
Principais conclusões
Se a carga de trabalho for composta principalmente por loops de agentes, chamadas de ferramentas e execução em várias etapas, o Flash deve ser a sua escolha padrão.
Se a carga de trabalho for composta principalmente por recuperação em documentos longos e localização exata de cláusulas em mais de 100 mil tokens, o Pro ainda é a opção mais segura hoje.
Para RAG de alta frequência, a verdadeira vantagem muitas vezes está na economia de cache, e não apenas no preço de tabela.
O raciocínio abstrato no estilo ARC e as cargas de trabalho com as perguntas mais difíceis ainda estão mais alinhados com o Pro.
A resposta mais prática para equipas de produção não é um único modelo, mas sim o roteamento por tarefa.
O que torna o artigo de origem útil é que ele não se limita a dizer que “o Flash superou o Pro do ano passado”. Ele decompõe essa afirmação em cinco cargas de trabalho concretas, que é a única forma de uma comparação entre modelos se tornar operacional em vez de meramente decorativa.
A pergunta certa não é “qual modelo é melhor em geral?”. É quais das suas tarefas realmente estão a pagar por velocidade, uso de ferramentas, aproveitamento de cache, recuperação em contexto longo ou teto de raciocínio.
Para uma equipa como a We0 AI, essa questão importa para além do uso bruto da API. A escolha do modelo afeta a rapidez com que se podem produzir documentos, páginas de apresentação, FAQs, conteúdo SEO, bases de conhecimento e fluxos de geração de leads que realmente chegam à produção.
Carga de trabalho 1: agentes MCP e loops intensivos em ferramentas
Veredito da fonte: o Flash vence claramente.
Este é o padrão em que uma tarefa aciona várias interações com o modelo e várias chamadas de ferramentas em sequência: pesquisa, recuperação vetorial, trabalho em terminal, execução de código, leitura de ficheiros, validação e iteração.
Benchmark
Gemini 3.5
FlashGemini 3.1 Pro
MCP Atlas
83,6%
78,2%
Toolathlon
56,5%
49,4%
GDPval-AA (Elo)
1656
1314
Isso não é uma vitória em um benchmark restrito. É uma vantagem no nível do fluxo de trabalho. O artigo de origem trata a diferença de 342 pontos no GDPval-AA como o sinal mais forte de que o Flash foi pós-treinado para trabalho agêntico real, e não apenas para chat convencional.
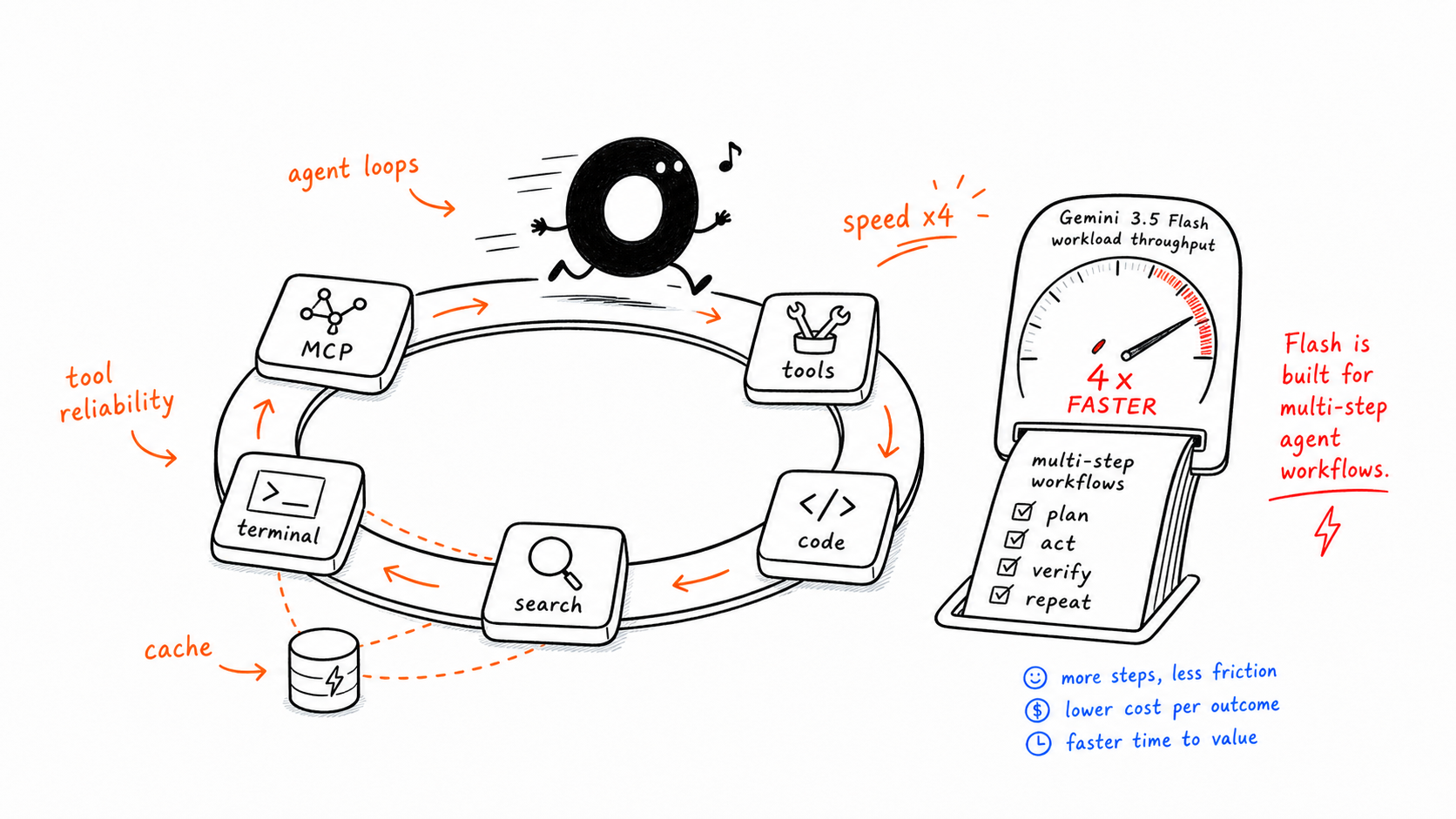
Se a sua equipa está a desenvolver:
loops de ferramentas MCP
agentes de pesquisa ou automação
assistentes de programação baseados em terminal
fluxos de trabalho de alta frequência e múltiplas etapas
então o Flash não é apenas mais barato. É mais rápido, mais amigável para loops, mais amigável para cache e mais bem ajustado para execução repetida.
Isso é especialmente relevante para sistemas ao estilo do We0 AI, em que a saída do modelo se transforma em:
pipelines de produção de conteúdo
documentação para sites de apresentação e geração de FAQ
fluxos de trabalho de artigos para SEO / GEO
automação de bases de conhecimento e suporte
Carga de trabalho 2: Recuperação de agulha no palheiro em documentos longos
Veredito da fonte: o Pro continua a ser a opção mais segura aqui.
Esta é a principal exceção em todo o artigo. O Flash não é “mau” em termos absolutos, mas quando a tarefa passa a ser encontrar uma cláusula exata dentro de um documento muito longo, o Pro continua a ser a escolha mais estável.
Benchmark
Gemini 3.5 Flash
Gemini 3.1 Pro
MRCR v2 (128k)
77,3%
84,9%
MRCR v2 (1M)
26,6%
26,3%
Os 128kslice é o sinal de alerta prático. Se a sua promessa é “carregue o contrato inteiro e pergunte qualquer coisa”, então esta não é a categoria que você deve migrar cegamente para o Flash ainda.
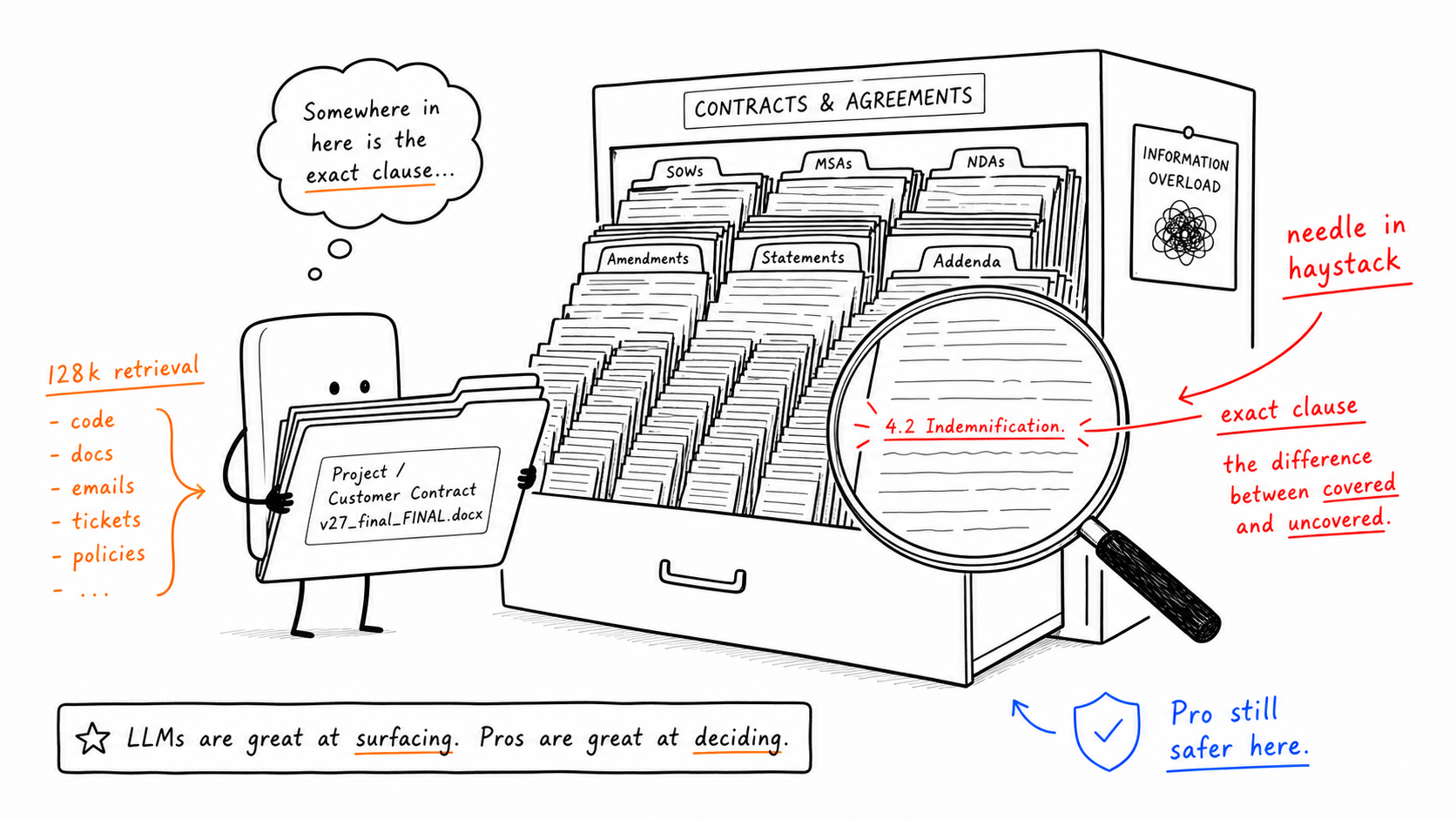
Isso é importante para cargas de trabalho como:
busca de cláusulas contratuais
conformidade e revisão jurídica
busca em especificações técnicas longas
rastreabilidade entre arquivos em grandes bases de código
A regra subjacente é simples: quando a parte mais difícil não é gerar, mas localizar com precisão a frase certa dentro de um contexto enorme, o Pro ainda merece o trabalho.
Carga de trabalho 3: RAG de alta frequência com um corpus estável
Veredito na origem: Flash com cache agressivo é a escolha padrão óbvia.
Este é o cenário mais relevante para sistemas de suporte SaaS, ferramentas internas de conhecimento e produtos com muita documentação. O maior custo geralmente não está em uma única resposta, mas em leituras repetidas sobre o mesmo prompt de sistema e prefixos estáveis de documentação.
Fator
Gemini 3.5 Flash
Gemini 3.1 Pro
Preço de entrada
$1.50 / 1M
$2.00 / 1M
Preço de saída
$9.00 / 1M
$12.00 / 1M
Entrada em cache
$0.15 / 1M
$0.50 / 1M
Taxa de processamento
289 tok/s
~70 tok/s
O ponto mais importante aqui é que a economia de cache pode importar mais do que a diferença de preço nominal entre os modelos.
Se você está criando:
RAG para central de ajuda
assistentes internos de SOP
assistentes para documentação de produto e FAQ
vendas ou suportesistemas de recuperação sobre conteúdo estável
então o Flash é frequentemente o que torna o sistema não apenas possível, mas escalável.
Isso também está alinhado com a lógica mais ampla da We0 AI: o conteúdo não deve apenas existir. Ele deve tornar-se pesquisável, recomendável, reutilizável e capaz de continuar gerando leads ao longo do tempo. Corpus estáveis e padrões de modelo favoráveis a cache estão naturalmente alinhados com esse objetivo.
Carga de trabalho 4: Raciocínio abstrato no estilo ARC
Veredito da fonte: isto ainda é território do Pro.
Assim que a tarefa começa a parecer mais um quebra-cabeça, um desafio de padrão abstrato, um problema difícil de olimpíada ou uma novidade de nível especializado, o Flash deixa de ser o favorito evidente.
Benchmark
Gemini 3.5 Flash
Gemini 3.1 Pro
ARC-AGI-2
72.1%
77.1%
Último Exame da Humanidade
40.2%
44.4%
O artigo de origem faz a distinção de forma clara: o Flash é otimizado para amplitude agêntica. O Pro ainda mantém um teto de raciocínio mais alto.
Se o valor da sua aplicação depende de:
raciocínio abstrato genuíno
confiabilidade nas perguntas mais difíceis
resolução de problemas novos
tarefas em estilo de pesquisa
então permanecer no Pro ainda é a opção mais conservadora hoje.
Carga de trabalho 5: Agentes de programação baseados em terminal
Veredito da fonte: Flash para a maior parte da programação em terminal, com uma ressalva importante.
Benchmark
Gemini 3.5 Flash
Gemini 3.1 Pro
Terminal-Bench 2.1
76.2%
70.3%
SWE-Bench Pro (Público)
55.1%
54.2%
Blueprint-Bench 2
33.6%
26.5%
Esta é uma das seções mais práticasno artigo porque corresponde de perto ao comportamento real dos desenvolvedores:
corrigir um stack trace
implementar uma funcionalidade em alguns ficheiros
executar testes, corrigir o código e tentar novamente
converter uma especificação em código
Para esse tipo de programação de alta frequência, iterativa e fortemente dependente de ferramentas, o Flash é a opção padrão mais forte.
A ressalva é importante, porém: refatorações em bases de código grandes, entre vários ficheiros e com muito contexto são, na verdade, um problema de recuperação em contexto longo disfarçado. É aí que o Pro ainda mantém alguma vantagem.
A Árvore de Decisão
A árvore de decisão do artigo original vale a pena ser preservada porque é realmente utilizável:
A sua carga de trabalho consiste principalmente em ciclos de agente ou uso de ferramentas?
├─ SIM → Gemini 3.5 Flash
└─ NÃO → É recuperação em contexto longo com mais de 100 mil tokens?
├─ SIM → Gemini 3.1 Pro
└─ NÃO → Trata-se de raciocínio abstrato / das questões especializadas mais difíceis?
├─ SIM → Gemini 3.1 Pro ou Deep Think
└─ NÃO → É RAG com corpus estável?
├─ SIM → Gemini 3.5 Flash com cache agressiva
└─ NÃO → Gemini 3.5 Flash por padrãoPara a maioria das equipas, a verdadeira mensagem é esta: o Flash provavelmente deve ser o seu modelo padrão, mas não o seu único modelo.
O Que Não Muda em Junho
A secção de junho é inteligente porque lida diretamente com a continuação natural: deve simplesmente esperar pelo Gemini 3.5 Pro?
A resposta não é um sim ou não absoluto. Depende da carga de trabalho:
Se precisa de agentes MCP agora, o Flash já vale a pena para entrar em produção.
Se precisa de RAG favorável a cache, o Flash já tem uma vantagem estrutural de custo.
Se o seu sistema depende criticamente de raciocínio, alternar do Pro para o Flash e depois voltar costuma ser um movimento desnecessário.
Junho pode alterar alguns limites, mas não elimina os compromissos de desempenho por tarefa que existem hoje.
Lance Ambos — Encaminhe por Tarefa
Esta é a conclusão mais adequada para produção do artigo e também a mais fácil de reinterpretar pela ótica da We0 AI.
Em aplicações reais, a melhor abordagem muitas vezes não é discutir qual é o único melhor modelo, mas fazer um encaminhamento inteligente:
envie loops de agentes, uso de ferramentas e programação no terminal para o Flash
envie análise de documentos longos e recuperação exata de cláusulas para o Pro
envie os casos de raciocínio mais difíceis para um modelo de raciocínio mais profundo
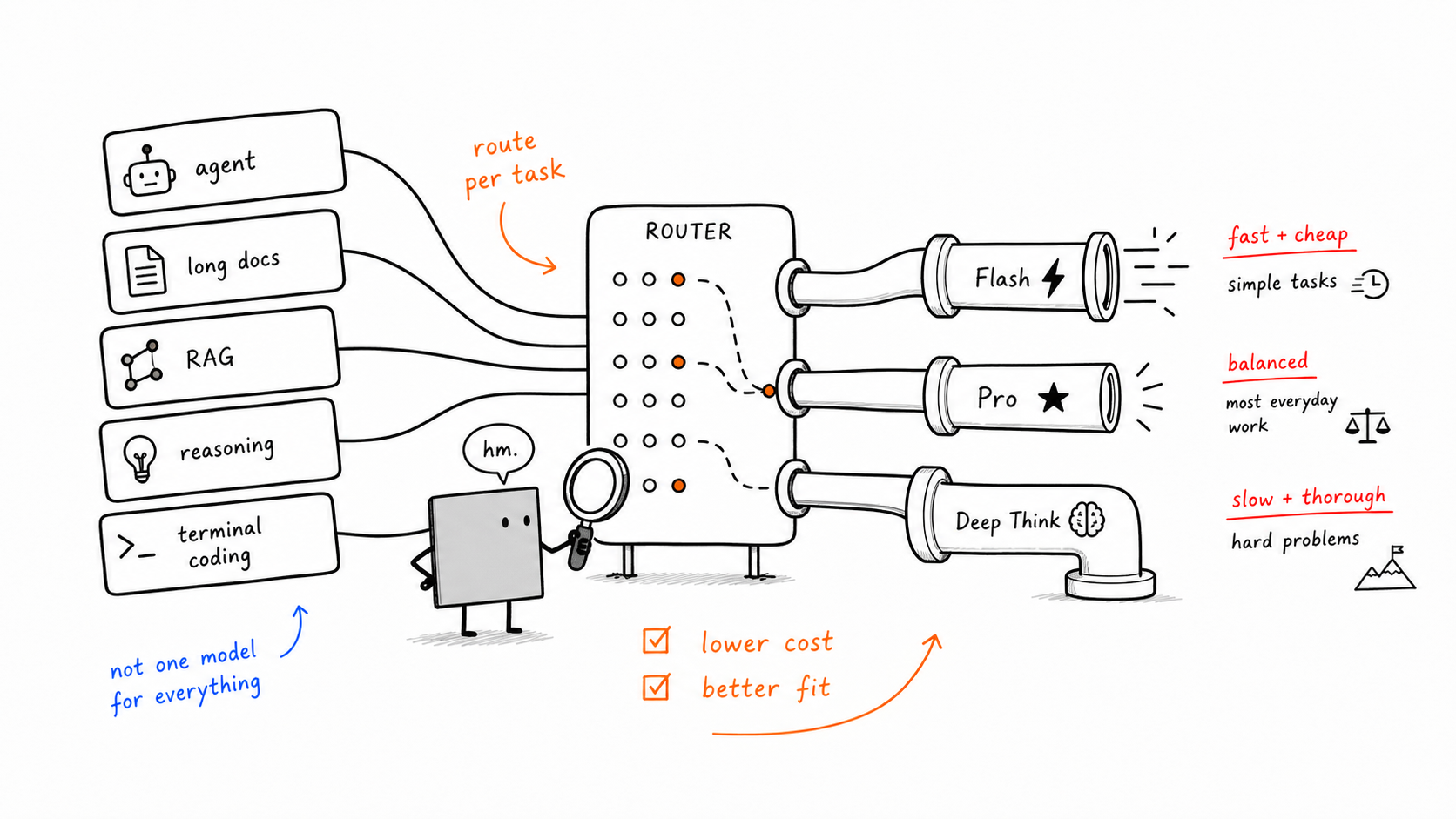
Na We0 AI, esse mesmo princípio vai além do encaminhamento de modelos. A cadeia completa se parece mais com isto:
escolher o modelo certo para a tarefa certa
transformar a saída em conteúdo de produto utilizável, documentação, FAQs e páginas de apresentação
tornar esses ativos fáceis de encontrar por meio de SEO / GEO e superfícies de recomendação por IA
converter essa visibilidade em leads e clientes
Esse é o verdadeiro motivo pelo qual a We0 AI se importa com Construir -> Exibir -> Crescer -> Leads em vez de parar em “integramos uma API de modelo”.
Pronto para Construir?
Se você já está criando produtos de IA, fluxos de trabalho ou sites de apresentação, esta comparação pode se transformar em um conjunto simples de regras de execução:
use o Flash por padrão para fluxos de trabalho agentivos
encaminhe a recuperação em documentos longos paraPro
estruturar corpora estáveis e FAQs para eficiência de cache
converter a saída do modelo em documentação, conteúdo para central de ajuda, estudos de caso e ativos de busca
Para a We0 AI, o objetivo não é apenas ajudar uma equipa a ligar um modelo. É ajudá-la a transformar essas capacidades em sistemas prontos para demonstração, pesquisáveis e geradores de leads.
Perguntas frequentes
Devo substituir o Gemini 3.1 Pro pelo Gemini 3.5 Flash em todo o lado?
Não. Fluxos de trabalho agentivos, programação no terminal e ciclos de ferramentas MCP são fortes candidatos para o Flash. Recuperação de documentos longos, raciocínio abstrato e cargas de trabalho com as perguntas mais difíceis continuam a ser opções mais seguras no Pro.
O Gemini 3.5 Flash é realmente mais forte no geral?
Com base nos benchmarks publicados no artigo de origem, o Flash vence em 11 de 15 e é especialmente forte no MCP Atlas, Terminal-Bench 2.1, Finance Agent v2 e Blueprint-Bench 2.
Qual é mais barato?
O Flash é mais barato no preço de tabela, mas a diferença mais importante está no preço da entrada em cache. Para prefixos estáveis e cargas de trabalho repetidas no estilo RAG, essa diferença torna-se muito maior.
O Gemini 3.5 Flash é bom para recuperação de documentos com contexto longo?
Não, se o principal requisito for a recuperação exata de cláusulas em documentos muito longos. Os números do MRCR v2 128k no artigo de origem ainda favorecem o Pro nesse ponto.
Que modelo devo usar para agentes de programação no terminal?
Para a maioria das tarefas iterativas de programação no terminal com uso intensivo de ferramentas, o Flash é a melhor opção por defeito. Para grandes refatorações entre ficheiros em repositórios muito extensos, o Pro ainda merece consideração.
Devo esperar pelo Gemini 3.5 Pro?
Se o seu pipeline for crítico em termos de raciocínio e a espera for de apenas algumas semanas, esperar pode ser racional. Se precisa agora de agentes MCP, programação no terminal e fluxos de trabalho rápidos, o Flash
já vale a pena colocar em produção.Artigos Relacionados
Guia completo do Gemini 3.5 Flash: benchmarks, preços e principais conclusões da API
Guia do desenvolvedor para o Gemini 3.5 Flash: três armadilhas da API e um agente MCP real
Criando aplicações em produção com o Gemini 3 Flash: arquitetura, desempenho e custo
Gemini 3.1 Pro vs GPT-5.4: como escolher de acordo com a carga de trabalho
Links Parceiros
Anthropic — Modelos de IA de fronteira e pesquisa em segurança de IA.
Hugging Face — Modelos de IA de código aberto, conjuntos de dados e ferramentas de ML.
Vercel — Plataforma de implantação para aplicações web modernas.
LangChain — Framework para criar aplicações com tecnologia de LLM.
Pinecone — Banco de dados vetorial para sistemas de recuperação de IA.
Cloudflare — Desempenho, segurança e infraestrutura de edge.
We0 AI — Criar,Apresente, cresça e gere leads com IA.

