
Введение
DSpark от DeepSeek был открыт всего около недели назад, когда сообщество уже перенесло его на компьютеры Apple.
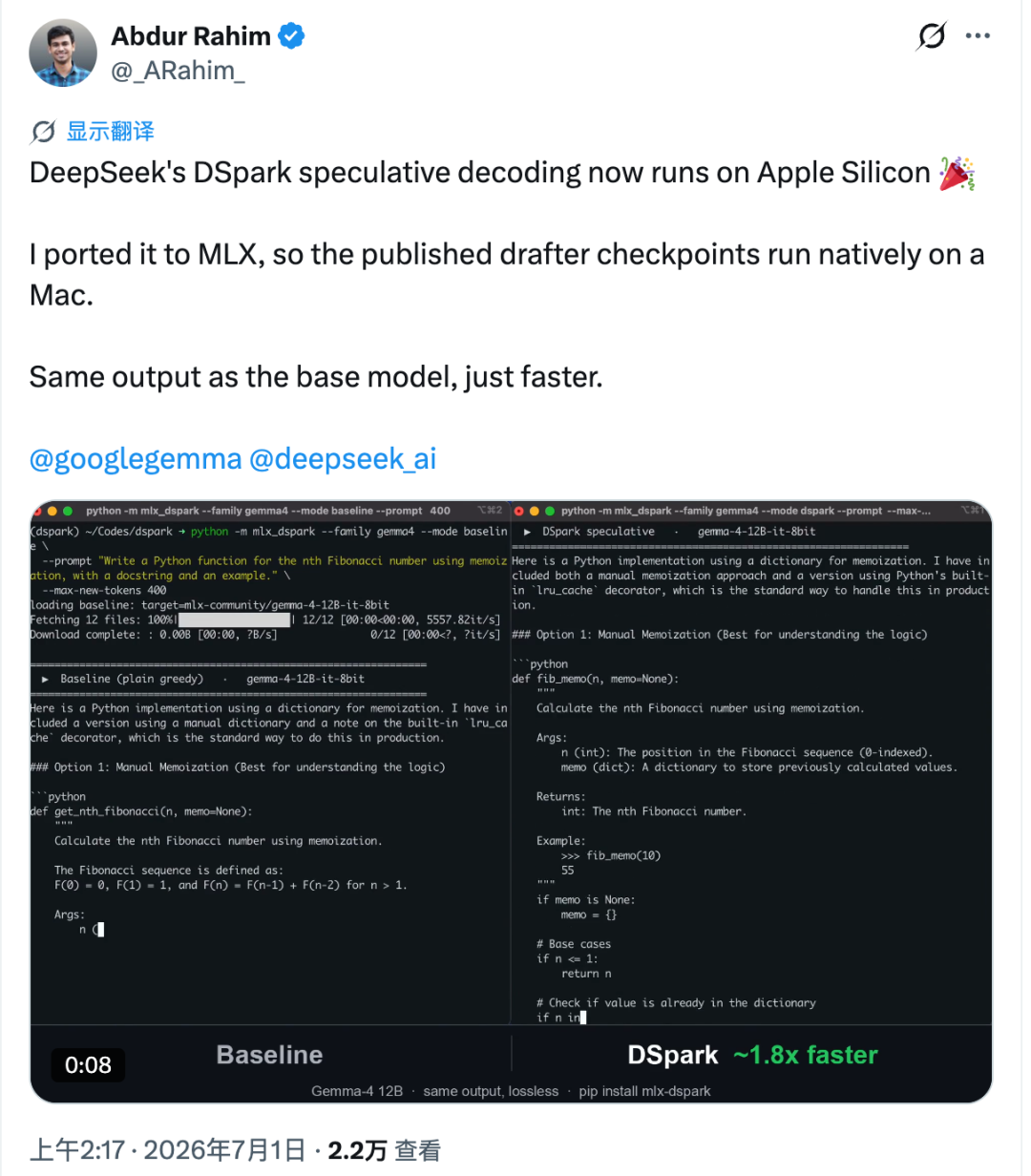
Порт называется mlx-dspark. Он запускает спекулятивное декодирование в стиле DSpark нативно на Apple Silicon через экосистему Apple MLX; тесты проводились на таких моделях, как Gemma-4 12B и Qwen3-4B. В опубликованных бенчмарках для Mac генерация Gemma-4 12B стала примерно в 1,6 раза быстрее, а Qwen3-4B ускорилась примерно в 1,4 раза.
Особый интерес здесь представляет не только скорость. Порт нацелен на сохранение соответствия генерируемого вывода базовой целевой модели, то есть ускорение достигается не за счет простого изменения поведения модели.
Источник и примечания к изображениям
- Исходная статья: Новая технология DeepSeek перенесена на чипы Apple! Локальные большие модели на Mac ускорены на 60%
- Примечание об исходном источнике на странице: статья была перепубликована из WeChat / QbitAI.
- Эта Markdown-версия представляет собой SEO-готовую англоязычную адаптацию на основе фактов из источника и публичных страниц проекта. Это не построчный полный перевод оригинальной статьи.
- Исходная статья не содержала исполняемых командных блоков или конфигурационных файлов. Поэтому никакие блоки кода не удалялись и не изменялись.
- Изображения ниже — это релевантные к основному тексту скриншоты из исходной статьи. QR-коды, призывы подписаться, интерфейс комментариев и декоративные элементы платформы не включались как самостоятельный контент.
Apple Silicon теперь может запускать локальное ускорение LLM в стиле DSpark
DeepSeek выпустила DSpark 27 июня как подход к спекулятивному декодированию. В исходном серверном сценарии DSpark описывался как способ повысить скорость генерации примерно на 60–85% при определенных условиях обслуживания.
Однако сначала доступная реализация была ориентирована на GPU-среды дата-центров. Это не был нативный рабочий процесс для Apple Silicon. Ситуация изменилась с появлением mlx-dspark — реализации, созданной Abdur Rahim для инференса на Mac на базе MLX.

Идею DSpark на высоком уровне понять довольно просто:
- Меньшая draft-модель заранее предлагает несколько кандидатных токенов.
- Более крупная целевая модель проверяет эти токены.
- Принятые токены сохраняются.
- Отклоненные токены заново генерируются обычным путем целевой модели.
Это и есть суть спекулятивного декодирования: позволить более дешевой draft-ветке угадывать наперед, а затем дать целевой модели проверить корректность.
На серверных GPU проверка группы токенов может быть относительно эффективной, поскольку узким местом часто является перемещение данных в памяти, а не чистые вычисления. В таких условиях проверка нескольких дополнительных токенов может не добавлять большой стоимости.
Apple Silicon ведет себя иначе. На Mac каждый дополнительный проверяемый токен может вносить более заметную задержку. Rahim измерил эту стоимость и оценил, что на Apple Silicon верхний предел ускорения для такого стиля составляет около 2,2 раза в протестированных условиях.
Чтобы сделать это практичным, он перенес draft-чекпойнты из Hugging Face в рабочий процесс MLX и связал их с целевыми моделями Gemma-4 12B и Qwen3-4B. Поток верификации был заново построен внутри MLX, а draft-веса были квантованы до 4 бит.

В опубликованных тестах на M4 Pro по сравнению с официальными инструментами MLX от Apple:
- Gemma-4 12B выросла примерно с 18,4 ток/с до около 30 ток/с, то есть стала примерно в 1,6 раза быстрее.
- Qwen3-4B выросла примерно с 52,9 ток/с до около 73 ток/с, то есть стала примерно в 1,4 раза быстрее.
Для разработчиков локального ИИ это существенный прирост. MacBook все еще не является сервером инференса уровня дата-центра, но оптимизация такого рода делает более крупные локальные модели заметно удобнее для разработки, тестирования и персональных рабочих процессов.
Порт также сосредоточен на высокой точности вывода
Многие локальные порты ускорения больших моделей сначала фокусируются на greedy-декодировании. При greedy-декодировании модель просто выбирает токен с наибольшей вероятностью на каждом шаге. Это упрощает проверку корректности, поскольку вывод можно сравнивать токен за токеном.
mlx-dspark идет дальше, реализуя метод температурной выборки, описанный в статье DSpark. Draft-модель предлагает токены, а целевая модель принимает их по правилу, основанному на вероятностях. Отклоненные части заново сэмплируются из
оставшееся распределение.
Это важно, потому что сэмплирование используется во многих реальных приложениях. Чат-интерфейсы, творческое письмо, исследование агентами и генерация рекламных текстов часто полагаются на temperature, а не на строгое жадное декодирование.
Рахим проверил, что поток сэмплирования сохраняет распределение целевой модели при той же настройке temperature. Иными словами, цель состоит не в том, чтобы получить «достаточно похожее» приближение. Порт спроектирован так, чтобы ускорение не меняло предполагаемое поведение вывода модели.
Во время портирования также было получено несколько практических выводов:
- Если черновая модель сопряжена с базовой целевой моделью вместо соответствующей instruction-tuned целевой модели, доля принятия может резко снизиться.
- В описанном тесте переход на соответствующую instruction-tuned целевую модель повысил долю принятия примерно с 47% до примерно 82%.
- Использование bf16 для целевой модели увеличило стоимость верификации сильнее, чем улучшило принятие, поэтому 8-битная конфигурация целевой модели оказалась более практичной в этом рабочем процессе на Mac.
- Черновая модель была сжата до 4 бит и уменьшена примерно до 1,8 ГБ, что облегчило ее удержание в памяти на локальных машинах.
В результате получилась локальная реализация, которая не просто работает быстрее. Она также старается сохранить поведение, которого пользователи ожидают от исходной целевой модели.
DFlash также был интегрирован для ускорения задач по коду и математике
После того как публикация о mlx-dspark привлекла внимание, в обсуждение вошел DFlash. Цзянь Чэнь, один из авторов DFlash, спросил, можно ли протестировать модель DFlash в той же конфигурации Mac.
DFlash — еще один подход к спекулятивному декодированию от z-lab. Его архитектура отличается от DSpark. Вместо того чтобы генерировать токены-кандидаты шаг за шагом с более сильной обработкой зависимостей, DFlash использует метод в стиле блочной диффузии, чтобы параллельно очищать от шума целый блок токенов.
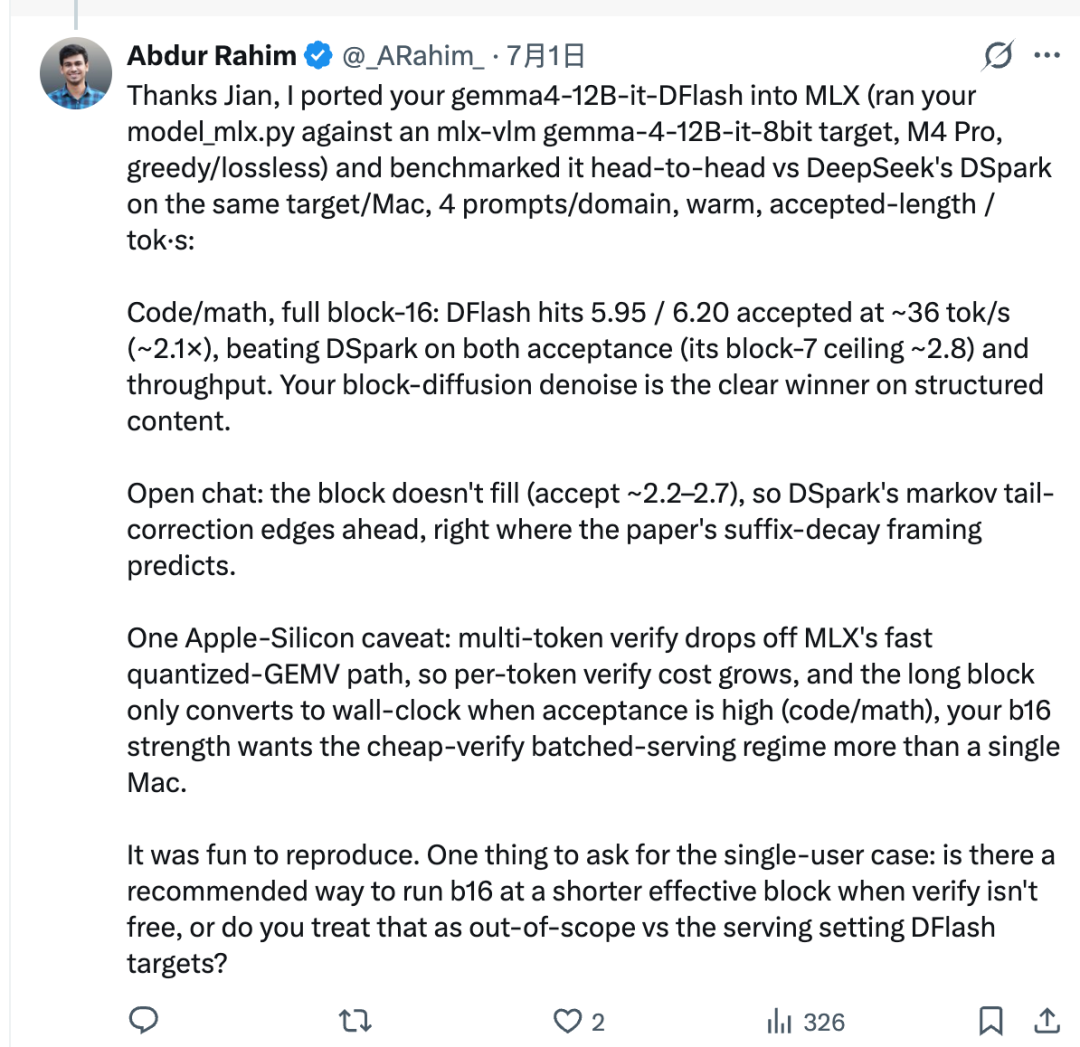
В протестированной конфигурации Рахим использовал скрипт портирования Цзяня, чтобы подключить z-lab/gemma4-12B-it-DFlash к целевой модели Gemma-4 на базе MLX. Затем он сравнил DFlash и DSpark на том же Mac.
В структурированных задачах, таких как код и математика, DFlash показал очень хорошие результаты. Его принятая длина достигала примерно 5,95–6,20, а пропускная способность — около 36 ток/с, что в описанной конфигурации составляет примерно 2,1×.

Это не означает, что DFlash всегда лучше. DFlash формирует черновик сразу полного блока из 16 токенов, но целевая модель не всегда принимает весь блок. Количество принятых токенов называется принятой длиной.
В открытом чате следующие токены сложнее предсказать. Принятая длина может оставаться ниже, а значит полный блок из 16 токенов не превращается в реальное преимущество по скорости. В такой конфигурации DSpark может быть быстрее, потому что его марковская голова разработана для снижения проблемы «затухания суффикса», которая часто возникает при параллельном черновом построении токенов.
В более позднем обновлении mlx-dspark исходный путь DFlash от z-lab был добавлен прямо в пакет. Также был добавлен параметр для настройки эффективной длины блока. Это дает пользователям более гибкий выбор:
- Использовать более короткие блоки для задач, похожих на чат.
- Использовать полный блок из 16 токенов для задач по коду и математике.
- Сравнивать DSpark и DFlash в одном пакете вместо переключения между отдельными проектами.
Это делает mlx-dspark менее похожим на эксперимент с одним методом и более похожим на практичный локальный инструментарий инференса для пользователей Apple Silicon.
Почему это важно для локальной разработки ИИ
Локальные рабочие процессы с LLM становятся все более распространенными среди разработчиков, исследователей и небольших команд. Запуск моделей локально дает больше контроля над задержкой, обработкой данных, экспериментами и офлайн-сценариями.
Но у локального инференса часто есть одно болезненное ограничение: скорость. Даже когда модель помещается в память, генерация может ощущаться медленной.
mlx-dspark интересен тем, что решает эту проблему, не требуя полностью новой целевой модели. Он использует спекулятивное декодирование, чтобы существующая модель ощущалась быстрее, при этом по-прежнему позволяя целевой модели проверять вывод.
Для разработчиков, создающих локальные AI-приложения на Mac, это может быть полезно в нескольких сценариях:
- Тестирование ИИ
функции перед переходом к серверному инференсу.
2. Запуск локальных ассистентов для программирования или работы с документами.
3. Сравнение стратегий декодирования для разных типов задач.
4. Создание легковесных локальных сервисов, совместимых с OpenAI.
5. Оценка того, достаточно ли менее мощной конфигурации Mac для конкретного прототипа.
Компромисс по-прежнему важен. Метод, который хорошо работает с кодом и математикой, может быть не лучшим выбором для открытого диалога. Метод, который хорошо показывает себя на M4 Pro, может вести себя иначе на более старых чипах Apple Silicon или на машинах с ограниченным объемом памяти.
Поэтому практический вывод состоит не в том, что «один метод побеждает везде». Он в том, что у Apple Silicon теперь есть более сильная основа для экспериментов с DSpark, DFlash и нативным для MLX спекулятивным декодированием.
FAQ
Что такое DSpark?
DSpark — это метод спекулятивного декодирования, связанный с проектом DeepSpec от DeepSeek. Он использует черновую модель, чтобы заранее предлагать токены, а целевая модель проверяет их, что позволяет ускорить инференс при сохранении поведения вывода.
Что такое mlx-dspark?
mlx-dspark — это реализация сообщества, которая переносит спекулятивное декодирование в стиле DSpark и DFlash на Apple Silicon через MLX. Она позволяет поддерживаемым целевым моделям Gemma и Qwen работать на Mac с ускорением за счет черновой модели.
Запускает ли mlx-dspark DeepSeek-V4 локально?
Нет. Проект mlx-dspark поясняет, что его локальные целевые модели для Mac — это плотные модели, такие как Gemma и Qwen, а не сам DeepSeek-V4. Он использует метод чернового декодера DSpark от DeepSeek, но целевая модель, генерирующая токены в рабочем процессе на Mac, — это Gemma или Qwen.
Насколько быстрее DSpark на Mac?
В опубликованных тестах Gemma-4 12B улучшила скорость примерно с 18,4 ток/с до примерно 30 ток/с, а Qwen3-4B — примерно с 52,9 ток/с до примерно 73 ток/с. Фактическая скорость зависит от чипа Mac, модели, точности, типа промпта и настроек декодирования.
Что такое DFlash?
DFlash — это метод блочно-диффузионного спекулятивного декодирования от z-lab. Он параллельно создает черновой блок токенов и может быть особенно эффективен в структурированных задачах, таких как код и математика, когда принятая длина велика.
DSpark лучше, чем DFlash?
Не всегда. DFlash может работать лучше в задачах программирования и математики, тогда как DSpark может быть сильнее в открытом чате, где длинные параллельные блоки труднее предсказывать. Лучший выбор зависит от целевой модели и типа задачи.
Нужен ли Apple Silicon для использования mlx-dspark?
mlx-dspark разработан для Apple Silicon через MLX, поэтому предполагаемой средой является Mac с Apple Silicon. Также требуется совместимая среда Python и поддерживаемые веса моделей из Hugging Face или локальных путей.
Подходит ли спекулятивное декодирование для продакшена?
Может подходить, но использование в продакшене требует тщательного бенчмаркинга. Прежде чем полагаться на него, необходимо проверить точность соответствия вывода, принятую длину, задержку, поведение при батчинге, использование памяти, совместимость моделей и производительность на конкретном оборудовании.
Связанные инструменты
- mlx-dspark: проект сообщества, который запускает спекулятивное декодирование DSpark и DFlash нативно на Apple Silicon через MLX.
- DeepSpec: полнофункциональная кодовая база DeepSeek для обучения и оценки черновых моделей спекулятивного декодирования.
- MLX: фреймворк машинного обучения Apple, разработанный для эффективной работы на Apple Silicon.
- z-lab/gemma4-12B-it-DFlash: черновая модель DFlash для рабочих процессов Gemma-4 12B, настроенных под инструкции.
- Hugging Face: платформа хостинга моделей, используемая проектами и контрольными точками, упомянутыми в этой статье.
- Организация DeepSeek на Hugging Face: официальная организация DeepSeek на Hugging Face для публикации моделей и контрольных точек.
Связанные ссылки
- Исходная статья на BAAI Hub: оригинальная статья на китайском языке, в которой был представлен порт mlx-dspark для Apple Silicon.
- Оригинальный пост Абдура Рахима в X: упомянутый пост с анонсом запуска DSpark на Apple Silicon.
- GitHub-репозиторий mlx-dspark: установка, использование, поддерживаемые модели и заметки о бенчмарках для реализации под Apple Silicon.
- GitHub-репозиторий DeepSpec: официальный репозиторий DeepSeek для алгоритмов спекулятивного декодирования и опубликованных контрольных точек.
- PDF статьи о DSpark: техническая статья, включенная в репозиторий DeepSpec.
- Коллекция DFlash на Hugging Face: коллекция z-lab для черновых моделей, связанных с DFlash.
- Документация MLX: официальная документация фреймворка Apple MLX.
- GitHub-репозиторий MLX: исходный репозиторий фреймворка машинного обучения для Apple Silicon.
Резюме
В этой статье объясняется, как метод спекулятивного декодирования DSpark от DeepSeek был перенесен на Apple Silicon через mlx-dspark, что ускорило локальный инференс на Mac для поддерживаемых моделей Gemma и Qwen.
Ключевой момент в том, что портирование касается не только чистой скорости. Оно также сосредоточено на сохранении точности вывода, позволяя целевой модели проверять сгенерированные токены, включая поддержку поведения декодирования с выборкой.
Интеграция DFlash добавляет еще один полезный вариант,
особенно для задач, связанных с кодом и математикой, где подготовка длинных блоков может окупиться. Для открытого чата DSpark всё ещё может быть более подходящим вариантом, поскольку поддерживать приемлемую длину сложнее.
Для локальной разработки ИИ на Mac mlx-dspark даёт пользователям Apple Silicon практичный способ протестировать более быстрый инференс LLM, не перенося всё на сервер.


