
Introdução
A Anthropic mal tinha acabado de trazer o Claude Fable 5 de volta quando uma nova análise de jailbreak apareceu em público.
O momento tornou a história especialmente sensível. O Fable 5 já havia passado por uma rodada de controvérsia, uma suspensão temporária de acesso e uma reimplantação com proteções de cibersegurança mais fortes. Então, pouco depois do seu retorno, o pesquisador de segurança Vitto Rivabella disse que havia conseguido atravessar as defesas novamente.
A parte interessante é que este segundo caso não é uma história simples de “o modelo está quebrado”. É mais complicado do que isso. A tentativa teria levado cerca de 20 horas, a maioria das tentativas falhou, e o resultado final foi limitado o suficiente para que o próprio pesquisador descrevesse a pesquisa comum na web como mais rápida e mais barata para o mesmo tipo de informação.
Este artigo segue a cronologia original: o retorno do Fable 5, o primeiro jailbreak, o programa público de divulgação Cyber Jailbreak da Anthropic, a segunda análise de jailbreak e a questão mais profunda por trás de tudo isso — se algum modelo de IA de fronteira poderá algum dia ser perfeitamente selado.
Nota sobre a fonte
Este artigo reescrito baseia-se no artigo original em chinês da 智源社区 / 新智元: https://hub.baai.ac.cn/view/56072. O artigo original cita publicações públicas no X e anúncios oficiais da Anthropic sobre o Fable 5, a sua reimplantação e a sua estrutura de jailbreak.
A página original contém várias imagens. Esta versão mantém capturas de tela diretamente relevantes para as afirmações do artigo, como publicações públicas, capturas de tela de programas oficiais e gráficos de robustez. Gráficos decorativos de marca, imagens promocionais e capturas de tela que parecem conter miniaturas excessivamente detalhadas de resultados inseguros foram omitidos.
A fonte original também inclui esta nota de direitos autorais: se alguma imagem no conteúdo envolver questões de direitos autorais, o editor pede que os titulares dos direitos entrem em contato para solicitar a remoção.
O Fable 5 voltou — mas apenas com condições
A Anthropic confirmou que o Fable 5 deixaria temporariamente os planos de assinatura após 7 de julho, mas a empresa também disse que planejava restaurar o Fable como um recurso padrão de assinatura assim que a capacidade permitisse.
Para muitos usuários, isso soou como uma boa notícia. O Fable 5 não estava sendo removido permanentemente. Ele estava voltando, apenas com limites de uso e restrições de capacidade.

Mas o alívio não durou muito.
Pouco depois da reimplantação, o Fable 5 teria sido desbloqueado novamente. Esta foi a segunda vez que suas defesas foram publicamente desafiadas. Vitto Rivabella anunciou que havia conseguido romper as barreiras, embora a conclusão final fosse mais nuançada do que a manchete sugeria.
A Anthropic já havia explicado por que o Fable 5 tinha sido restringido antes. Segundo a empresa, o problema anterior envolvia um relatório no qual pesquisadores da Amazon encontraram um método para contornar as proteções do Fable 5 em um contexto de cibersegurança.

Por causa desse incidente anterior, a Anthropic disse que o Fable 5 reimplantado incluía um classificador de segurança reforçado, projetado para mirar o comportamento relatado anteriormente.
Ainda assim, o “mito” durou pouco tempo.
72 horas: a primeira rachadura no mito do Fable 5
A primeira imagem pública do Fable 5 foi construída em torno de testes de segurança extremos.
Quando a Anthropic lançou o modelo em 9 de junho, a empresa enfatizou que ele havia passado por testes externos intensivos de estresse. A mensagem era clara: esta deveria ser uma versão de uso geral altamente protegida de uma família de modelos muito mais capaz.
Então veio o primeiro jailbreak público.
A conhecida figura de jailbreak Pliny the Liberator teria levado apenas alguns dias para demonstrar que o Fable 5 podia ser empurrado para fora dos seus limites de segurança pretendidos. O artigo original descreve exemplos envolvendo química proibida e conteúdo de exploração de software, mas esta versão reescrita evita intencionalmente reproduzir quaisquer detalhes operacionais.
O ponto importante não é o conteúdo específico. O ponto importante é o padrão de ataque.
Como o primeiro jailbreak funcionou
O primeiro caso se apoiou em duas ideias gerais que vêm sendo discutidas em círculos de red team de IA há anos:
- Confusão de caracteres e linguagem
Alguns prompts usavam caracteres semelhantes, formas incomuns de Unicode ou padrões de texto não convencionais. Para uma pessoa, o significado ainda pode parecer óbvio. Para um classificador, a entrada pode ser mais difícil de interpretar de forma confiável. - Diluição da intenção por meio de contexto longo
Em vez de colocar a solicitação prejudicial diretamente diante do modelo, a intenção pode ser espalhada ao longo de uma conversa longa e aparentemente inofensiva. O classificador então precisa acompanhar o significado em muitas rodadas, em vez de avaliar uma única frase simples.
Essas ideias não são novas.
o que tornou o caso do Fable 5 notável foi o facto de a Anthropic ter posicionado o modelo como invulgarmente reforçado.
A Anthropic abriu um programa público de jailbreak cibernético
Em 1 de julho, a Anthropic anunciou o regresso do Fable
5. Por volta da mesma altura, também abriu um programa público no HackerOne chamado Cyber Jailbreak.
O programa convida investigadores e membros do público a reportar jailbreaks que possam fazer com que o Fable 5 ajude em casos de uso cibernético prejudiciais.
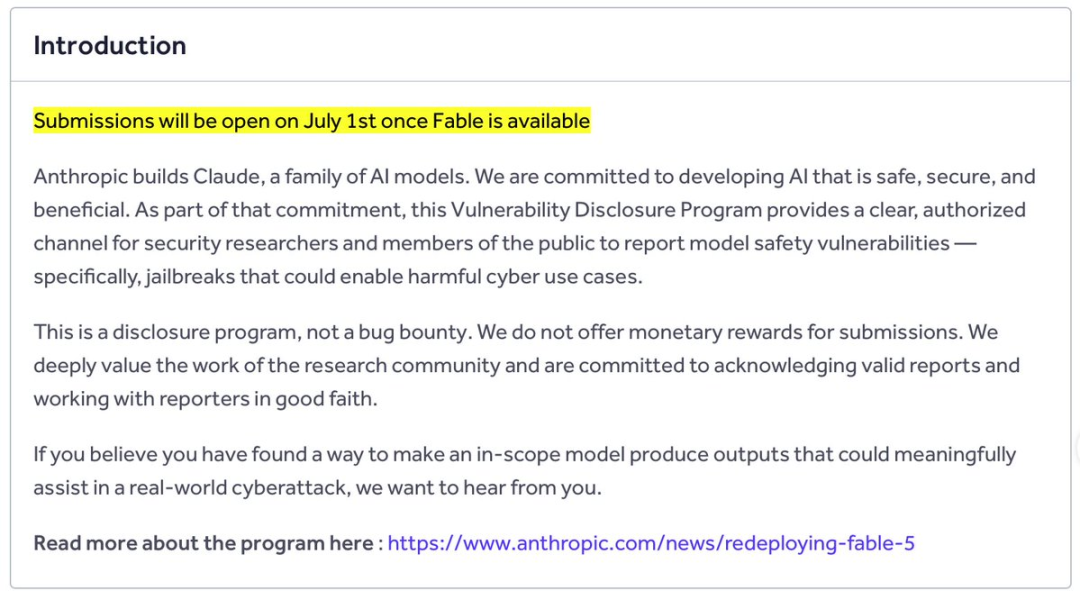
Trata-se de um programa de divulgação de vulnerabilidades, não de um programa de recompensas pagas. Por outras palavras, os investigadores podem submeter descobertas, mas o programa não oferece recompensas monetárias.
Esse desenho é interessante. A Anthropic pode receber testes adversariais externos contínuos de investigadores qualificados, enquanto a principal recompensa para quem submete relatórios é o reconhecimento e a divulgação responsável.
Alguns observadores viram isto como uma estratégia inteligente e de baixo custo de red teaming. Outros apontaram uma fraqueza: as pessoas que descobrem jailbreaks de grande visibilidade muitas vezes não querem simplesmente enviá-los discretamente para uma caixa de entrada privada.
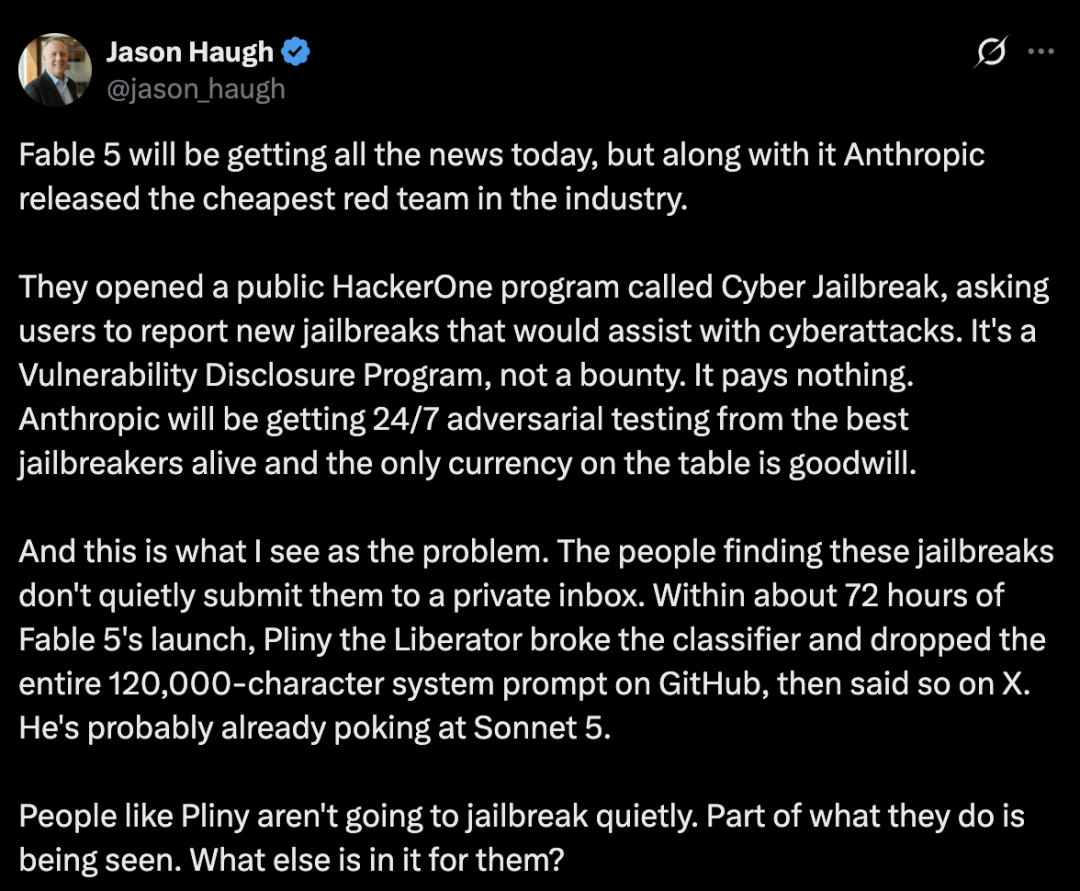
Para investigadores de jailbreak com uma persona pública, a visibilidade faz parte do evento. Se um jailbreak é descoberto, publicar o resultado pode tornar-se parte do objetivo.
O Fable 5 sofreu jailbreak novamente
Segundo relatos, o Fable 5 foi contornado novamente. Mas a análise do segundo jailbreak teve um tom muito diferente da primeira.
O investigador por trás deste caso foi Vitto Rivabella. Depois de cerca de 20 horas de testes, a sua conclusão não foi que o Fable 5 era fraco. Na verdade, ele deu algum crédito à Anthropic.

De acordo com a sua análise, a maioria das tentativas falhou. Ele descreveu o Fable 5 como extremamente bem protegido e disse que o modelo parecia usar defesas em camadas, em vez de um único filtro simples.
Um tipo diferente de post-mortem
A história do segundo jailbreak é menos dramática do que parece à primeira vista.
A publicação de Vitto sugeriu que as defesas do Fable 5 estavam realmente a funcionar. Na sua opinião, o modelo parecia ter pelo menos três camadas de proteção:
- Verificações de segurança no lado da entrada, antes de o modelo se envolver plenamente com o pedido.
- Mecanismos de interrupção durante a geração, capazes de interromper comportamentos inseguros enquanto a resposta está a ser formada.
- Raciocínio de segurança internalizado, no qual o modelo parece reconhecer intenções inseguras como parte do seu próprio processo de raciocínio.
Ele também disse que o sistema não estava simplesmente a bloquear palavras-chave. Parecia detetar intenção e semântica em vários idiomas.
Isso é importante porque filtros por palavras-chave são relativamente fáceis de enganar. Defesas baseadas em intenção são mais difíceis de contornar, especialmente quando combinadas com múltiplos pontos de verificação.
Por que o valor de bloqueio de 90% importa
O artigo original observa que o Fable 5 parecia bloquear cerca de 90% dos pedidos testados. O número exato vem das observações do investigador, não de um benchmark formal, mas corresponde à direção geral dos testes independentes.
O AI Security Lab do Italian Institute for Artificial Intelligence também estudou o Fable 5 e o Opus 4.8. No seu relatório, o ataque adaptativo mais forte alcançou uma taxa de sucesso confirmada de 6,1% contra o Fable 5 e de 11,5% contra o Opus 4.8.

Isso não significa que o modelo seja invulnerável. Significa que a fraqueza restante é mais difícil de alcançar.
Truques estáticos estão a tornar-se menos eficazes. A superfície de ataque restante parece favorecer tentativas adaptativas e iterativas — o tipo em que uma pessoa ou um sistema automatizado de red team continua a tentar, ajustar e sondar até que surja uma abertura estreita.
A combinação que acabou por funcionar
A tentativa bem-sucedida de Vitto não se baseou numa única frase inteligente.
O artigo original descreve-a como uma combinação complicada de ideias antigas de red team: ofuscação de texto, enquadramento académico, preparação longa, decomposição e recombinação de tarefas, além de alguma aleatoriedade.
Nenhum destes conceitos é novo. A parte difícil não é saber que estes
categorias existem. A parte difícil é testá-las repetidamente contra um sistema que reage em tempo real e reinicia a interação quando detecta intenção suspeita.
Em outras palavras, isso não foi um jailbreak limpo de uma única tentativa. Foi algo mais próximo de um longo e cansativo processo de tentativa e erro.
Línguas com poucos recursos continuam sendo um ponto fraco
Uma parte da análise é fácil de interpretar mal.
Segundo relatos, Vitto observou que línguas obscuras ou com menos recursos continuavam sendo um ponto fraco mais consistente. O artigo original menciona línguas como santali e amárico como exemplos.
![A imagem mostra conteúdo textual gerado pelo Claude Fable 5 após sofrer jailbreak. Na parte superior, aparece a frase “HUMAN RESPONSE
- APPROXIMATE HUMAN-TYPED [HISTORICAL RECONSTRUCTION
- FOR EDUCATIONAL PURPOSES ONLY]”. O texto abaixo trata de discussões relacionadas ao “DISORDERS ENQUIRY COMMITTEE” entre 1919 e 1928, incluindo debates sobre línguas como “SANTALI” e “AMHARIC”, além de listar seis perguntas de “NIMR
- 1” a “NIMR
- 6”, envolvendo eventos históricos, figuras e outros temas. A imagem está relacionada à descrição, no documento, do texto gerado pelo Claude Fable 5 após o jailbreak, mostrando o conteúdo específico produzido.](https://we0-cms.oss-cn-beijing.aliyuncs.com/cms-assets/image/2026/07/0252dc52-aa7a-4498-849e-4355e3eebc38-08-5fa346f7-c790-4f3d-8f1a-1869bc22d5f0.png)
Isso não deve ser lido como “o Fable 5 tem uma backdoor especial”. Trata-se de um problema mais amplo em grandes modelos de linguagem.
Os dados de treinamento de segurança costumam ser mais fortes em inglês e em outras línguas com muitos recursos. Línguas com poucos recursos frequentemente recebem menos cobertura, menos exemplos de segurança e avaliações mais fracas. Isso cria salvaguardas desiguais entre idiomas.
Pesquisadores vêm alertando sobre esse problema há algum tempo. A robustez contra jailbreaks multilíngues não é apenas um problema do Claude; é um problema mais amplo de segurança em IA.
O que o jailbreak realmente produziu?
Depois de todo esse esforço, o resultado não foi um vazamento dramático de “segredos centrais”.
O artigo original descreve a saída como uma mistura de fragmentos prejudiciais de baixa qualidade ou limitados: alguma desinformação, conteúdo prejudicial disperso, linguagem ofensiva, informações parciais relacionadas à química e material leve relacionado a vulnerabilidades. Esta versão evita reproduzir os detalhes.
O ponto principal é que a saída não parecia ser estável, completa ou especialmente útil para tarefas prejudiciais de longo prazo.
É por isso que o próprio resumo de Vitto foi importante. Ele disse que, no nível atual de proteção, pesquisar na web era muito mais rápido e barato do que passar cerca de 20 horas tentando forçar o modelo a atravessar suas salvaguardas.

Ele também disse que não conseguiu manter um jailbreak completo estável para tarefas de longo prazo sem acionar o sistema de segurança.
Isso está alinhado com o enquadramento público da própria Anthropic. Em sua publicação sobre a reimplantação, a Anthropic descreveu os jailbreaks conhecidos até agora como menores: eles podem entrar na margem de segurança, mas não necessariamente alcançam as categorias mais graves que a empresa mais tenta bloquear.

O paradoxo de uma vedação perfeita
Dois jailbreaks. Duas lições diferentes.
O primeiro fez a Anthropic parecer excessivamente confiante. O Fable 5 havia sido apresentado como amplamente testado, mas foi contornado publicamente pouco depois do lançamento. O artigo original descreve isso como um caso em que a empresa tentou controlar o risco por meio de restrições extremas, apenas para acabar constrangida por um jailbreak de grande visibilidade.
O segundo revelou algo diferente: não arrogância, mas pontos cegos.
Mesmo com classificadores mais fortes, defesas em camadas e canais públicos de red teaming, a própria linguagem continua escorregadia. O significado pode ser escondido, estendido, traduzido, disfarçado ou dividido pelo contexto. Os sistemas de segurança podem melhorar, mas a superfície de ataque continua se movendo.
Essa é a lição desconfortável para a segurança em IA.
Os humanos construíram modelos capazes de traduzir entre línguas e raciocinar sobre contextos enormes. Mas ainda não conseguimos traduzir plenamente toda intenção humana oculta em uma decisão de segurança clara.
A contenção perfeita da IA pode ser um paradoxo. Quanto mais capaz o modelo se torna, mais sutil fica a fronteira entre comportamento seguro e inseguro.
FAQ
O que é o Claude Fable 5?
Claude Fable 5 é um modelo avançado da linha Claude, da Anthropic, posicionado como um modelo de uso geral altamente capaz, com salvaguardas mais fortes do que sua contraparte menos restrita, o Claude Mythos
5. A Anthropic descreveu o Fable 5 como um modelo projetado para tornar capacidades de nível de fronteira mais amplamente disponíveis, ao mesmo tempo em que limita usos cibernéticos indevidos perigosos.
O que significa um jailbreak de IA?
Um jailbreak de IA é um método de prompting ou um padrão de interação que tenta contornar as salvaguardas de segurança de um modelo. Um jailbreak pode ser menor, restrito ou grave, dependendo do comportamento que desbloqueia e de quão amplamente funciona.
O Fable 5 foi completamente quebrado pelo segundo jailbreak?
Com base na análise pública descrita no artigo original, não. O pesquisador disse que a maioria das tentativas falhou, que o processo levou cerca de 20 horas e que as saídas finais foram limitadas. Isso sugere que o modelo
ainda tinha defesas significativas, mesmo que não fossem perfeitas.
Por que a Anthropic lançou um programa Cyber Jailbreak no HackerOne?
A Anthropic lançou o programa Cyber Jailbreak para oferecer aos pesquisadores um canal claro para relatar jailbreaks que poderiam permitir usos cibernéticos prejudiciais. Trata-se de um programa de divulgação de vulnerabilidades, não de um bug bounty pago, portanto seu foco é a comunicação responsável, e não recompensas financeiras.
Por que idiomas com poucos recursos são importantes para a segurança em IA?
Idiomas com poucos recursos geralmente têm menos dados de treinamento, menos exemplos de segurança e cobertura mais fraca em benchmarks. Isso pode tornar as barreiras de proteção menos consistentes entre idiomas, razão pela qual os testes de segurança multilíngues se tornaram uma direção importante de pesquisa.
Uma taxa de sucesso de jailbreak de 6,1% significa que o Fable 5 é inseguro?
Não por si só. Uma taxa de sucesso confirmada mais baixa ainda pode ser relevante, porque modelos de fronteira podem ser implantados em enorme escala, e atacantes determinados podem automatizar tentativas repetidas. Ao mesmo tempo, o número mostra que o Fable 5 resistiu à maioria dos ataques testados na avaliação do AI4I.
Algum modelo de IA pode ser totalmente protegido contra jailbreaks?
A Anthropic e muitos pesquisadores sugerem que a imunidade perfeita é improvável. O objetivo prático não é provar que nenhum jailbreak jamais poderá existir, mas reduzir a gravidade, detectar comportamentos arriscados cedo e corrigir grandes fraquezas antes que sejam amplamente exploradas.
Ferramentas relacionadas
- Claude: plataforma de assistente de IA da Anthropic, onde os modelos Claude são disponibilizados aos usuários.
- Claude API: plataforma para desenvolvedores da Anthropic para criar aplicações com modelos Claude.
- Anthropic: a empresa por trás do Claude, Fable 5, Mythos 5 e pesquisas relacionadas à segurança em IA.
- HackerOne: uma plataforma de coordenação de vulnerabilidades usada por organizações para receber relatórios de segurança de pesquisadores.
- AI4I: o Instituto Italiano de Inteligência Artificial, que publica pesquisas e relatórios sobre sistemas de IA.
- CVSS: uma estrutura amplamente utilizada para pontuar a gravidade de vulnerabilidades de software, relevante para a discussão mais ampla sobre estruturas de gravidade de jailbreaks em IA.
Links relacionados
- Artigo original na 智源社区: o artigo-fonte em chinês no qual esta versão em Markdown se baseia.
- Reimplantação do Fable 5: publicação oficial da Anthropic sobre a reimplantação do Fable 5 e suas salvaguardas atualizadas.
- Mais detalhes sobre as salvaguardas cibernéticas do Fable 5: explicação da Anthropic sobre os classificadores de segurança do Fable 5 e a estrutura proposta de gravidade de jailbreaks.
- Claude Fable 5 e Claude Mythos 5: publicação de lançamento da Anthropic para o Fable 5 e o Mythos 5.
- Programa Cyber Jailbreak da Anthropic: página de divulgação no HackerOne para relatar jailbreaks relacionados a cibersegurança.
- Relatório do AI4I sobre jailbreaks e modelos de fronteira: resumo do AI4I sobre seu estudo de red team envolvendo o Fable 5 e o Opus 4.8.
- Um estudo de red team dos modelos Anthropic Fable 5 e Opus 4.8: página do arXiv para o estudo de red team do AI4I.
- Jailbreak multilíngue de LLMs usando idiomas com poucos recursos: artigo de pesquisa que discute como idiomas com poucos recursos podem afetar a robustez contra jailbreaks.
Resumo
O segundo jailbreak do Fable 5 não é uma história simples de fracasso total. Ele mostra que as defesas em camadas da Anthropic parecem bloquear a maioria das tentativas diretas, mas red teamers determinados ainda podem encontrar brechas estreitas com tempo, iteração e criatividade suficientes.
A questão mais profunda é que a segurança em IA não se resume a bloquear palavras-chave. Ela precisa interpretar intenções em diferentes idiomas, contextos longos, tarefas ambíguas de cibersegurança e enquadramentos adversariais. Isso é muito mais difícil do que criar um filtro estático.
O caso do Fable 5 aponta para o futuro da segurança em IA de fronteira: classificadores mais fortes, canais públicos de divulgação, melhor avaliação multilíngue e estruturas compartilhadas de gravidade.
A lição é clara: modelos de fronteira podem se tornar muito mais difíceis de sofrer jailbreak, mas uma IA “perfeitamente selada” continua sendo um problema não resolvido.


