました。
公式リソース:
GitHub:QwenLM/Qwen-AgentWorld
2. 中核となる考え方:「ネイティブ」な世界モデルとは何か?
ここで重要なのは、ネイティブという言葉です。Qwen-AgentWorldは、環境を模倣するように訓練後に適応された単なる汎用LLMではありません。その世界モデリングの目標は、最初から訓練プロセスに組み込まれています。
比較項目 | 従来のアプローチ | Qwen-AgentWorld |
学習の出発点 | 汎用LLMをファインチューニングする | CPT以降、環境モデリングを目標として扱う |
学習プロセス | 通常はSFTまたはRLのみ | CPT → SFT → RL |
環境知識 | 追加データまたは適応によって付加される | 学習中に内在化される |
ドメインカバレッジ | 1つまたはいくつかのドメイン | 1つのモデルに7つのドメイン |
言い換えれば、Qwen-AgentWorld は単にプロンプトで包んだ汎用モデルではありません。パイプラインの下位層から、環境の次の状態を予測するように訓練されています。
これにより、特に長いインタラクション軌跡をシミュレートする際に、モデルは環境ダイナミクスをより構造化して理解できるようになります。
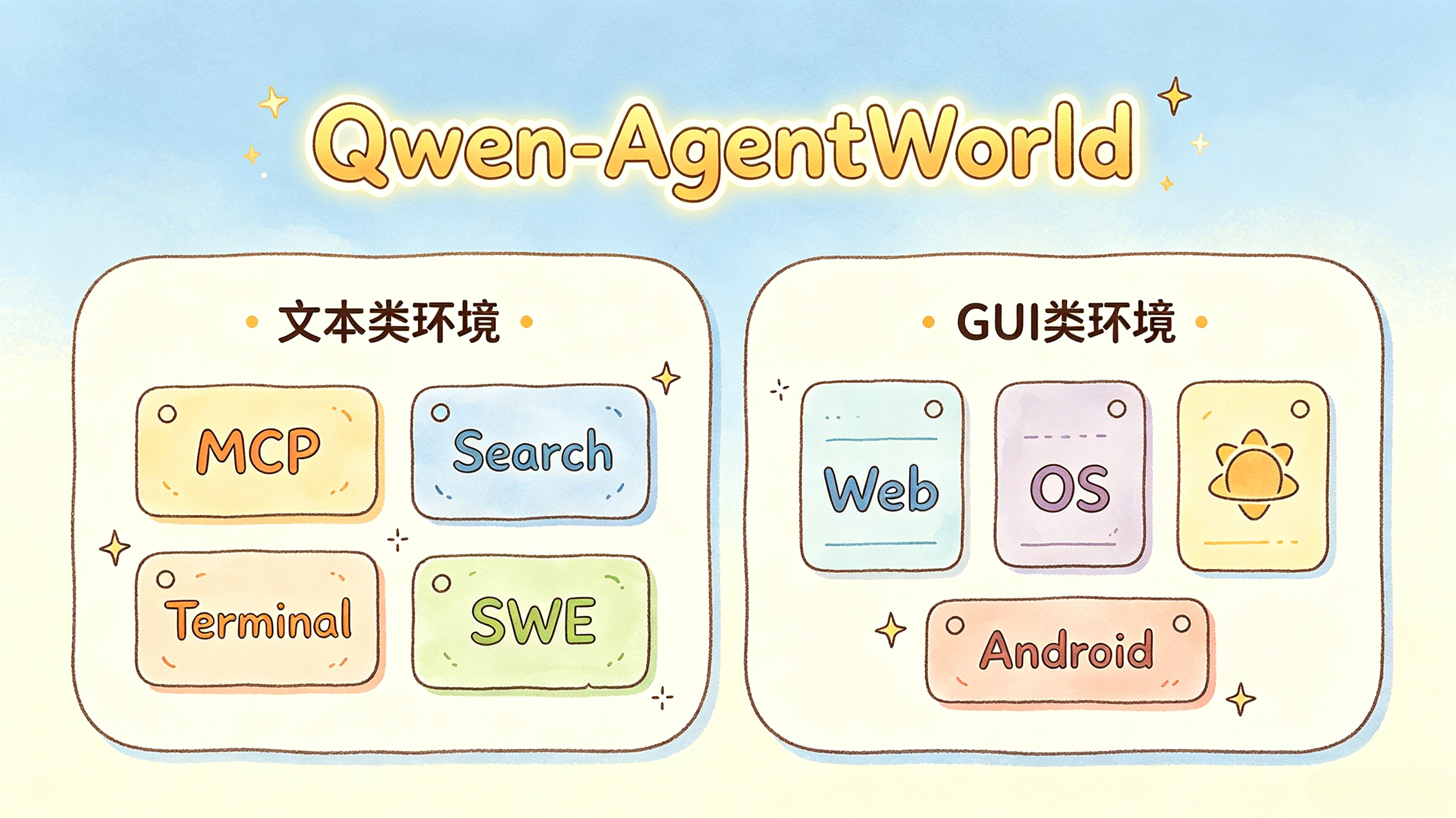
3. 7つのドメイン:1つのモデルにおけるテキスト環境とGUI環境
Qwen-AgentWorld は、エージェントのインタラクションシナリオを、テキストベース環境とGUIベース環境という2つの大きなグループに分けています。
┌──────────────────────────────────────────┐
│ Qwen-AgentWorld │
│ │
│ テキスト環境 GUI環境 │
│ ┌──────────┐ ┌──────────────────┐ │
│ │ MCP │ │ Web │ │
│ │ 検索 │ │ OS │ │
│ │ 端末 │ │ Android │ │
│ │ SWE │ └──────────────────┘ │
│ └──────────┘ │
└──────────────────────────────────────────┘ドメイン | 種類 | 説明 |
MCP | テキスト | ツール呼び出しと Model Context Protocol のインタラクション |
検索 | テキスト | 検索エンジンとのインタラクションと取得動作 |
ターミナル | テキスト | Linux ターミナルコマンドの実行 |
SWE | テキスト |
コード修正などのソフトウェアエンジニアリングタスク
Web
GUI
ブラウザおよびウェブページの操作
OS
GUI
デスクトップオペレーティングシステムの操作
Android
GUI
モバイルアプリおよびAndroid風UIの操作
3つのGUI領域では、観測は生のピクセルフレームではなく、レンダリング可能なコードとして表現されます。これにより、テキストベースの世界モデルが、完全な画像シーケンスを直接処理することなく視覚環境を扱えるようになります。
このモデルは、7つの領域にわたる1,000万件以上の実世界のインタラクション軌跡で訓練されました。
4. 3段階のトレーニングパイプライン
Qwen-AgentWorldは、連結された3段階のトレーニングパイプライン(CPT → SFT → RL)を使用します。
ステージ1: CPT — 環境知識の注入
継続的事前学習の間、モデルは大規模な実環境でのインタラクション軌跡から学習します。このステージでは、環境ダイナミクスがモデルの重みに埋め込まれます。
元の記事では、ターンレベルの情報理論的損失マスクについても言及されています。その目的は、どの対話ターンが実際に環境状態情報を含んでいるかを特定し、あまり有用でないターンからのノイズを減らすことです。
ステージ2: SFT — Chain-of-Thought推論の活性化
教師ありファインチューニングは、次状態予測をChain-of-Thought形式の推論パターンへと変換します。
予測結果を直接出力するのではなく、モデルは次の観測を生成する前に、なぜ状態が変化すべきなのかを推論することを学習します。
ステージ3: RL — シミュレーション忠実度の向上
強化学習ステージでは、GSPOアルゴリズムを含むハイブリッド報酬信号を使用して、出力品質を向上させます。
最適化の焦点は次のとおりです。
形式の正確性
事実の正確性
文脈の一貫性
リアリズム
全体的なシミュレーション品質
元の記事で言及されている創発的行動: Qwen-AgentWorldは、自己修正行動、検索シナリオにおける情報漏洩の防止、および一部のコマンド出力予測における多段階の因果推論を示すと報告されています。
5. オープンソースモデル一覧
リリース | パラメータ数 | アクティブ化パラメータ数 | コンテキスト長 | 位置づけ |
Qwen-AgentWorld-35B-A3B | 35B | 3B | 256Kトークン | 公開されている効率的なオープンモデル |
Qwen-AgentWorld-397B-A17B | 397B | 17B | 元の表には明確に記載されていません |
フラッグシップ・ベンチマークモデル
AgentWorldBench
—
—
—
評価ベンチマーク
35B-A3B アーキテクチャの詳細
ベースモデル: Qwen3.5-35B-A3B-Base
モデルタイプ: 因果言語モデル / 言語世界モデル
アーキテクチャ形式: ハイブリッド線形アテンション + MoE
隠れ次元: 2048
レイヤー数: 40層
レイヤー構成: Gated DeltaNet、Gated Attention、MoEコンポーネントを含む反復グループ
エキスパート: 256エキスパート
有効化されるエキスパート: 8つのルーティングエキスパート + 1つの共有エキスパート
コンテキスト長: 262,144トークン
推奨される最小コンテキスト: より高品質な長期軌跡シミュレーションのために128Kトークン
公式のHugging Faceドキュメントでも、このモデルはTransformers、vLLM、SGLangと互換性があると記されています。
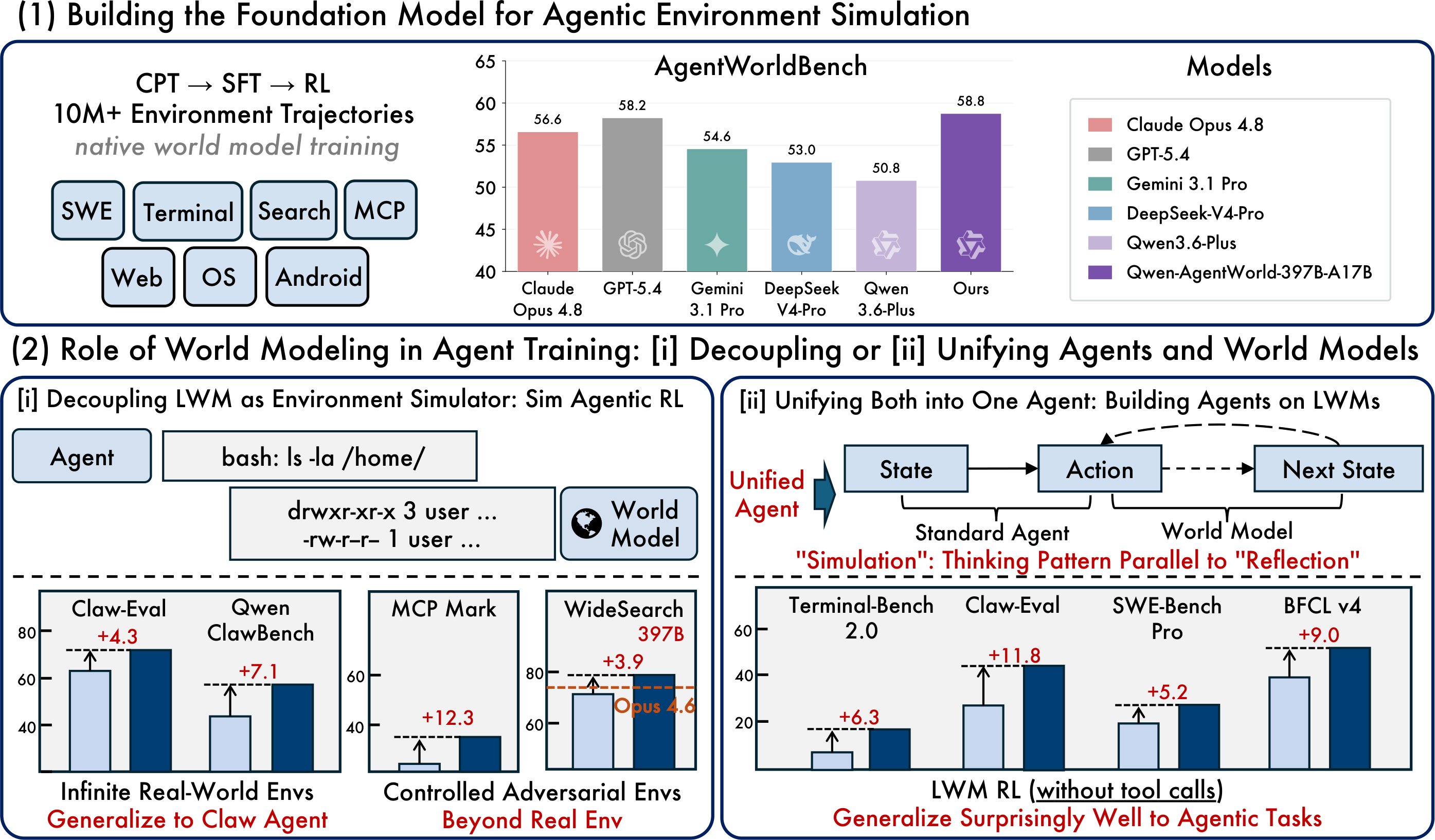
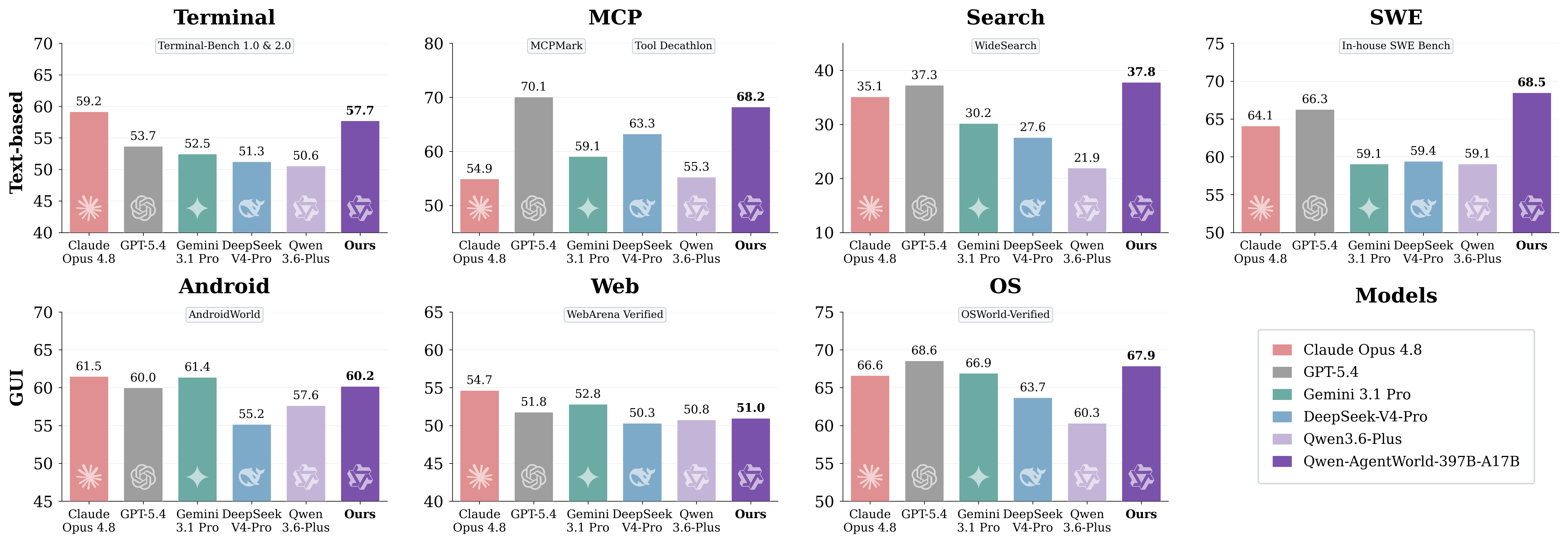
6. 性能比較: AgentWorldBenchの結果
AgentWorldBenchは、各モデルを5つの次元(Format、Factuality、Consistency、Realism、Quality)で評価します。スコアは0〜100の尺度に正規化され、数値が高いほど優れています。
総合スコアによる完全ランキング
モデル | MCP | 検索 | ターミナル | SWE | Android | Web | OS | 総合 |
Qwen-AgentWorld-397B-A17B | 68.24 | 37.82 | 57.73 | 68.49 | 60.20 | 50.98 | 67.89 | 58.71 |
GPT-5.4 | 70.10 | 37.26 | 53.69 | 66.29 | 60.00 | 51.80 | 68.58 | 58.25 |
Claude Opus 4.6 | 69.90 | 29.30 | 57.51 | 64.55 | 61.74 | 51.42 | 70.20 | 57.80 |
Claude Opus 4.8 | 54.93 | 35.14 | 59.18 | 64.10 | 61.50 | 54.66 | 66.62 | 56.59 |
Qwen-AgentWorld-35B-A3B | 64.79 | 36.69 | 53.96 | 65.63 | 58.17 | 49.55 | 65.92 | 56.39 |
Claude Sonnet 4.6 | 70.00 | 28.79 | 56.98 | 64.52 | 58.03 | 50.78 | 63.17 | 56.04 |
Qwen3.5-397B-A17B | 68.31 | 30.81 | 55.30 | 64.44 | 54.90 | 48.55 | 54.74 | |
Gemini 3.1 Pro | 59.07 | 30.21 | 52.47 | 59.07 | 61.40 | 52.83 | 66.92 | 54.57 |
DeepSeek-V4-Pro | 63.27 | 27.61 | 51.26 | 59.44 | 55.17 | 50.32 | 63.70 | 52.97 |
Qwen3.5-35B-A3B | 57.87 | 25.98 | 46.13 | 47.58 | 53.18 | 47.10 | 56.27 | 47.73 |
元の記事からの主な要点:
Qwen-AgentWorld-397B-A17Bは総合スコア 58.71 に達し、掲載されている AgentWorldBench の表で第1位にランクされています。Qwen-AgentWorld-35B-A3Bは、ベースモデルであるQwen3.5-35B-A3Bと比べて +8.66 ポイント 向上しています。
実用上の注意: ベンチマークの数値は、公式ベンチマーク設定に基づく参考データとして扱ってください。実際の結果は、ハードウェア、プロンプト設計、提供フレームワーク、コンテキスト長、およびシミュレーションされる環境によって異なります。
7. 4つのアプリケーションパターンと実験結果
パターン1:汎化可能な OOD 環境拡張
元の記事では、Qwen-AgentWorld-397B-A17Bを使用して、4,000の分布外OpenClaw環境でシミュレートされたRLを行い、その後、新しいドメインでゼロショット汎化をテストすることが説明されています。
トレーニング方法 | Claw-Eval | QwenClawBench |
ベースSFT | 65.4 | 47.9 |
汎用モデルシミュレーターを用いたSim RL | 66.7 | 47.8 |
Qwen-AgentWorldシミュレーターを用いたSim RL | 69.7 | 55.0 |
改善幅 | +4.3 | +7.1 |
パターン2:制御可能なシミュレーション — MCPによる標的型摂動
制御された摂動は、標準的な実環境でのトレーニングよりも効果的にエージェントの弱点を明らかにできます。
構成 | Tool Decathlon | MCPMark |
ベースSFT | 32.4 | 21.5 |
制御なしのSim RL | 31.5 | 24.6 |
制御ありのSim RL | 36.1 | 33.8 |
改善 | +3.7 | +12.3 |
パターン3:架空世界の構築 — 検索ドメイン
検索ドメインの実験では、訓練に架空だが自己一貫性のある検索世界を使用し、その後、実際の検索タスクで汎化性能を評価します。
構成 | WideSearch F1 項目 | WideSearch F1 行 |
ベース SFT、35B | 34.02 | 13.72 |
+ Sim RL 架空世界 | 50.31 | 24.21 |
改善幅 | +16.29 | +10.49 |
パターン4:エージェント基盤モデル — LWM RL ウォームアップ転移
この記事では、特定のタスクに対する追加のRLファインチューニングを行わずに下流エージェントの性能を向上させる方法として、LWM RLウォームアップについても説明しています。
指標 | Terminal-Bench 2.0 | SWE-Bench Verified | SWE-Bench Pro | WideSearch F1 | Claw-Eval | BFCL v4 |
ベースSFT | 33.25 | 64.47 | 42.18 | 33.38 | 53.60 | 62.29 |
+ LWM RLウォームアップ | 39.55 | 67.86 | 47.42 | 46.17 | 64.88 | 71.25 |
改善 | +6.30 | +3.39 | +5.24 | +12.79 | +11.28 | +8.96 |
注目点:ウォームアップデータは単一ターンの非エージェント的な軌跡から得られたものですが、その改善は、より複雑なマルチターンのツール呼び出しエージェントタスクにも転移します。これは、世界モデリングの知識が元の学習形式を超えて転移できることを示唆しています。
8. クイックデプロイガイド
方法1:SGLangでデプロイする
SGLangは、高速なサービングのために元の記事で推奨されています。
pip install sglangpython -m sglang.launch_server \
--model-path Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tp-size 4 \
--context-length 262144 \
--reasoning-parser qwen3起動後、OpenAI 互換 API エンドポイントは次のとおりです。
http://localhost:8000/v1方法 2: vLLM でデプロイする
pip install vllmvllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--trust-remote-code公式ドキュメントの注記: 現在の Hugging Face モデルカードでは、モデルアーキテクチャに視覚コンポーネントの定義が含まれている一方で、チェックポイントには言語モデルの重みが含まれているため、vLLM で
--language-model-onlyを使用することも推奨されています。vLLM の初期化に失敗する場合は、このフラグを追加してみてください。
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--language-model-only \
--trust-remote-code方法 3: Transformers によるローカル推論
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
messages = [
{
"role": "system",
"content": "あなたは Linux ターミナル環境をシミュレートする言語世界モデルです。"
"ユーザーのコマンドが与えられたら、ターミナル出力を予測してください。"
},
{
"role": "user",
"content": "アクション: execute_bash\nコマンド: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)方法 4: OpenAI 互換 API 経由で呼び出す
この方法は、SGLang または vLLM を通じてモデルを提供した後に機能します。
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
messages = [
{
"role": "system",
"content": "あなたは Linux ターミナル環境をシミュレートする言語世界モデルです。"
},
{
"role": "user",
"content": "アクション: execute_bash\nコマンド: pwd"
}
]
response = client.chat.completions.create(
model="Qwen/Qwen-AgentWorld-35B-A3B",
messages=messages,
max_tokens=32768,
temperature=0.6,
)
print(response.choices[0].message.content)ベストプラクティス
推奨サンプリング:
temperature=0.6、top_p=0.95、top_k=20
推奨出力長: ほとんどの長い観測では約 32,768 トークン
シミュレーション品質を向上させるため、リポジトリの
prompts/ディレクトリにあるドメイン固有のシステムプロンプトを使用してください可能な場合はコンテキスト長を少なくとも
128Kに保ってください。デフォルトのモデルコンテキストは256Kです
9. AgentWorldBench 評価ワークフロー
AgentWorldBench で独自のワールドモデルをテストしたい場合、元の記事では 3 ステップのワークフローが示されています。
# 1. 評価リポジトリをクローンする
git clone https://github.com/QwenLM/Qwen-AgentWorld.git
cd Qwen-AgentWorld
# 2. 評価データセットをダウンロードする
huggingface-cli download Qwen/AgentWorldBench --repo-type dataset --local-dir ./AgentWorldBench
# 3. 依存関係をインストールする
pip install openai
cd eval
# ステップ 1: ワールドモデル推論
python eval.py infer \
--data-dir ../AgentWorldBench \
--model-base-url http://localhost:8000/v1 \
--model-name Qwen/Qwen-AgentWorld-35B-A3B \
--output-dir ./results
# ステップ 2: LLM ジャッジによるスコアリング。これには OpenAI API キーが必要です。
export OPENAI_API_KEY="your-api-key"
python eval.py judge \
--predictions ./results/predictions.jsonl \
--judge-base-url https://api.openai.com/v1 \
--judge-model gpt-5.2-2025-12-11 \
--output-dir ./results
# ステップ 3: スコアを集計する
python eval.py score --predictions ./results/judged.jsonl各テストサンプルには、実際の環境実行から得られた正解の観測データが含まれています。このベンチマークは、形式、事実性、一貫性、リアリズム、品質の観点からワールドモデリング能力を評価します。
10. ファインチューニングの提案
特定のドメイン向けにQwen-AgentWorldをカスタマイズしたい場合、原論文では一般的な3つのファインチューニングフレームワークが推奨されています。
フレームワーク | 強み | 適したシナリオ |
ModelScope との高い統合性 | 迅速な実験と Alibaba エコシステムのワークフロー | |
活発なコミュニティと幅広い学習戦略のサポート | 実用的なエンジニアリング展開 | |
強力なメモリ最適化 | リソース制約下でのファインチューニング |
11. 出典に関する注記と画像の取り扱い
元の記事には、Qwen-AgentWorld のドメインやベンチマーク結果に関連する複数の画像が含まれています。これらは該当するセクションに残されています。
CSDN プラットフォームのアイコン、プロモーションモジュール、著者購読ブロック、QR コード、投げ銭ボタン、および無関係なおすすめ画像は、公開要件に従って削除されました。
FAQ
Qwen-AgentWorld とは何ですか?
Qwen-AgentWorld は、Qwen チームによる言語世界モデルです。エージェントが行動を取った後の次の環境状態を予測するため、エージェントのシミュレーション、トレーニング、評価に役立ちます。
Qwen-AgentWorld は通常のチャットモデルと同じですか?
いいえ。通常のチャットモデルは主に会話と指示追従に最適化されています。Qwen-AgentWorld は環境シミュレーターとして訓練されているため、主な用途はエージェント相互作用環境における観測の予測です。
公開されている Qwen-AgentWorld モデルはどれですか?
公式ページでは、Qwen-AgentWorld-35B-A3B が公開リリースされたモデル重みとして記載されています。AgentWorldBench も評価ベンチマークとして利用可能です。より大きな 397B モデルはベンチマーク表に登場しますが、公開モデルのリリースは主に 35B-A3B バージョンを指しています。
Qwen-AgentWorld は vLLM でデプロイできますか?
はい。Hugging Face のモデルカードには vLLM によるサービング例が含まれています。初期化の問題が発生した場合、公式モデルカードでは、チェックポイントに言語モデルの重みが含まれているため --language-model-only を追加することを推奨しています。
Qwen-AgentWorld は SGLang でデプロイできますか?
はい。SGLang は推奨されるサービングオプションの一つであり、OpenAI 互換の API エンドポイントを公開できます。その後、ローカル API リクエストを通じてモデルを呼び出すことができます。
Qwen-AgentWorld に長いコンテキストウィンドウが必要なのはなぜですか?
エージェント環境のシミュレーションは、多くの場合、長い対話履歴に依存します。コンテキストウィンドウが短いと重要な状態情報が失われる可能性があるため、公式ガイダンスでは、可能な場合は少なくとも 128K トークンを維持することを推奨しています。
AgentWorldBench は何に使用されますか?
AgentWorldBench は Qwen-AgentWorld とともに公開されたベンチマークです。形式、事実性、一貫性、リアリズム、品質などの観点から、7 つのドメインにわたって言語ワールドモデルを評価します。
Qwen-AgentWorld は本番環境での使用に適していますか?
研究、評価、シミュレーション、社内実験に役立つ可能性があります。本番システムでは、レイテンシ、ハードウェアコスト、安全性、プロンプトの信頼性、およびシミュレーション結果が実環境と十分に一致しているかどうかを評価する必要があります。
関連ツール
Qwen-AgentWorld GitHub: Qwen-AgentWorld のコード、プロンプト、評価ワークフローの公式リポジトリ。
Hugging Face の Qwen-AgentWorld-35B-A3B: 公開されている 35B-A3B 重みの公式モデルページ。
AgentWorldBench: 言語世界モデルを評価するための公式ベンチマークデータセット。
SGLang: 大規模言語モデル向けの高速サービングフレームワーク。
vLLM: LLM を提供するための高スループット推論エンジン。
Transformers: ローカルモデルの読み込みと推論のための Hugging Face ライブラリ。
OpenAI Python SDK: OpenAI 互換のローカルモデルサーバーを呼び出せる Python クライアント。
ms-swift: LLM ワークフロー向けの ModelScope のトレーニングおよびファインチューニングフレームワーク。
関連リンク
Qwen-AgentWorld 技術レポート: モデル、ベンチマーク、トレーニング設定を紹介する公式 arXiv 論文。
Qwen-AgentWorld 公式ブログ: このプロジェクトに関する Qwen の公式リリース記事。
Qwen-AgentWorld GitHub リポジトリ: プロンプト、評価スクリプト、プロジェクトドキュメントの主要ソース。
Qwen-AgentWorld-35B-A3B モデルカード: デプロイと推論の例を掲載した公式 Hugging Face ページ。
AgentWorldBench データセット: モデル評価に使用される公式ベンチマークデータセット。
SGLang ドキュメント: SGLang を用いた LLM 提供に関するドキュメント。
vLLM ドキュメント: 高スループットな LLM 推論と OpenAI 互換サービングに関するドキュメント。
LLaMA-Factory: LLM のファインチューニングおよびデプロイ実験のための人気のオープンソースフレームワーク。


