
Introdução
O DSpark da DeepSeek estava em código aberto havia apenas cerca de uma semana quando a comunidade o levou para computadores Apple.
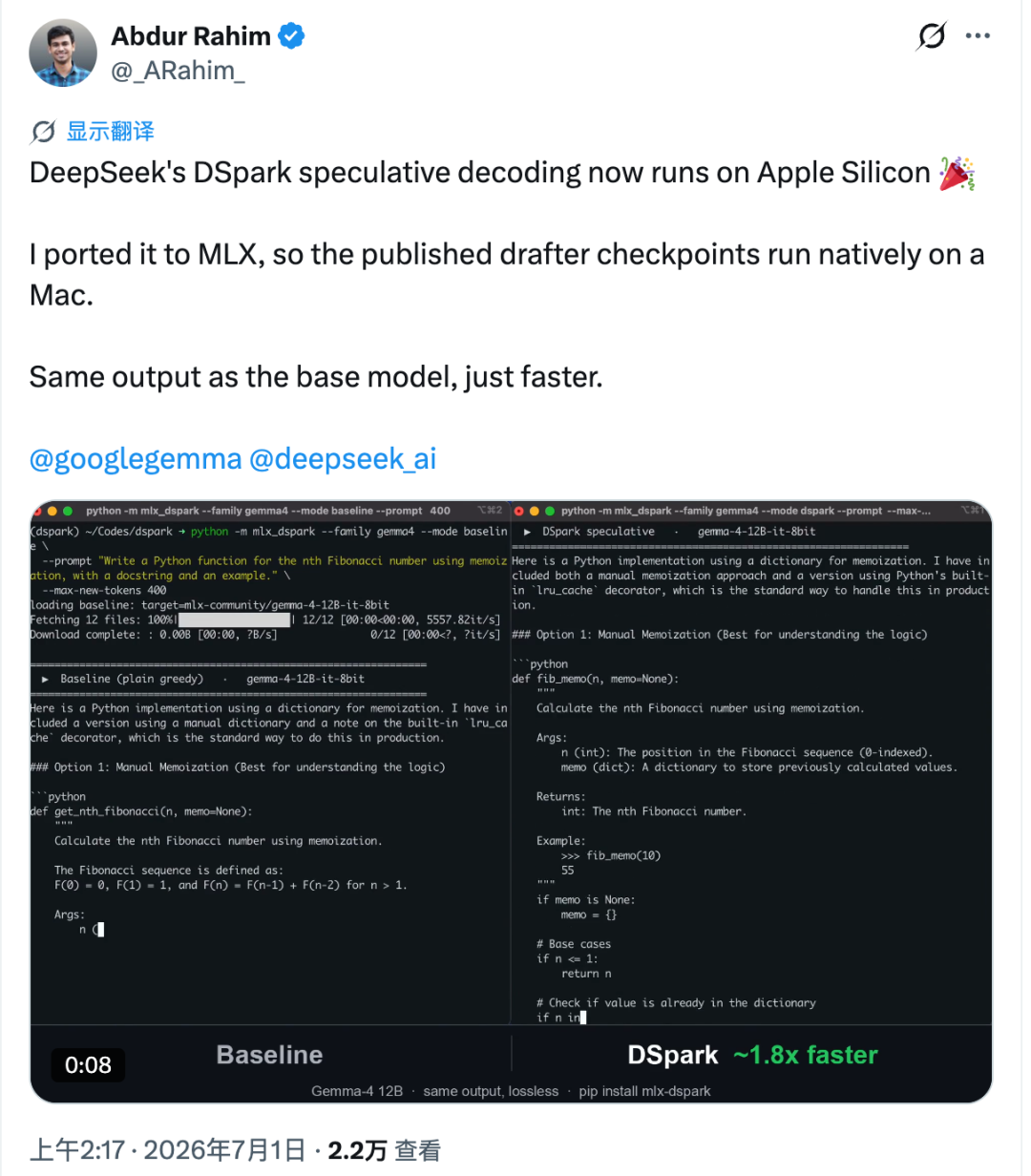
O port se chama mlx-dspark. Ele executa decodificação especulativa no estilo DSpark de forma nativa no Apple Silicon por meio do ecossistema MLX da Apple, com testes em modelos como Gemma-4 12B e Qwen3-4B. Nos benchmarks reportados no Mac, a geração com o Gemma-4 12B ficou cerca de 1,6× mais rápida, enquanto o Qwen3-4B melhorou cerca de 1,4×.
O que torna isso mais interessante não é apenas a velocidade. O port busca manter a saída gerada alinhada com o modelo-alvo base, de modo que a aceleração não seja obtida simplesmente alterando o comportamento do modelo.
Fonte e notas sobre as imagens
- Artigo-fonte: Nova tecnologia da DeepSeek é portada para chips Apple! Modelos grandes locais no Mac aceleram 60%
- Nota da fonte original na página: o artigo foi republicado a partir do WeChat / QbitAI.
- Esta versão em Markdown é uma adaptação em inglês pronta para SEO, baseada nos fatos da fonte e em páginas públicas do projeto. Não é uma tradução integral linha por linha do artigo original.
- O artigo-fonte não continha blocos de comandos executáveis nem arquivos de configuração. Portanto, nenhum bloco de código foi removido ou alterado.
- As imagens incluídas abaixo são capturas de tela relevantes ao corpo do texto do artigo-fonte. QR codes, chamadas para seguir, interface de comentários e elementos decorativos da plataforma não foram incluídos como conteúdo independente.
O Apple Silicon agora pode executar aceleração local de LLM no estilo DSpark
A DeepSeek lançou o DSpark em 27 de junho como uma abordagem de decodificação especulativa. Em seu cenário original do lado do servidor, o DSpark foi descrito como uma forma de aumentar a velocidade de geração em cerca de 60% a 85% sob condições específicas de serviço.
No início, porém, a implementação disponível se concentrava em ambientes de GPU de data center. Não era um fluxo de trabalho nativo para Apple Silicon. Isso mudou com o mlx-dspark, uma implementação criada por Abdur Rahim para inferência baseada em MLX no Mac.

A ideia por trás do DSpark é fácil de entender em alto nível:
- Um modelo de rascunho menor propõe antecipadamente vários tokens candidatos.
- O modelo-alvo maior verifica esses tokens.
- Os tokens aceitos são mantidos.
- Os tokens rejeitados são regenerados pelo caminho normal do modelo-alvo.
Esse é o núcleo da decodificação especulativa: permitir que um caminho de rascunho mais barato antecipe palpites e, em seguida, deixar que o modelo-alvo verifique a correção.
Em GPUs de servidor, verificar um grupo de tokens pode ser relativamente eficiente porque o gargalo costuma estar mais no movimento de memória do que na computação pura. Nesse cenário, verificar alguns tokens extras pode não adicionar muito custo.
O Apple Silicon se comporta de maneira diferente. Em um Mac, cada token adicional verificado pode acrescentar uma latência mais perceptível. Rahim mediu esse custo e estimou que, no Apple Silicon, o limite superior de velocidade para esse estilo de aceleração é de cerca de 2,2× nas condições testadas.
Para tornar isso prático, ele transferiu os checkpoints de rascunho do Hugging Face para um fluxo de trabalho em MLX e os combinou com os modelos-alvo Gemma-4 12B e Qwen3-4B. O fluxo de verificação foi reconstruído dentro do MLX, e os pesos do modelo de rascunho foram quantizados para 4 bits.

Nos testes reportados com o M4 Pro, em comparação com as ferramentas oficiais MLX da Apple:
- Gemma-4 12B aumentou de cerca de 18,4 tok/s para aproximadamente 30 tok/s, ficando cerca de 1,6× mais rápido.
- Qwen3-4B aumentou de cerca de 52,9 tok/s para aproximadamente 73 tok/s, ficando cerca de 1,4× mais rápido.
Para desenvolvedores de IA local, esse é um ganho significativo. Um MacBook ainda não é um servidor de inferência de data center, mas esse tipo de otimização torna modelos locais maiores mais usáveis para desenvolvimento, testes e fluxos de trabalho pessoais.
O port também se concentra em saída de alta fidelidade
Muitos ports locais de aceleração de modelos grandes se concentram primeiro na decodificação gulosa. Na decodificação gulosa, o modelo simplesmente escolhe o token de maior probabilidade em cada etapa. Isso facilita testar a correção, porque a saída pode ser comparada token por token.
O mlx-dspark vai além ao implementar o método de amostragem com temperatura descrito no artigo do DSpark. O modelo de rascunho propõe tokens, e o modelo-alvo os aceita usando uma regra baseada em probabilidade. As partes rejeitadas são reamostradas a partir de
a distribuição restante.
Isso importa porque a amostragem é o que muitas aplicações reais usam. Interfaces de chat, escrita criativa, exploração por agentes e geração de textos para produtos frequentemente dependem da temperatura, em vez de uma decodificação gulosa estrita.
Rahim verificou que o fluxo de amostragem preserva a distribuição do modelo-alvo sob a mesma configuração de temperatura. Em outras palavras, o objetivo não é produzir uma aproximação “suficientemente semelhante”. A adaptação foi projetada para que a aceleração não altere o comportamento de saída pretendido pelo modelo.
Também houve algumas lições práticas durante a adaptação:
- Se o modelo de rascunho for pareado com um modelo-alvo base em vez do modelo-alvo correspondente ajustado por instruções, a taxa de aceitação pode cair drasticamente.
- No teste relatado, mudar para o alvo correspondente ajustado por instruções aumentou a taxa de aceitação de cerca de 47% para cerca de 82%.
- Usar bf16 para o modelo-alvo aumentou o custo de verificação mais do que melhorou a aceitação, então a configuração do alvo em 8 bits foi mais prática nesse fluxo de trabalho no Mac.
- O modelo de rascunho foi comprimido para 4 bits e reduzido para cerca de 1,8 GB, tornando-o mais fácil de manter na memória em máquinas locais.
O resultado é uma implementação local que faz mais do que simplesmente rodar mais rápido. Ela também tenta preservar o comportamento que os usuários esperam do modelo-alvo original.
O DFlash também foi integrado para acelerar tarefas de código e matemática
Depois que a publicação sobre o mlx-dspark chamou atenção, o DFlash entrou na discussão. Jian Chen, um dos autores por trás do DFlash, perguntou se o modelo DFlash poderia ser testado na mesma configuração de Mac.
O DFlash é outra abordagem de decodificação especulativa da z-lab. Seu design difere do DSpark. Em vez de gerar tokens candidatos passo a passo com um tratamento mais forte das dependências, o DFlash usa um método em estilo de difusão em bloco para remover ruído de um bloco inteiro de tokens em paralelo.
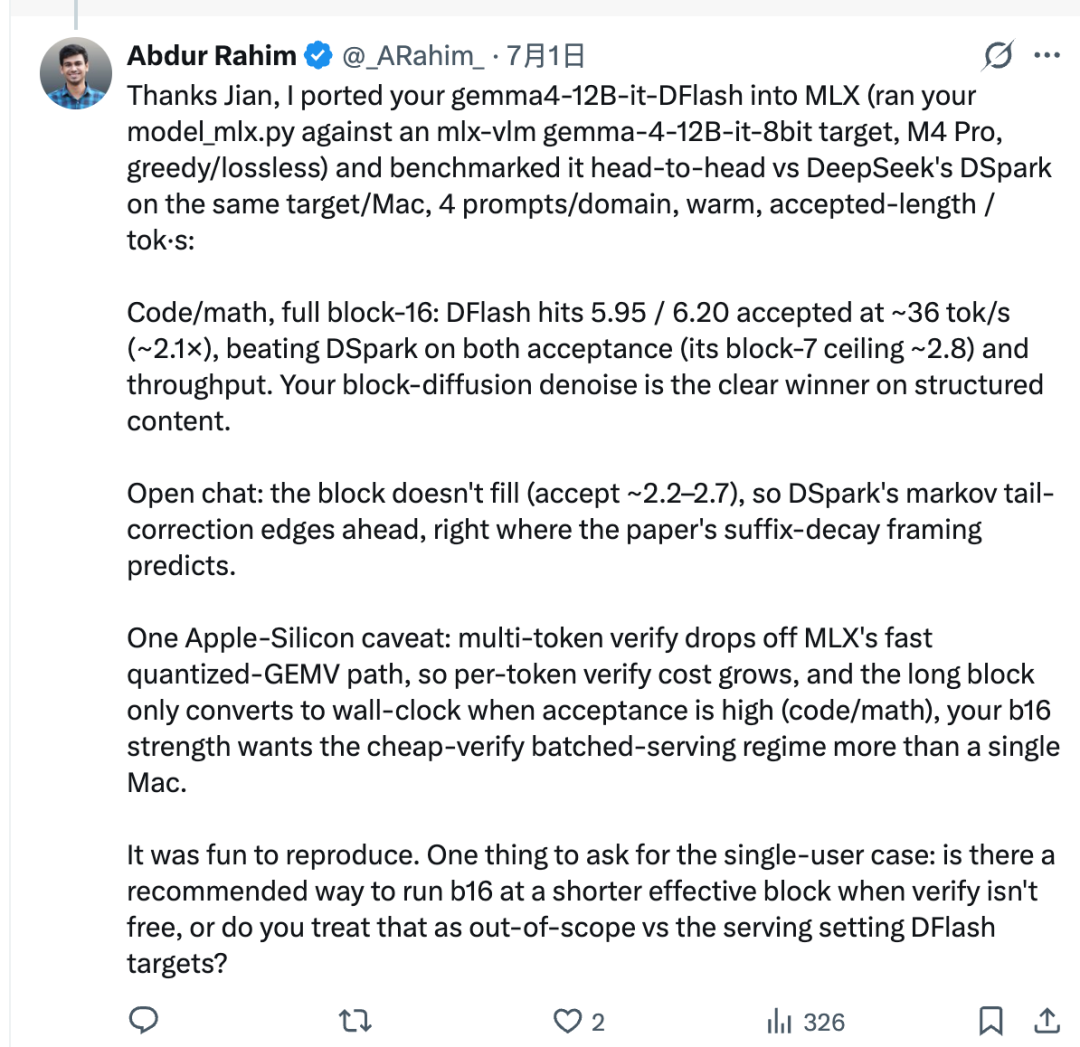
Na configuração testada, Rahim usou o script de adaptação de Jian para conectar o z-lab/gemma4-12B-it-DFlash ao modelo-alvo Gemma-4 baseado em MLX. Em seguida, ele comparou o DFlash e o DSpark no mesmo Mac.
Para tarefas estruturadas, como código e matemática, o DFlash teve um desempenho muito bom. Seu comprimento aceito chegou a cerca de 5,95 a 6,20, e a taxa de transferência atingiu cerca de 36 tok/s, aproximadamente 2,1× na configuração relatada.

Isso não significa que o DFlash seja sempre melhor. O DFlash rascunha um bloco completo de 16 tokens de uma vez, mas o modelo-alvo nem sempre aceita o bloco inteiro. O número de tokens aceitos é chamado de comprimento aceito.
Em chats abertos, os próximos tokens são mais difíceis de prever. O comprimento aceito pode permanecer mais baixo, o que significa que o bloco completo de 16 tokens não se traduz em uma vantagem real de velocidade. Nesse tipo de configuração, o DSpark pode ser mais rápido porque sua cabeça de Markov foi projetada para reduzir o problema de “decaimento do sufixo” que aparece com frequência no rascunho paralelo de tokens.
Uma atualização posterior do mlx-dspark adicionou o caminho original do DFlash da z-lab diretamente ao pacote. Ela também adicionou um parâmetro para ajustar o comprimento efetivo do bloco. Isso oferece aos usuários uma escolha mais flexível:
- Usar blocos mais curtos para tarefas semelhantes a chat.
- Usar o bloco completo de 16 tokens para tarefas de código e matemática.
- Comparar DSpark e DFlash no mesmo pacote, em vez de alternar entre projetos separados.
Isso faz com que o mlx-dspark se pareça menos com um experimento de método único e mais com um kit de ferramentas prático de inferência local para usuários de Apple Silicon.
Por que isso importa para o desenvolvimento local de IA
Fluxos de trabalho locais com LLMs estão se tornando mais comuns para desenvolvedores, pesquisadores e pequenas equipes. Executar modelos localmente oferece mais controle sobre latência, tratamento de dados, experimentos e fluxos de trabalho offline.
Mas a inferência local frequentemente tem uma limitação dolorosa: velocidade. Mesmo quando um modelo cabe na memória, a geração pode parecer lenta.
O mlx-dspark é interessante porque ataca esse problema sem exigir um modelo-alvo completamente novo. Ele usa decodificação especulativa para fazer o modelo existente parecer mais rápido, ao mesmo tempo em que ainda permite que o modelo-alvo verifique a saída.
Para desenvolvedores que criam aplicativos locais de IA no Mac, isso pode ser útil em vários cenários:
- Testar IA
recursos antes de migrar para inferência no servidor.
2. Executar assistentes locais de programação ou de documentos.
3. Comparar estratégias de decodificação para diferentes tipos de tarefas.
4. Criar serviços locais leves compatíveis com a OpenAI.
5. Avaliar se uma configuração menor de Mac é suficiente para um protótipo específico.
A troca de compromissos ainda é importante. Um método que funciona bem em código e matemática pode não ser a melhor escolha para conversas abertas. Um método que tem bom desempenho em um M4 Pro pode se comportar de forma diferente em chips Apple Silicon mais antigos ou em máquinas com memória limitada.
Portanto, a conclusão prática não é “um método vence em todos os cenários”. É que o Apple Silicon agora tem um caminho mais forte para experimentar DSpark, DFlash e decodificação especulativa nativa em MLX.
FAQ
O que é DSpark?
DSpark é um método de decodificação especulativa associado ao projeto DeepSpec da DeepSeek. Ele usa um modelo de rascunho para propor tokens antecipadamente e permite que o modelo-alvo os verifique, com o objetivo de acelerar a inferência preservando o comportamento da saída.
O que é mlx-dspark?
mlx-dspark é uma implementação da comunidade que leva a decodificação especulativa no estilo DSpark e DFlash ao Apple Silicon por meio do MLX. Ela permite que alvos Gemma e Qwen compatíveis sejam executados com aceleração por modelo de rascunho no Mac.
O mlx-dspark executa o DeepSeek-V4 localmente?
Não. O projeto mlx-dspark explica que seus alvos locais no Mac são modelos densos, como Gemma e Qwen, não o próprio DeepSeek-V4. Ele usa o método de rascunho DSpark da DeepSeek, mas o modelo-alvo que produz tokens no fluxo de trabalho do Mac é Gemma ou Qwen.
Quanto mais rápido é o DSpark no Mac?
Nos testes relatados, o Gemma-4 12B melhorou de cerca de 18,4 tok/s para cerca de 30 tok/s, enquanto o Qwen3-4B melhorou de cerca de 52,9 tok/s para cerca de 73 tok/s. A velocidade real depende do chip do Mac, do modelo, da precisão, do tipo de prompt e das configurações de decodificação.
O que é DFlash?
DFlash é um método de decodificação especulativa por difusão em blocos desenvolvido pela z-lab. Ele rascunha um bloco de tokens em paralelo e pode ser especialmente eficaz em tarefas estruturadas, como código e matemática, quando o comprimento aceito é alto.
DSpark é melhor que DFlash?
Nem sempre. O DFlash pode ter melhor desempenho em tarefas de código e matemática, enquanto o DSpark pode ser mais forte em chats abertos, nos quais blocos paralelos longos são mais difíceis de prever. A melhor escolha depende do modelo-alvo e do tipo de tarefa.
Preciso de Apple Silicon para usar o mlx-dspark?
O mlx-dspark foi projetado para Apple Silicon por meio do MLX, portanto um Mac com Apple Silicon é o ambiente pretendido. Ele também exige uma configuração Python compatível e pesos de modelos compatíveis do Hugging Face ou de caminhos locais.
A decodificação especulativa é adequada para produção?
Pode ser, mas o uso em produção exige benchmarking cuidadoso. É necessário verificar a fidelidade da saída, o comprimento aceito, a latência, o comportamento de batching, o uso de memória, a compatibilidade do modelo e o desempenho específico do hardware antes de depender dela.
Ferramentas relacionadas
- mlx-dspark: Um projeto da comunidade que executa decodificação especulativa DSpark e DFlash nativamente no Apple Silicon por meio do MLX.
- DeepSpec: A base de código full-stack da DeepSeek para treinar e avaliar modelos de rascunho de decodificação especulativa.
- MLX: O framework de aprendizado de máquina da Apple projetado para trabalho eficiente no Apple Silicon.
- z-lab/gemma4-12B-it-DFlash: Um modelo de rascunho DFlash para fluxos de trabalho Gemma-4 12B ajustados para instruções.
- Hugging Face: Uma plataforma de hospedagem de modelos usada pelos projetos e checkpoints mencionados neste artigo.
- Organização DeepSeek no Hugging Face: A organização oficial da DeepSeek no Hugging Face para lançamentos de modelos e checkpoints.
Links relacionados
- Artigo-fonte no BAAI Hub: O artigo original em chinês que apresentou o port do mlx-dspark para Apple Silicon.
- Publicação original de Abdur Rahim no X: A publicação referenciada anunciando o DSpark em execução no Apple Silicon.
- Repositório GitHub do mlx-dspark: Instalação, uso, modelos compatíveis e notas de benchmark para a implementação no Apple Silicon.
- Repositório GitHub do DeepSpec: Repositório oficial da DeepSeek para algoritmos de decodificação especulativa e checkpoints lançados.
- PDF do artigo DSpark: O artigo técnico incluído no repositório DeepSpec.
- Coleção DFlash no Hugging Face: Coleção da z-lab para modelos de rascunho relacionados ao DFlash.
- Documentação do MLX: Documentação oficial do framework MLX da Apple.
- Repositório GitHub do MLX: Repositório-fonte do framework de aprendizado de máquina para Apple Silicon.
Resumo
Este artigo explica como o método de decodificação especulativa DSpark da DeepSeek foi portado para o Apple Silicon por meio do mlx-dspark, tornando a inferência local no Mac mais rápida para modelos Gemma e Qwen compatíveis.
O ponto principal é que o port não se trata apenas de velocidade bruta. Ele também se concentra em manter a fidelidade da saída ao permitir que o modelo-alvo verifique os tokens gerados, incluindo suporte ao comportamento de decodificação amostrada.
A integração do DFlash adiciona outra opção útil,
especialmente para tarefas de código e matemática, nas quais a elaboração de blocos longos pode compensar. Para conversas abertas, o DSpark ainda pode ser a opção mais adequada, porque é mais difícil manter o comprimento aceito.
Para o desenvolvimento local de IA em Mac, o mlx-dspark oferece aos usuários de Apple Silicon uma forma prática de testar inferência de LLM mais rápida sem precisar mover tudo para um servidor.


