
Краткий ответ: нет, но направление важно
DiffusionGemma — это не заявление Google о смерти предсказания следующего токена. Правильнее понимать ее как серьезный экспериментальный сигнал: Google тестирует иной путь для генерации текста ИИ, где скорость, параллелизм и интерактивные локальные рабочие процессы важнее привычного ритма стандартных LLM, генерирующих по одному токену за раз.
Google описывает DiffusionGemma как экспериментальную открытую модель, построенную вокруг текстовой диффузии. Вместо того чтобы генерировать текст строго слева направо, она создает блоки текста, уточняя «холст» из шумовых или заполняющих токенов. Практическое обещание простое: если модель может работать со многими позициями одновременно, она способна эффективнее использовать вычисления GPU и снижать задержку инференса в некоторых сценариях.
Но это не означает, что авторегрессионные языковые модели будут заменены уже завтра. В собственном анонсе Google осторожно говорит о компромиссах. Компания отмечает, что стандартные модели Gemma 4 остаются рекомендуемым вариантом для приложений, где требуется максимальное производственное качество. Это предложение важно. DiffusionGemma — исследовательская и разработческая модель с упором на скорость, а не универсальная замена доминирующей парадигме LLM.
Почему предсказание следующего токена стало стандартом
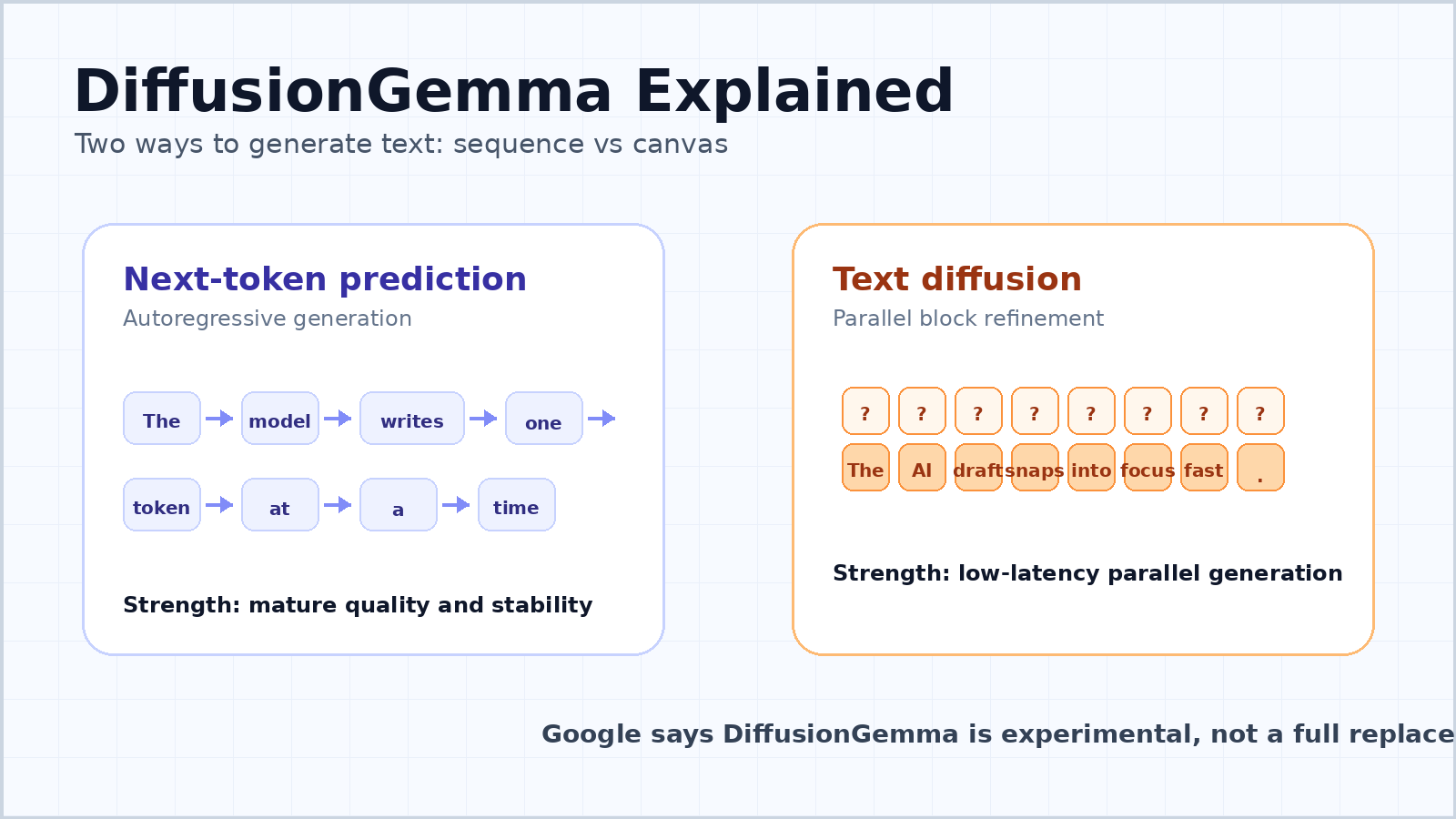
Большинство современных чат-ботов и больших языковых моделей являются авторегрессионными. Они читают запрос, затем предсказывают следующий токен, затем следующий токен после него и продолжают до тех пор, пока ответ не будет завершен. Это простая ментальная модель, лежащая в основе предсказания следующего токена.
То, что этот подход стал доминирующим, не случайность. Авторегрессионные модели гибкие, стабильные и хорошо масштабируются. Они могут генерировать текст переменной длины, сохранять связность слева направо и хорошо работать в чатах, программировании, переводе, суммаризации, рассуждении и использовании инструментов. Этот подход также естественно соответствует тому, как разворачивается письменная речь.
Слабое место — задержка. У модели, работающей токен за токеном, есть последовательная зависимость: токен 100 зависит от токенов с 1 по 99, а токен 101 зависит от токена 100. Даже при мощном GPU модели приходится проходить последовательность шаг за шагом. Когда один пользователь задает один вопрос, значительная часть аппаратных ресурсов может оставаться недоиспользованной, потому что модель ожидает перемещения данных в памяти и последовательного декодирования.
Чем DiffusionGemma отличается
DiffusionGemma вдохновлена диффузионными моделями — семейством генеративных моделей, прославившимся в генерации изображений и видео. Вместо того чтобы строить ответ по одному токену, диффузионная модель начинает с шума или неопределенности и постепенно уточняет их до связного результата.
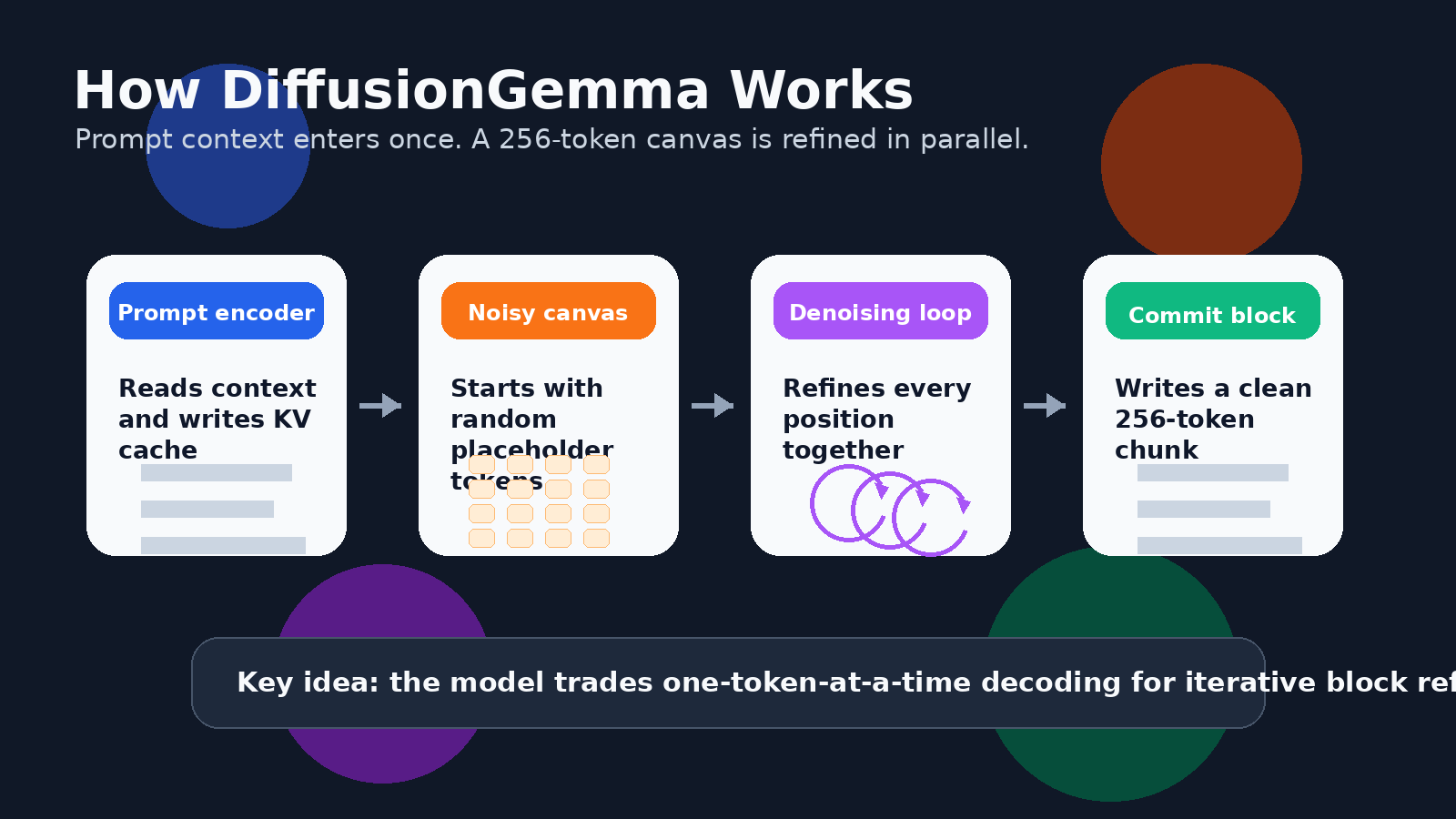
Для текста это означает, что модель может параллельно работать с блоком токенов. В руководстве Google для разработчиков описан холст на 256 токенов. Модель начинает с холста из случайных заполняющих токенов, а затем многократно устраняет шум во всем блоке. Позиции токенов, в которых модель уверена, становятся опорными точками, неопределенные позиции уточняются снова, и блок постепенно становится четким.
Это не то же самое, что сгенерировать целое длинное эссе за один проход. Для более длинных выходных данных DiffusionGemma использует блочно-авторегрессионный подход. Когда блок из 256 токенов полностью уточнен, он фиксируется в KV-кэше, и модель переходит к следующему блоку. Поэтому структура слева направо между блоками сохраняется, но внутри каждого блока модель может уточнять множество токенов одновременно.
Почему это может быть быстрее
История со скоростью связана с аппаратным узким местом. Традиционные авторегрессионные модели могут упираться в пропускную способность памяти, потому что модель многократно загружает веса, генерируя по одному токену за раз. DiffusionGemma пытается перенести большую часть работы в сторону вычислений, предоставляя GPU более крупную параллельную нагрузку внутри каждого блока.
Google заявляет, что DiffusionGemma может обеспечивать до четырех раз более быструю генерацию токенов на специализированных GPU; среди примеров — более 1000 токенов в секунду на одном NVIDIA H100 и более 700 токенов в секунду на RTX 5090. Эти цифры не являются универсальным обещанием для каждой задачи, устройства или размера пакета. Это сигнал о конкретном, удобном для аппаратного обеспечения шаблоне генерации.
Именно поэтому DiffusionGemma особенно интересна для локальных и интерактивных рабочих процессов. Если пользователь запрашивает быстрые правки, заполнение кода, структурированные черновики или быстрые итерации, у GPU могут оставаться свободные вычислительные ресурсы, которые авторегрессионная модель не способна полностью использовать. Диффузионная языковая модель может лучше подходить для такого типа низкобатчевой нагрузки, чувствительной к скорости.
Роль двунаправленного внимания и самокоррекции
Одно из самых важных отличий — двунаправленное внимание. Во время шумоподавления токены на холсте могут учитывать другие позиции в блоке, а не только предыдущие токены. Это меняет ощущение от генерации. Модель может использовать контекст с обеих сторон отсутствующего или неопределенного фрагмента.
Это особенно полезно для нелинейных текстовых задач. Google приводит в качестве примеров встроенное редактирование, заполнение кода, математические графы и даже ограниченную генерацию в стиле судоку — ситуации, где будущие позиции имеют значение. Стандартная авторегрессионная модель может быть сильна во многих задачах, но после того как она выдает ранний токен, она обычно уже связана им. Диффузионное шумоподавление оставляет пространство для пересмотра до финализации блока.
Именно поэтому вокруг DiffusionGemma постоянно появляется термин самокоррекция. Модель не просто печатает текст. Она многократно оценивает весь холст, сохраняет уверенные позиции, заменяет неопределенные и уточняет блок, пока он не сойдется.
Что означает архитектура MoE на 26B
DiffusionGemma основана на архитектуре Mixture of Experts на 26B из семейства Gemma 4, при этом во время инференса используется только меньшая активная часть. В документации Google по ИИ она описывается как модель на 26B с примерно 4B активных параметров, а в руководстве для разработчиков объясняется, что модель спроектирована так, чтобы помещаться в пределах 18 ГБ VRAM при квантовании.
Ключевая идея — эффективность. Разреженная модель MoE может иметь большое общее число параметров, активируя только выбранных экспертов для конкретного токена или задачи. Это может повысить возможности без необходимости активировать всю модель на каждом шаге.
Для разработчиков это важно, потому что DiffusionGemma — не просто лабораторная демонстрация. Она выпущена как модель с открытыми весами под лицензией Apache 2.0, с документацией для vLLM, Hugging Face, Google Cloud Model Garden и других путей развертывания. Google явно приглашает экосистему проверить, может ли генерация на основе диффузии стать практичной в реальных приложениях.
Где DiffusionGemma имеет смысл

Лучшие сценарии применения — не обязательно длинные премиальные тексты. Это критичные к скорости задачи, где пользователю выгодны быстрые итерации. Один из примеров — встроенное редактирование. Вместо того чтобы ждать, пока модель перепишет абзац токен за токеном, диффузионная модель может быстро уточнить целый фрагмент.
Заполнение кода — еще один сильный кандидат. Разработчику может понадобиться, чтобы модель заполнила середину функции или скорректировала блок кода с учетом того, что находится до и после него. Двунаправленное внимание здесь полезно, потому что модель может рассуждать, учитывая обе стороны отсутствующего участка.
Структурированная и ограниченная генерация также представляет интерес. Если результат имеет множество зависимостей, например таблицу, головоломку, шаблон или формальную схему, уточнение блока может дать модели больше пространства для координации между позициями. Поэтому DiffusionGemma — это не только про скорость. Она также указывает на иной стиль взаимодействия при генерации.
Где авторегрессионные модели все еще выигрывают
Компромисс заключается в качестве. Google прямо заявляет, что DiffusionGemma отдает приоритет скорости и параллельной генерации структуры, а ее общее качество вывода ниже, чем у стандартной Gemma 4. Это главная причина, по которой ее не следует описывать как полную замену предсказанию следующего токена.
Авторегрессионные модели по-прежнему обладают серьезными преимуществами. Они глубоко оптимизированы для продакшена, сильны во многих задачах общего назначения и поддерживаются зрелыми стеками обслуживания. Они также естественно подходят для диалоговых потоков, где модель последовательно продолжает текст.
Реалистичное будущее, вероятно, не в том, что один метод декодирования заменит другой. Скорее всего, ИИ-системы будут направлять разные задачи к разным стратегиям генерации. Авторегрессионные модели могут оставаться вариантом по умолчанию для качественного общего чата и рассуждений, тогда как диффузионные языковые модели могут обеспечивать быстрое редактирование, локальную генерацию, заполнение кода и другие интерактивные рабочие нагрузки.
За чем разработчикам стоит следить дальше
Главный вопрос заключается в том, смогут ли диффузионные языковые модели сократить разрыв в качестве, сохранив преимущество в задержке. Одной скорости недостаточно, если результат требует слишком большого количества исправлений. Но если качество улучшится, эта архитектура может стать очень важной для локального ИИ, ассистентов в IDE, редактирования документов и интерфейсов реального времени.
Второй вопрос — инфраструктура обслуживания. Поддержка vLLM важна, потому что диффузионные языковые модели требуют иного поведения при декодировании: двунаправленного внимания, итеративного устранения шума, пользовательской выборки и логики фиксации на уровне блоков. Если фреймворки инференса упростят это, больше разработчиков начнут экспериментировать.
Третий вопрос — дизайн продукта. Диффузионная текстовая модель — это не просто более быстрый чат-бот. Ее естественный интерфейс может быть скорее похож на умный редактор, который дорабатывает полотно, заполняет пробелы и улучшает черновики прямо на месте. Это может изменить то, как пользователи воспринимают инструменты ИИ для письма и программирования.
Итоговый вывод
DiffusionGemma не означает, что Google уже сегодня заменяет предсказание следующего токена. Это означает, что Google делает текстовую диффузию достаточно практичной, чтобы разработчики могли тестировать ее в реальных рабочих процессах.
Важный сдвиг заключается не только в более быстром тексте. Это идея о том, что генерация языка не всегда должна выглядеть как модель, печатающая слева направо. Иногда более удачное взаимодействие — это полотно, которое уточняется параллельно.
Если этот подход улучшится, генерация текста ИИ может стать быстрее, более интерактивной и лучше подходящей для локальных устройств. Но пока DiffusionGemma следует понимать как экспериментальную открытую модель с очень четким посланием: будущее генерации языка может включать более одного пути декодирования.
Краткое сравнение
Вопрос | Авторегрессионные LLM | DiffusionGemma |
Шаблон генерации | Последовательно предсказывает следующий токен | Параллельно уточняет токенное полотно |
Сильная сторона | Высококачественные производственные результаты | Интерактивная генерация с низкой задержкой |
Поток контекста | В основном слева направо во время декодирования | Двунаправленный внутри каждого полотна устранения шума |
Лучшее применение | Общий чат, рассуждения, зрелая инфраструктура обслуживания | Редактирование, заполнение кода, быстрые локальные рабочие процессы |
Статус | Доминирующая производственная парадигма | Экспериментальная открытая модель |
CTA
Если вы создаете ИИ-продукты, не воспринимайте DiffusionGemma как простую модель-замену. Рассматривайте ее как новый шаблон генерации, который стоит тестировать там, где особенно важны задержка инференса, локальная отзывчивость и нелинейное редактирование.
Для команд, создающих инструменты для разработчиков, ассистентов для письма, рабочие процессы программирования или ИИ-возможности на устройстве, это именно тот тип архитектуры, который стоит начать бенчмаркать как можно раньше.
FAQ
Что такое DiffusionGemma?
DiffusionGemma — это экспериментальная открытая модель Google для генерации текста, которая использует дискретную диффузию для параллельного уточнения блоков токенов вместо того, чтобы полагаться только на потокеновую генерацию.
Заменяет ли Google предсказание следующего токена?
Нет. Google по-прежнему рекомендует стандартную Gemma 4 для максимального качества в продакшене. DiffusionGemma является экспериментальной и оптимизирована для рабочих процессов, критичных к скорости.
Почему DiffusionGemma быстрее?
Она работает с полотном из 256 токенов параллельно, смещая больше работы в сторону вычислений на GPU вместо строго последовательной генерации по одному токену за раз.
Что такое холст на 256 токенов?
Это блок позиций токенов, который модель инициализирует, очищает от шума, уточняет, а затем фиксирует перед переходом к следующему блоку.
Кому стоит тестировать DiffusionGemma?
Разработчикам, работающим над локальным инференсом, встроенным редактированием, заполнением кода, быстрым черновым написанием и другими интерактивными ИИ-инструментами с низкой задержкой, стоит обратить внимание.
Связанные инструменты
- vLLM
- Colab
- Kaggle
Источники
- Руководство для разработчиков
- DeepMind


