
La réponse courte : non, mais l’orientation est importante
DiffusionGemma ne signifie pas que Google déclare la mort de la prédiction du prochain jeton. Il faut plutôt le comprendre comme un signal expérimental sérieux : Google teste une voie différente pour la génération de texte par IA, où la vitesse, le parallélisme et les flux de travail locaux interactifs comptent davantage que le rythme familier, un jeton à la fois, des LLM standard.
Google décrit DiffusionGemma comme un modèle ouvert expérimental construit autour de la diffusion de texte. Au lieu de produire du texte strictement de gauche à droite, il génère des blocs de texte en affinant un canevas de jetons bruités ou de substitution. La promesse pratique est simple : si un modèle peut travailler sur de nombreuses positions à la fois, il peut utiliser plus efficacement le calcul GPU et réduire la latence d’inférence pour certains cas d’usage.
Mais cela ne signifie pas que les modèles de langage autorégressifs seront remplacés demain. Le propre billet de lancement de Google reste prudent quant aux compromis. Il indique que les modèles Gemma 4 standard restent recommandés pour les applications qui exigent une qualité de production maximale. Cette seule phrase compte. DiffusionGemma est un modèle de recherche et de développement axé sur la vitesse, et non un remplacement universel du paradigme dominant des LLM.
Pourquoi la prédiction du prochain jeton est devenue la norme
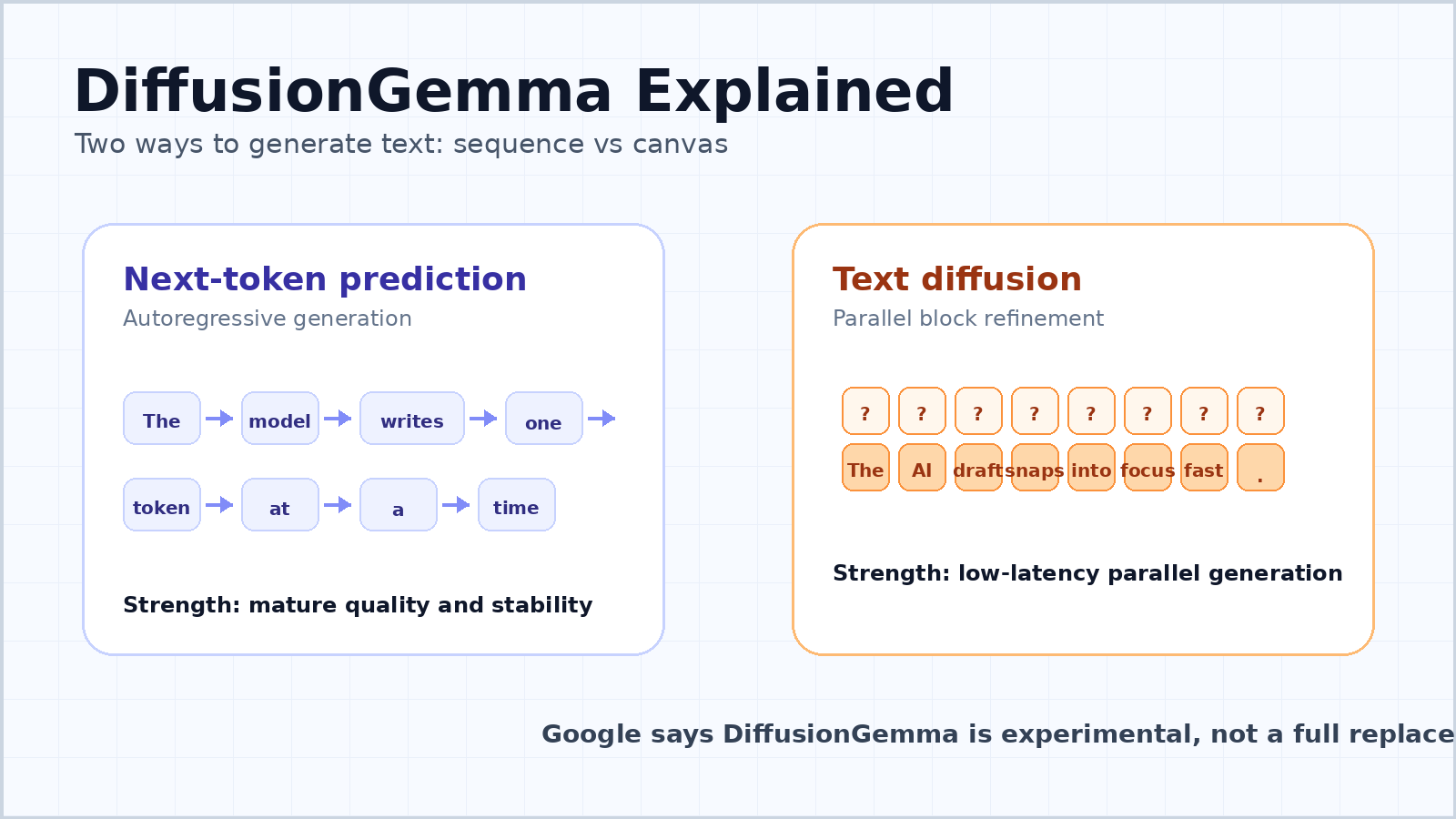
La plupart des chatbots et grands modèles de langage modernes sont autorégressifs. Ils lisent l’invite, puis prédisent le prochain jeton, puis le jeton suivant, et continuent jusqu’à ce que la réponse soit complète. C’est le modèle mental simple derrière la prédiction du prochain jeton.
La raison pour laquelle elle est devenue dominante n’est pas un hasard. Les modèles autorégressifs sont flexibles, stables et faciles à faire monter en échelle. Ils peuvent générer du texte de longueur variable, préserver la cohérence de gauche à droite et fonctionner efficacement dans le chat, le codage, la traduction, le résumé, le raisonnement et l’utilisation d’outils. Cette approche s’aligne aussi naturellement avec la manière dont la langue écrite se déploie.
Son point faible est la latence. Un modèle jeton par jeton présente une dépendance séquentielle : le jeton 100 dépend des jetons 1 à 99, et le jeton 101 dépend du jeton 100. Même lorsque le GPU est puissant, le modèle doit parcourir la séquence étape par étape. Pour un utilisateur posant une seule question, une grande partie du matériel peut rester sous-utilisée parce que le modèle attend les déplacements de mémoire et le décodage séquentiel.
Ce que DiffusionGemma fait différemment
DiffusionGemma s’inspire des modèles de diffusion, la famille de modèles génératifs devenue célèbre dans la génération d’images et de vidéos. Au lieu de rédiger la réponse un jeton à la fois, un modèle de diffusion commence par du bruit ou de l’incertitude et l’affine progressivement pour obtenir une sortie cohérente.
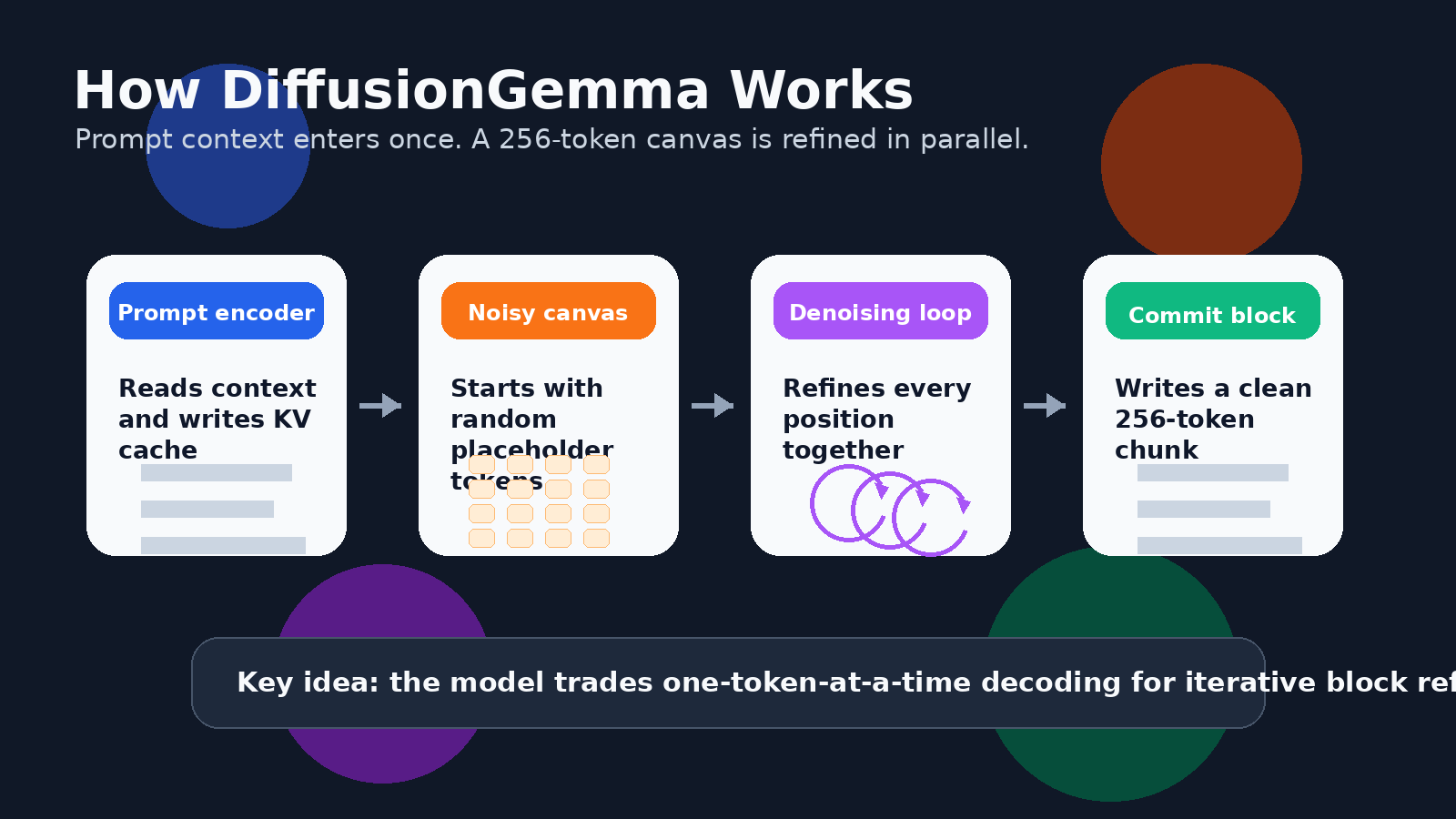
Pour le texte, cela signifie que le modèle peut travailler sur un bloc de jetons en parallèle. Le guide développeur de Google décrit un canevas de 256 jetons. Le modèle commence avec un canevas de jetons de substitution aléatoires, puis débruite à plusieurs reprises l’ensemble du bloc. Les positions de jetons sûres deviennent des points d’ancrage, les positions incertaines sont à nouveau affinées, et le bloc devient progressivement net.
Ce n’est pas la même chose que générer un long essai entier en une seule passe. DiffusionGemma utilise une approche autorégressive par blocs pour les sorties plus longues. Une fois qu’un bloc de 256 jetons est entièrement affiné, il est enregistré dans le cache KV, puis le modèle passe au bloc suivant. Il conserve donc une structure de gauche à droite entre les blocs, mais, à l’intérieur de chaque bloc, il peut affiner de nombreux jetons ensemble.
Pourquoi il peut être plus rapide
L’histoire de la vitesse concerne le goulot d’étranglement matériel. Les modèles autorégressifs traditionnels peuvent être limités par la bande passante mémoire, car le modèle recharge sans cesse les poids tout en générant un jeton à la fois. DiffusionGemma tente de déplacer une plus grande partie du travail vers le calcul en donnant au GPU une charge de travail parallèle plus importante à l’intérieur de chaque bloc.
Google affirme que DiffusionGemma peut offrir une génération de jetons jusqu’à quatre fois plus rapide sur des GPU dédiés, avec des exemples incluant plus de 1000 jetons par seconde sur un seul NVIDIA H100 et plus de 700 jetons par seconde sur une RTX 5090. Ces chiffres ne constituent pas une promesse générale pour chaque tâche, appareil ou taille de lot. Ils signalent un schéma de génération spécifique, adapté au matériel.
C’est pourquoi DiffusionGemma est particulièrement intéressant pour les flux de travail locaux et interactifs. Si un utilisateur demande des modifications rapides, des complétions de code, des brouillons structurés ou des itérations rapides, le GPU peut disposer d’une capacité de calcul inutilisée qu’un modèle autorégressif ne peut pas exploiter pleinement. Un modèle de langage à diffusion peut être mieux adapté à ce type de charge de travail à faible batch et sensible à la vitesse.
Le rôle de l’attention bidirectionnelle et de l’autocorrection
L’une des différences les plus importantes est l’attention bidirectionnelle. Pendant le débruitage, les tokens présents sur le canevas peuvent prêter attention à d’autres positions dans le bloc, et pas seulement aux tokens précédents. Cela change la sensation de génération. Le modèle peut utiliser le contexte des deux côtés d’un passage manquant ou incertain.
C’est particulièrement utile pour les problèmes textuels non linéaires. Google cite l’édition en ligne, la complétion de code, les graphes mathématiques et même la génération contrainte de type Sudoku comme des exemples où les positions futures comptent. Un modèle autorégressif standard peut être performant dans de nombreuses tâches, mais une fois qu’il émet un token précoce, il est généralement contraint de le conserver. Le débruitage de type diffusion crée un espace de révision avant que le bloc ne soit finalisé.
C’est aussi pourquoi l’expression autocorrection revient souvent à propos de DiffusionGemma. Le modèle ne se contente pas de taper du texte. Il évalue à plusieurs reprises l’ensemble du canevas, conserve les positions fiables, remplace celles qui sont incertaines et affine le bloc jusqu’à convergence.
Ce que signifie la conception MoE 26B
DiffusionGemma repose sur une architecture Mixture of Experts 26B issue de la famille Gemma 4, avec seulement un sous-ensemble actif plus réduit utilisé lors de l’inférence. La documentation IA de Google le décrit comme un modèle 26B avec environ 4B de paramètres actifs, tandis que le guide développeur explique que le modèle est conçu pour tenir dans des limites de 18 Go de VRAM une fois quantifié.
L’idée clé est l’efficacité. Un modèle MoE clairsemé peut avoir un grand nombre total de paramètres tout en n’activant que certains experts sélectionnés pour un token ou une tâche donnée. Cela peut améliorer les capacités sans nécessiter que l’ensemble du modèle soit actif à chaque étape.
Pour les développeurs, c’est important, car DiffusionGemma n’est pas seulement une démonstration de laboratoire. Il est publié comme un modèle à poids ouverts sous licence Apache 2.0, avec une documentation pour vLLM, Hugging Face, Google Cloud Model Garden et d’autres voies de déploiement. Google invite clairement l’écosystème à tester si la génération fondée sur la diffusion peut devenir pratique dans de véritables applications.
Dans quels cas DiffusionGemma est pertinent

Les meilleurs cas d’usage ne sont pas nécessairement la rédaction longue haut de gamme. Ce sont des tâches critiques en matière de vitesse, où l’utilisateur bénéficie d’itérations rapides. L’édition en ligne en est un exemple. Au lieu d’attendre qu’un modèle réécrive un paragraphe token par token, un modèle à diffusion peut affiner rapidement tout un passage.
La complétion de code est un autre candidat solide. Un développeur peut avoir besoin qu’un modèle remplisse le milieu d’une fonction ou ajuste un bloc de code en tenant compte de ce qui vient avant et après. L’attention bidirectionnelle est utile ici, car le modèle peut raisonner sur les deux côtés de la section manquante.
La génération structurée et contrainte est également intéressante. Si la sortie comporte de multiples dépendances, comme un tableau, une énigme, un modèle ou un schéma formel, l’affinement par blocs peut donner au modèle davantage de marge pour coordonner les positions entre elles. C’est pourquoi DiffusionGemma ne se résume pas à être plus rapide. Il ouvre aussi la voie à un style d’interaction différent pour la génération.
Là où les modèles autorégressifs restent supérieurs
Le compromis concerne la qualité. Google indique explicitement que DiffusionGemma privilégie la vitesse et la génération de mise en page parallèle, et que sa qualité globale de sortie est inférieure à celle de Gemma 4 standard. C’est la raison centrale pour laquelle il ne faut pas le décrire comme un remplacement pur et simple de la prédiction du token suivant.
Les modèles autorégressifs conservent des avantages majeurs. Ils sont profondément optimisés pour la production, performants sur de nombreuses tâches généralistes et pris en charge par des infrastructures de service matures. Ils fonctionnent aussi naturellement pour les flux conversationnels où le modèle prolonge le texte dans une séquence régulière.
L’avenir réaliste ne verra probablement pas une méthode de décodage en remplacer une autre. Il est plus probable que les systèmes d’IA orientent différentes tâches vers différentes stratégies de génération. Les modèles autorégressifs pourraient rester le choix par défaut pour le chat généraliste et le raisonnement de haute qualité, tandis que les modèles de langage à diffusion pourraient alimenter l’édition rapide, la génération locale, la complétion de code et d’autres charges de travail interactives.
Ce que les développeurs doivent surveiller ensuite
La plus grande question est de savoir si les modèles de langage à diffusion peuvent combler l’écart de qualité tout en conservant leur avantage en matière de latence. La vitesse seule ne suffit pas si la sortie nécessite trop de corrections. Mais si la qualité s’améliore, cette architecture pourrait devenir très importante pour l’IA locale, les assistants d’IDE, l’édition de documents et les interfaces en temps réel.
La deuxième question concerne l’infrastructure de service. La prise en charge de vLLM est importante, car les modèles de langage à diffusion nécessitent un comportement de décodage différent : attention bidirectionnelle, débruitage itératif, échantillonnage personnalisé et logique de validation au niveau des blocs. Si les frameworks d’inférence rendent cela facile, davantage de développeurs expérimenteront.
La troisième question concerne la conception produit. Un modèle de texte à diffusion n’est pas simplement un chatbot plus rapide. Son interface naturelle pourrait ressembler davantage à un éditeur intelligent qui révise un canevas, comble les lacunes et améliore les brouillons sur place. Cela pourrait changer la façon dont les utilisateurs perçoivent les outils d’écriture et de codage assistés par IA.
Conclusion finale
DiffusionGemma ne signifie pas que Google remplace aujourd’hui la prédiction du prochain jeton. Cela signifie que Google rend la diffusion de texte suffisamment pratique pour que les développeurs puissent la tester dans de véritables flux de travail.
Le changement important ne concerne pas seulement un texte généré plus rapidement. Il s’agit de l’idée que la génération de langage n’a pas toujours besoin de ressembler à un modèle qui tape de gauche à droite. Parfois, la meilleure interaction est un canevas qui s’affine en parallèle.
Si ce modèle s’améliore, la génération de texte par IA pourrait devenir plus rapide, plus interactive et mieux adaptée aux appareils locaux. Mais pour l’instant, DiffusionGemma doit être compris comme un modèle ouvert expérimental avec un message très clair : l’avenir de la génération de langage pourrait inclure plus d’une voie de décodage.
Comparaison rapide
Question | LLM autorégressifs | DiffusionGemma |
Schéma de génération | Prédit le jeton suivant de manière séquentielle | Affine un canevas de jetons en parallèle |
Point fort | Sorties de production de haute qualité | Génération interactive à faible latence |
Flux de contexte | Principalement de gauche à droite pendant le décodage | Bidirectionnel à l’intérieur de chaque canevas de débruitage |
Cas d’usage idéal | Chat général, raisonnement, service mature | Édition, complétion de code, flux de travail locaux rapides |
Statut | Paradigme dominant en production | Modèle ouvert expérimental |
CTA
Si vous développez des produits d’IA, ne considérez pas DiffusionGemma comme un simple modèle de remplacement. Considérez-le comme un nouveau schéma de génération à tester là où la latence d’inférence, la réactivité locale et l’édition non linéaire comptent le plus.
Pour les équipes qui développent des outils pour développeurs, des assistants d’écriture, des flux de travail de codage ou des expériences d’IA sur appareil, c’est le type d’architecture qu’il vaut la peine de comparer dès le début.
FAQ
Qu’est-ce que DiffusionGemma ?
DiffusionGemma est le modèle ouvert expérimental de génération de texte de Google qui utilise la diffusion discrète pour affiner des blocs de jetons en parallèle au lieu de s’appuyer uniquement sur une génération jeton par jeton.
Google remplace-t-il la prédiction du prochain jeton ?
Non. Google recommande toujours Gemma 4 standard pour une qualité de production maximale. DiffusionGemma est expérimental et optimisé pour les flux de travail où la vitesse est essentielle.
Pourquoi DiffusionGemma est-il plus rapide ?
Il travaille en parallèle sur un canevas de 256 jetons, en déplaçant davantage de travail vers le calcul GPU au lieu de générer strictement un jeton à la fois.
Qu’est-ce qu’un canevas de 256 jetons ?
Il s’agit d’un bloc de positions de jetons que le modèle initialise, débruite, affine, puis valide avant de passer au bloc suivant.
Qui devrait tester DiffusionGemma ?
Les développeurs travaillant sur l’inférence locale, l’édition en ligne, le remplissage de code, la rédaction rapide et d’autres outils d’IA interactifs à faible latence devraient y prêter attention.
Outils associés
- vLLM
- Colab
- Kaggle
Sources
- DeepMind


