
Kernaussagen
Wenn die Arbeitslast überwiegend aus Agentenschleifen, Tool-Aufrufen und mehrstufiger Ausführung besteht, sollte Flash Ihre Standardwahl sein.
Wenn die Arbeitslast überwiegend aus dem Abruf langer Dokumente und dem exakten Auffinden von Klauseln in über 100.000 Tokens besteht, ist Pro derzeit weiterhin die sicherere Wahl.
Bei hochfrequentem RAG liegt der eigentliche Vorteil oft in der Cache-Ökonomie und nicht nur im Listenpreis.
ARC-ähnliches abstraktes Schlussfolgern und Workloads mit den schwierigsten Fragen sind weiterhin besser mit Pro abgestimmt.
Die praktischste Antwort für Produktionsteams ist nicht ein einziges Modell, sondern ein taskbasiertes Routing.
Was den Quellartikel nützlich macht, ist, dass er nicht dabei stehen bleibt zu sagen: „Flash hat das Pro-Modell des letzten Jahres übertroffen.“ Er zerlegt diese Behauptung in fünf konkrete Workloads – und nur so wird ein Modellvergleich operativ statt bloß dekorativ.
Die richtige Frage lautet nicht: „Welches Modell ist insgesamt das beste?“ Sie lautet vielmehr: Für welche Ihrer Aufgaben zahlen Sie tatsächlich für Geschwindigkeit, Tool-Nutzung, Cache-Vorteile, Retrieval in langen Kontexten oder die Obergrenze des Schlussfolgerns.
Für ein Team wie We0 AI ist diese Frage nicht nur für die reine API-Nutzung relevant. Die Wahl des Modells beeinflusst, wie schnell Sie Dokumentationen, Showcase-Seiten, FAQs, SEO-Inhalte, Wissensdatenbanken und Lead-Generierungs-Workflows erstellen können, die tatsächlich ausgeliefert werden.
Workload 1: MCP-Agenten und tool-intensive Schleifen
Urteil der Quelle: Flash gewinnt klar.
Dies ist das Muster, bei dem eine Aufgabe mehrere Modell-Durchläufe und mehrere Tool-Aufrufe nacheinander auslöst: Suche, Vektor-Retrieval, Terminal-Arbeit, Codeausführung, Dateilesen, Validierung und Iteration.
Benchmark
Gemini 3.5
FlashGemini 3.1 Pro
MCP Atlas
83,6 %
78,2 %
Toolathlon
56,5 %
49,4 %
GDPval-AA (Elo)
1656
1314
Das ist kein knapper Benchmark-Sieg. Es ist ein Vorteil auf Workflow-Ebene. Der Quellartikel wertet den Abstand von 342 Punkten bei GDPval-AA als das stärkste Signal dafür, dass Flash nachtrainiert wurde für echte agentische Arbeit und nicht nur für herkömmlichen Chat.
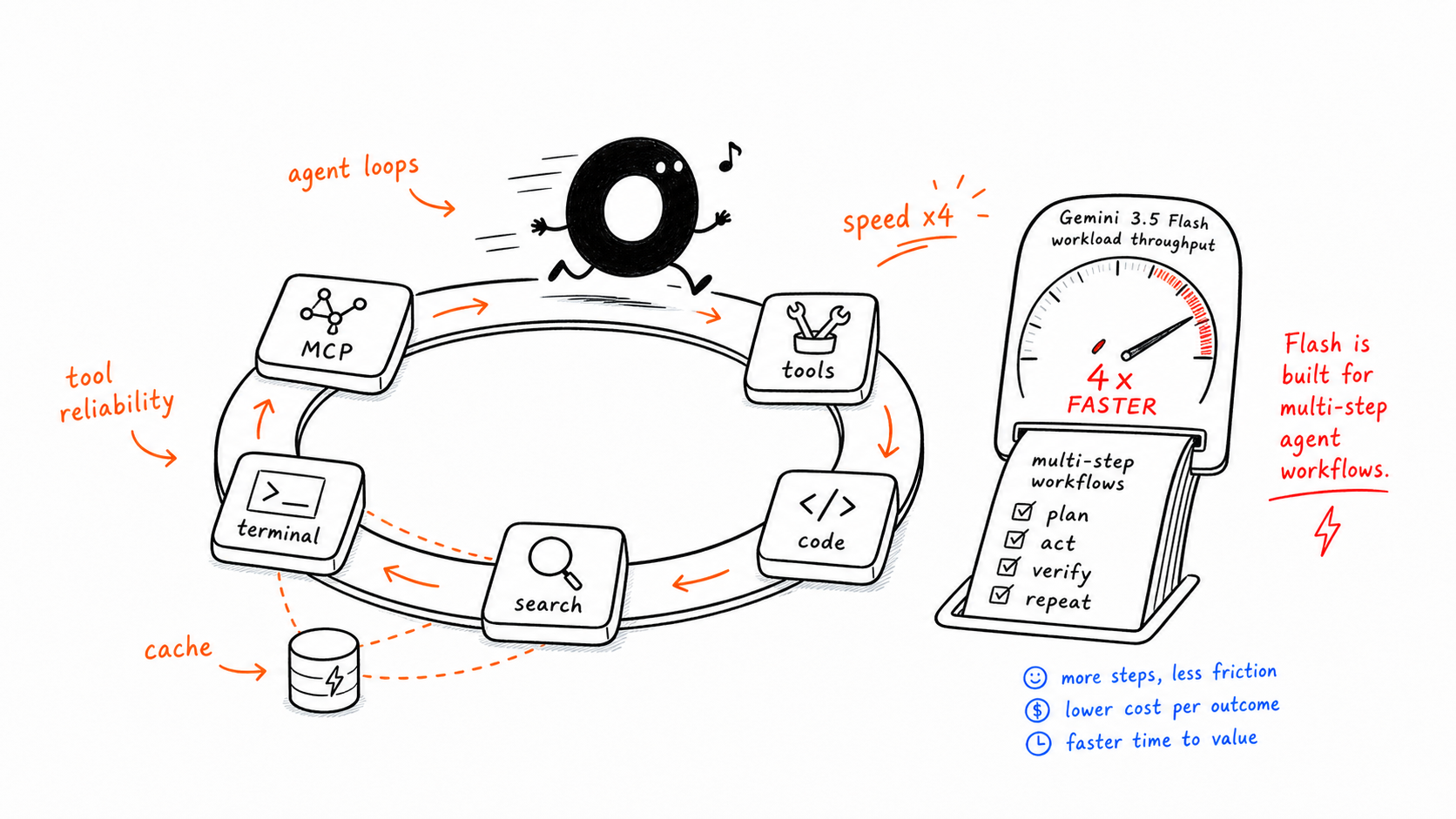
Wenn Ihr Team Folgendes entwickelt:
MCP-Tool-Schleifen
Forschungs- oder Automatisierungsagenten
terminalbasierte Programmierassistenten
hochfrequente, mehrstufige Workflows
dann ist Flash nicht nur günstiger. Es ist schneller, schleifenfreundlicher, cache-freundlicher und besser auf wiederholte Ausführung ausgelegt.
Das ist besonders relevant für Systeme im Stil von We0 AI, bei denen die Modellausgabe umgewandelt wird in:
Content-Produktionspipelines
Dokumentation für Showcase-Websites und FAQ-Generierung
SEO-/GEO-Artikel-Workflows
Wissensdatenbank- und Support-Automatisierung
Workload 2: Needle-in-Haystack-Abruf über lange Dokumente hinweg
Urteil der Quelle: Pro ist hier weiterhin die sicherere Wahl.
Das ist die wichtigste Ausnahme im gesamten Artikel. Flash ist in absoluten Zahlen nicht „schlecht“, aber wenn die Aufgabe darin besteht, eine einzige exakte Klausel in einem sehr langen Dokument zu finden, bleibt Pro die verlässlichere Wahl.
Benchmark
Gemini 3.5 Flash
Gemini 3.1 Pro
MRCR v2 (128k)
77,3 %
84,9 %
MRCR v2 (1M)
26,6 %
26,3 %
Die 128k
Slice ist das praktische Warnsignal. Wenn Ihr Versprechen lautet: „Laden Sie den gesamten Vertrag hoch und fragen Sie alles“, dann ist dies nicht die Kategorie, zu der Sie jetzt blind zu Flash wechseln sollten.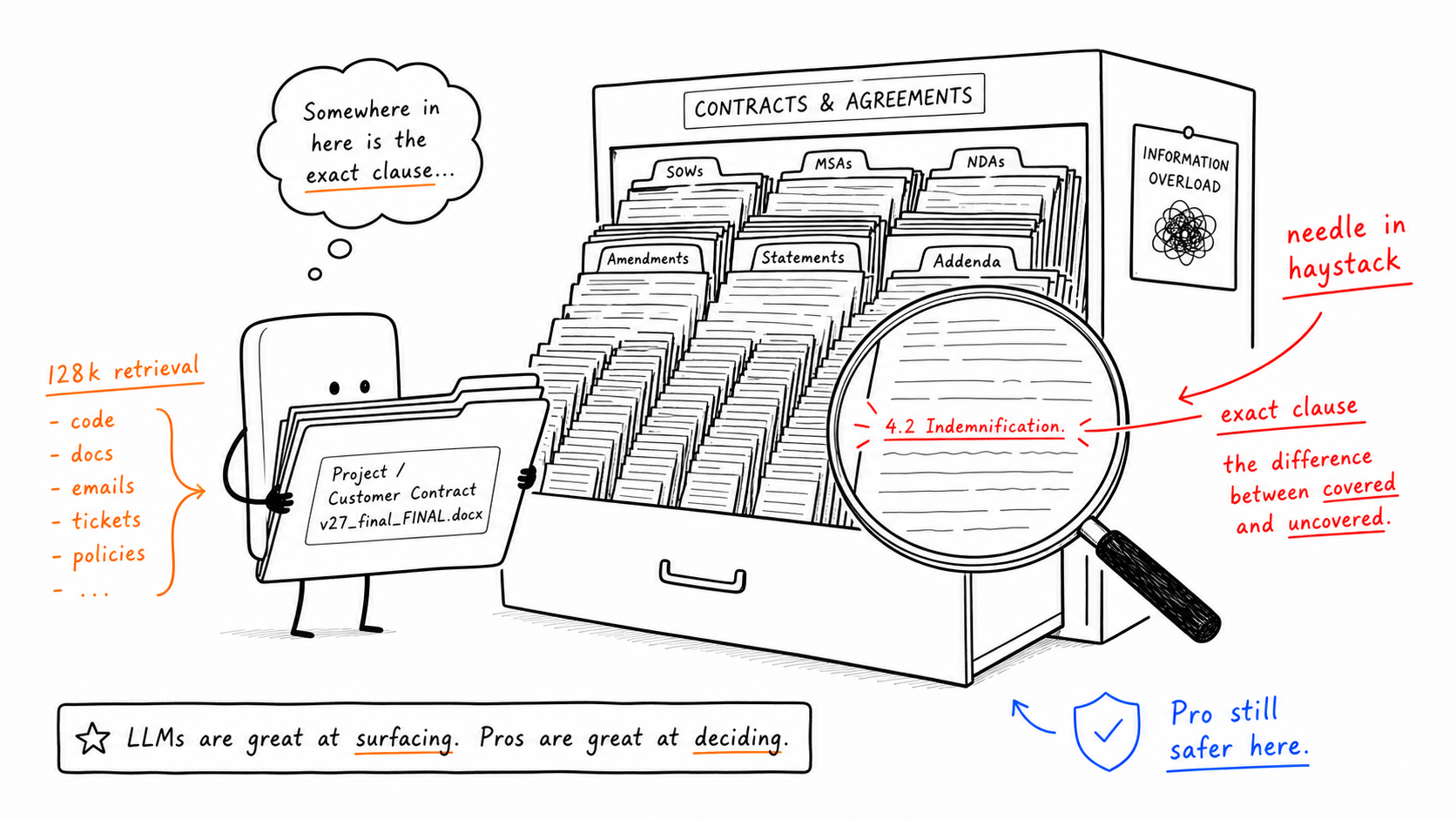
Das ist wichtig für Workloads wie:
Suche nach Vertragsklauseln
Compliance- und Rechtsprüfung
Suche in langen technischen Spezifikationen
dateiübergreifende Rückverfolgbarkeit in großen Codebasen
Die zugrunde liegende Regel ist einfach: Wenn der schwierigste Teil nicht das Generieren ist, sondern das präzise Auffinden des richtigen Satzes in einem riesigen Kontext, dann verdient Pro den Auftrag nach wie vor.
Workload 3: Hochfrequenz-RAG mit stabilem Korpus
Fazit zur Quelle: Flash mit aggressivem Caching ist die naheliegende Standardwahl.
Dies ist das Szenario, das für SaaS-Supportsysteme, interne Wissenswerkzeuge und dokumentationslastige Produkte am relevantesten ist. Die größten Kosten entstehen oft nicht durch eine einzelne Antwort, sondern durch wiederholte Lesezugriffe auf denselben System-Prompt und stabile Dokumentationspräfixe.
Faktor
Gemini 3.5 Flash
Gemini 3.1 Pro
Eingabepreis
1,50 $ / 1 Mio.
2,00 $ / 1 Mio.
Ausgabepreis
9,00 $ / 1 Mio.
12,00 $ / 1 Mio.
Zwischengespeicherte Eingabe
0,15 $ / 1 Mio.
0,50 $ / 1 Mio.
Durchsatz
289 Tok./s
~70 Tok./s
Der wichtigste Punkt hier ist, dass die Cache-Ökonomie wichtiger sein kann als der vordergründige Preisunterschied zwischen den Modellen.
Wenn Sie Folgendes entwickeln:
Help-Center-RAG
interne SOP-Assistenten
Assistenten für Produktdokumentation und FAQs
Vertriebs- oder Support-Retrieval-Systeme über stabile Inhalte hinweg
Dann ist Flash oft das, was das System nicht nur möglich, sondern auch skalierbar macht.
Das passt auch zur breiteren Logik von We0 AI: Inhalte sollten nicht nur existieren. Sie sollten durchsuchbar, empfehlbar, wiederverwendbar sein und im Laufe der Zeit weiterhin Leads generieren können. Stabile Korpora und cachefreundliche Modellmuster sind ganz natürlich auf dieses Ziel ausgerichtet.
Workload 4: ARC-artiges abstraktes Schlussfolgern
Fazit der Quelle: Das ist weiterhin Pro-Territorium.
Sobald die Aufgabe eher wie ein Rätsel, eine Herausforderung mit abstrakten Mustern, ein schwieriges Olympiadeproblem oder eine Neuheit auf Expertenniveau aussieht, ist Flash nicht länger der klare Favorit.
Benchmark
Gemini 3.5 Flash
Gemini 3.1 Pro
ARC-AGI-2
72,1 %
77,1 %
Humanity's Last Exam
40,2 %
44,4 %
Der Quellartikel trifft die Unterscheidung sehr klar: Flash ist auf agentische Breite optimiert. Pro verfügt weiterhin über eine höhere Obergrenze beim Schlussfolgern.
Wenn der Wert Ihrer Anwendung von Folgendem abhängt:
echtem abstraktem Schlussfolgern
Zuverlässigkeit bei den schwierigsten Fragen
dem Lösen neuartiger Probleme
forschungsnahen Aufgaben
dann ist es heute immer noch die konservativere Entscheidung, bei Pro zu bleiben.
Workload 5: Terminalbasierte Coding-Agenten
Fazit der Quelle: Flash für die meisten terminalbasierten Coding-Aufgaben, mit einer wichtigen Ausnahme.
Benchmark
Gemini 3.5 Flash
Gemini 3.1 Pro
Terminal-Bench 2.1
76,2 %
70,3 %
SWE-Bench Pro (öffentlich)
55,1 %
54,2 %
Blueprint-Bench 2
33,6 %
26,5 %
Dies ist einer der praxisnahesten Abschnitteim Artikel, weil es dem realen Verhalten von Entwicklern sehr nahekommt:
einen Stack-Trace beheben
eine Funktion über mehrere Dateien hinweg implementieren
Tests ausführen, Code patchen und es erneut versuchen
eine Spezifikation in Code umsetzen
Für diese Art von hochfrequenter, iterativer, tool-intensiver Programmierung ist Flash die stärkere Standardwahl.
Die Einschränkung ist jedoch wichtig: Refactorings in großen Codebasen über mehrere Dateien hinweg mit hohem Kontextbedarf sind in Wahrheit ein Long-Context-Retrieval-Problem in Verkleidung. Hier behauptet Pro weiterhin einen gewissen Vorsprung.
Der Entscheidungsbaum
Der Entscheidungsbaum des Originalartikels ist es wert, beibehalten zu werden, weil er tatsächlich nutzbar ist:
Besteht Ihre Arbeitslast hauptsächlich aus Agent-Schleifen oder Tool-Nutzung?
├─ JA → Gemini 3.5 Flash
└─ NEIN → Handelt es sich um Long-Context-Retrieval über 100k+ Token?
├─ JA → Gemini 3.1 Pro
└─ NEIN → Geht es um abstraktes Denken / die schwierigsten Expertenfragen?
├─ JA → Gemini 3.1 Pro oder Deep Think
└─ NEIN → Handelt es sich um RAG mit stabilem Korpus?
├─ JA → Gemini 3.5 Flash mit aggressivem Caching
└─ NEIN → Standardmäßig Gemini 3.5 FlashFür die meisten Teams lautet die eigentliche Botschaft: Flash sollte wahrscheinlich Ihr Standardmodell sein, aber nicht Ihr einziges Modell.
Was sich im Juni nicht ändert
Der Juni-Abschnitt ist klug, weil er direkt auf die naheliegende Anschlussfrage eingeht: Sollten Sie einfach auf Gemini 3.5 Pro warten?
Die Antwort ist kein pauschales Ja oder Nein. Sie hängt von der Arbeitslast ab:
Wenn Sie jetzt sofort MCP-Agenten benötigen, ist Flash bereits den produktiven Einsatz wert.
Wenn Sie cache-freundliches RAG benötigen, hat Flash bereits einen strukturellen Kostenvorteil.
Wenn für Ihr System das Schlussfolgern entscheidend ist, ist das Hin- und Herspringen von Pro zu Flash und wieder zurück in der Regel vergeudete Bewegung.
Der Juni könnte einige Grenzen verschieben, aber er hebt die heutigen aufgabenbezogenen Abwägungen nicht auf.
Beide bereitstellen — pro Aufgabe weiterleiten
Das ist die produktionsreifste Kernaussage des Artikels und zugleich diejenige, die sich am leichtesten durch die Linse von We0 AI neu interpretieren lässt.
Für reale Anwendungen ist der bessere Schritt oft nicht, über das eine beste Modell zu streiten, sondern intelligent zu routen:
Agenten-Schleifen, Tool-Nutzung und Terminal-Coding an Flash senden
Analyse langer Dokumente und das Abrufen exakter Klauseln an Pro senden
die schwierigsten Fälle des Schlussfolgerns an ein Modell mit tiefergehendem Reasoning senden
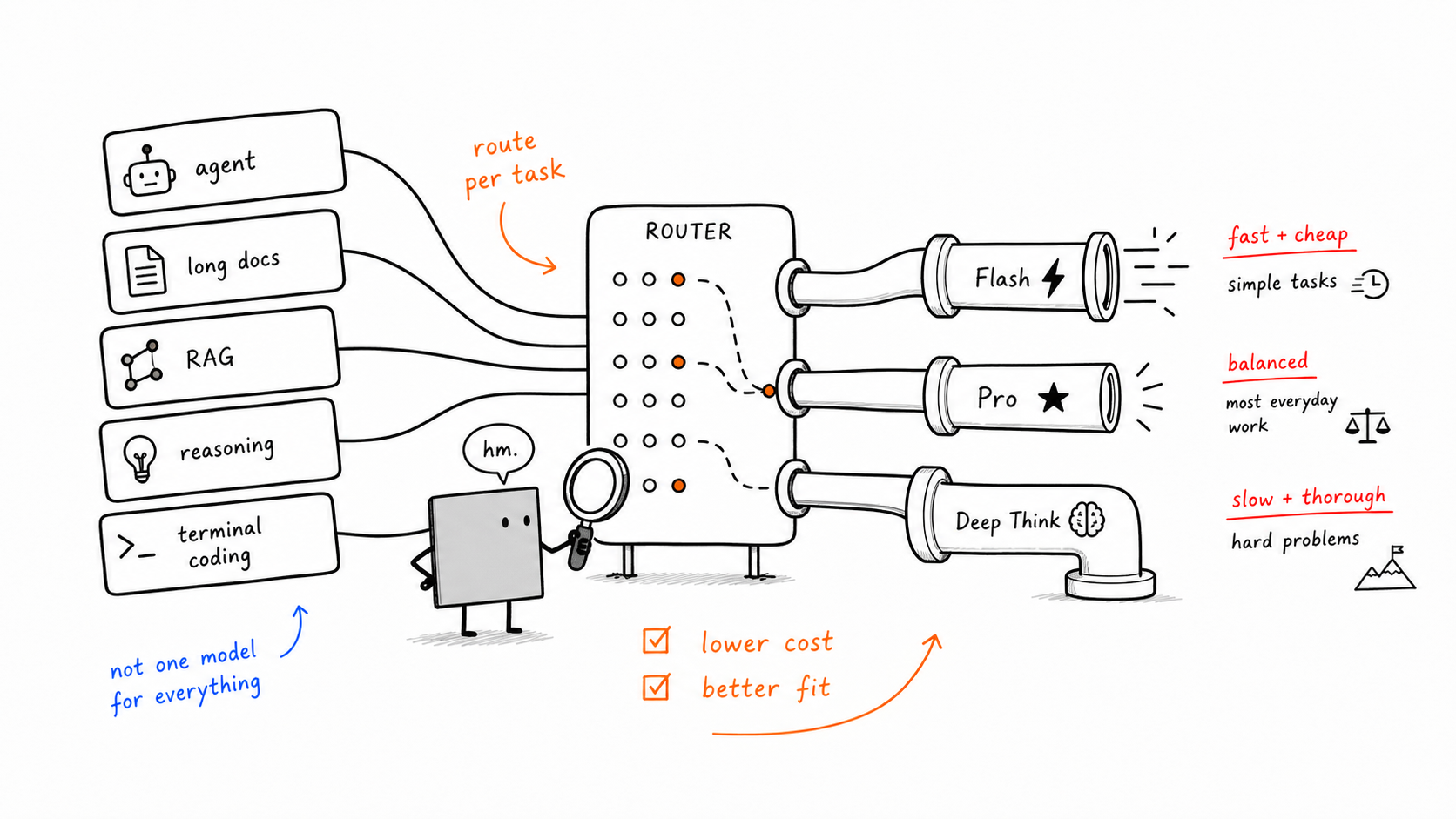
Bei We0 AI geht dasselbe Prinzip über das reine Routing von Modellen hinaus. Die vollständigere Kette sieht eher so aus:
das richtige Modell für die richtige Aufgabe wählen
die Ausgabe in nutzbare Produktinhalte, Dokumentation, FAQs und Showcase-Seiten verwandeln
diese Assets über SEO / GEO und KI-Empfehlungsflächen auffindbar machen
diese Sichtbarkeit in Leads und Kunden umwandeln
Das ist der eigentliche Grund, warum We0 AI auf Build -> Showcase -> Grow -> Leads setzt, anstatt bei „wir haben eine Modell-API integriert“ stehenzubleiben.
Bereit zum Aufbau?
Wenn Sie bereits KI-Produkte, Workflows oder Showcase-Websites entwickeln, kann dieser Vergleich in ein unkompliziertes Regelwerk für die Umsetzung übersetzt werden:
für agentische Workflows standardmäßig Flash verwenden
das Abrufen aus langen Dokumenten anPro
stabile Korpora und FAQs für Cache-Effizienz strukturieren
Modellausgaben in Dokumentation, Help-Center-Inhalte, Fallstudien und Suchressourcen umwandeln
Für We0 AI besteht das Ziel nicht nur darin, einem Team dabei zu helfen, ein Modell anzubinden. Es geht darum, ihnen zu helfen, diese Fähigkeiten in vorzeigbare, durchsuchbare und leadgenerierende Systeme zu verwandeln.
FAQ
Sollte ich Gemini 3.1 Pro überall durch Gemini 3.5 Flash ersetzen?
Nein. Agentische Workflows, Terminal-Coding und MCP-Tool-Schleifen sind starke Kandidaten für Flash. Long-Document-Retrieval, abstraktes Denken und Workloads mit den schwierigsten Fragen sind bei Pro weiterhin die sicherere Wahl.
Ist Gemini 3.5 Flash insgesamt tatsächlich stärker?
Basierend auf den veröffentlichten Benchmarks im Quellartikel gewinnt Flash 11 von 15 und ist besonders stark bei MCP Atlas, Terminal-Bench 2.1, Finance Agent v2 und Blueprint-Bench 2.
Welches ist günstiger?
Flash ist laut Listenpreis günstiger, aber der wichtigere Unterschied liegt in der Preisgestaltung für zwischengespeicherte Eingaben. Bei stabilen Präfixen und wiederholten RAG-ähnlichen Workloads wird diese Lücke deutlich größer.
Ist Gemini 3.5 Flash gut für Dokumenten-Retrieval mit langem Kontext?
Nicht, wenn die Hauptanforderung die exakte Klauselabfrage über sehr lange Dokumente hinweg ist. Die MRCR-v2-128k-Werte des Quellartikels sprechen dort weiterhin für Pro.
Welches Modell sollte ich für Terminal-Coding-Agenten verwenden?
Für die meisten werkzeugintensiven, iterativen Terminal-Coding-Aufgaben ist Flash die bessere Standardwahl. Für massive, dateiübergreifende Refactorings in sehr großen Repositories ist Pro weiterhin eine Überlegung wert.
Sollte ich auf Gemini 3.5 Pro warten?
Wenn Ihre Pipeline stark vom Reasoning abhängt und die Wartezeit nur ein paar Wochen beträgt, kann Warten sinnvoll sein. Wenn Sie jetzt MCP-Agenten, Terminal-Coding und schnelle Workflows benötigen, ist Flash
ist bereits versandwürdig.Verwandte Artikel
Vollständiger Leitfaden zu Gemini 3.5 Flash: Benchmarks, Preise und API-Erkenntnisse
Entwicklerleitfaden zu Gemini 3.5 Flash: drei API-Fallen und ein echter MCP-Agent
Produktionsreife Apps mit Gemini 3 Flash entwickeln: Architektur, Leistung und Kosten
Gemini 3.1 Pro vs. GPT-5.4: So wählen Sie je nach Workload
Freundschaftslinks
Anthropic — Frontier-KI-Modelle und Forschung zur KI-Sicherheit.
Hugging Face — Open-Source-KI-Modelle, Datensätze und ML-Tools.
Vercel — Bereitstellungsplattform für moderne Webanwendungen.
LangChain — Framework für die Entwicklung von LLM-gestützten Anwendungen.
Pinecone — Vektordatenbank für KI-Retrieval-Systeme.
Cloudflare — Leistung, Sicherheit und Edge-Infrastruktur.
We0 AI — Erstellen,Präsentieren, wachsen und Leads mit KI generieren.

