
Qwen-AgentWorld es un modelo lingüístico del mundo publicado por el equipo de Qwen para simular entornos de agentes. En lugar de limitarse a responder preguntas como un modelo de chat general, está diseñado para predecir qué devolvería un entorno después de que un agente realiza una acción.
Esto lo hace especialmente relevante para la investigación sobre agentes de IA, el aprendizaje por refuerzo simulado, la evaluación de benchmarks y los experimentos locales en torno a entornos de terminal, ingeniería de software, búsqueda, MCP, web, sistemas operativos y estilo Android.
Este artículo es una versión ligeramente reescrita y traducida del artículo original en chino. Se conservan la estructura, el flujo técnico, los comandos, las tablas y las ideas clave, mientras que el lenguaje se ha ajustado para una lectura más fluida en inglés y para la publicación SEO.
Nota de la fuente: El artículo original se publicó en CSDN e indica que sigue la licencia CC BY-SA 4.0. Fuente original: Guía completa de despliegue de Qwen-AgentWorld: gratis y de código abierto, rendimiento superior a GPT-5.4, en marcha en 5 minutos. Nota de verificación: Las páginas oficiales de Qwen confirman el lanzamiento público de los pesos del modelo
Qwen-AgentWorld-35B-A3By deAgentWorldBench. El modelo más grandeQwen-AgentWorld-397B-A17Bse incluye en los resultados oficiales de benchmarks, pero la página pública del modelo y la publicación en GitHub apuntan principalmente a los pesos del modelo 35B-A3B.
1. Contexto: ¿Por qué necesitamos un modelo lingüístico del mundo?
Durante los últimos dos años, los agentes de IA han pasado rápidamente de simples asistentes de chat a herramientas capaces de operar sitios web, ejecutar comandos de terminal, controlar aplicaciones móviles y completar tareas de ingeniería de software.
Pero entrenar a un agente potente es costoso. A menudo requiere grandes volúmenes de interacción con entornos reales, y eso genera varios problemas prácticos:
Construir y mantener entornos es tedioso.
La recopilación de datos es lenta y difícil de escalar.
Los entornos reales conllevan riesgos, especialmente al probar casos de fallo o introducir interrupciones controladas.
Un Modelo de Mundo Lingüístico, o LWM, está diseñado para resolver este problema. La idea es simple pero poderosa: permitir que un modelo desempeñe el papel del entorno. Dada una acción del agente y el historial de interacción, el modelo predice el siguiente estado del entorno.
Con esta configuración, los agentes pueden entrenarse y evaluarse en simulación en lugar de depender siempre de sistemas reales.
El 24/06/2026, el equipo de Qwen lanzó Qwen-AgentWorld, un modelo de mundo lingüístico nativo que unifica siete dominios de interacción de agentes en un solo modelo. También se lanzó el benchmark complementario, AgentWorldBench.
Recursos oficiales:
GitHub: QwenLM/Qwen-AgentWorld
2. Idea central: ¿Qué lo convierte en un modelo del mundo “nativo”?
La palabra nativo es importante aquí. Qwen-AgentWorld no es simplemente un LLM de propósito general adaptado después del entrenamiento para imitar un entorno. Su objetivo de modelado del mundo está integrado en el proceso de entrenamiento desde el principio.
Dimensión de comparación | Enfoque tradicional | Qwen-AgentWorld |
Punto de partida del entrenamiento | Ajustar finamente un LLM general | Tratar el modelado del entorno como el objetivo desde el CPT en adelante |
Proceso de entrenamiento | Normalmente solo SFT o RL | CPT → SFT → RL |
Conocimiento del entorno | Añadido mediante datos adicionales o adaptación | Internalizado durante el entrenamiento |
Cobertura del dominio | Uno o unos pocos dominios | Siete dominios en un solo modelo |
En otras palabras, Qwen-AgentWorld no es simplemente un modelo general envuelto con prompts. Está entrenado desde las capas inferiores del proceso para predecir el siguiente estado de un entorno.
Eso proporciona al modelo una comprensión más estructurada de la dinámica del entorno, especialmente al simular trayectorias de interacción largas.
3. Siete dominios: entornos de texto y GUI en un solo modelo
Qwen-AgentWorld divide los escenarios de interacción de agentes en dos grandes grupos: entornos basados en texto y entornos basados en GUI.
┌──────────────────────────────────────────┐
│ Qwen-AgentWorld │
│ │
│ Entornos de texto Entornos GUI │
│ ┌──────────┐ ┌──────────────────┐ │
│ │ MCP │ │ Web │ │
│ │ Búsqueda│ │ SO │ │
│ │ Terminal│ │ Android │ │
│ │ SWE │ └──────────────────┘ │
│ └──────────┘ │
└──────────────────────────────────────────┘Dominio | Tipo | Descripción |
MCP | Texto | Llamadas a herramientas e interacciones con el Protocolo de Contexto del Modelo |
Búsqueda | Texto | Interacción con motores de búsqueda y comportamiento de recuperación |
Terminal | Texto | Ejecución de comandos en la terminal de Linux |
SWE | Texto | Tareas de ingeniería de software, como correcciones de código |
Web | GUI | Interacción con navegadores y páginas web |
SO | GUI | Interacción con sistemas operativos de escritorio |
Android | GUI | Interacción con aplicaciones móviles e interfaces de usuario de estilo Android |
En los tres dominios de GUI, las observaciones se representan como código renderizable en lugar de fotogramas de píxeles sin procesar. Esto permite que un modelo del mundo basado en texto cubra entornos visuales sin procesar directamente secuencias completas de imágenes.
El modelo se entrenó con más de 10 millones de trayectorias de interacción del mundo real en los siete dominios.
4. Canal de entrenamiento de tres etapas
Qwen-AgentWorld utiliza un canal de entrenamiento conectado de tres etapas: CPT → SFT → RL.
Etapa 1: CPT — Inyección de conocimiento del entorno
Durante el preentrenamiento continuo, el modelo aprende a partir de trayectorias de interacción con entornos reales a gran escala. Esta etapa incorpora la dinámica del entorno en los pesos del modelo.
El artículo original también menciona una máscara de pérdida informativa a nivel de turno basada en la teoría de la información. El objetivo es identificar qué turnos del diálogo realmente contienen información sobre el estado del entorno y reducir el ruido de los turnos menos útiles.
Etapa 2: SFT — Activación del razonamiento de cadena de pensamiento
El ajuste fino supervisado convierte la predicción del siguiente estado en un patrón de razonamiento de estilo cadena de pensamiento.
En lugar de generar directamente un resultado predicho, el modelo aprende a razonar por qué debería cambiar un estado antes de generar la siguiente observación.
Etapa 3: RL — Refinamiento de la fidelidad de la simulación
La etapa de aprendizaje por refuerzo utiliza señales de recompensa híbridas, incluido el algoritmo GSPO, para mejorar la calidad de la salida.
La optimización se centra en:
Corrección del formato
Precisión factual
Coherencia del contexto
Realismo
Calidad general de la simulación
Comportamientos emergentes mencionados en el artículo original: Según se informa, Qwen-AgentWorld muestra comportamiento de autocorrección, prevención de fugas de información en escenarios de búsqueda y razonamiento causal de varios pasos para algunas predicciones de salida de comandos.
5. Lista de modelos de código abierto
Lanzamiento | Parámetros | Parámetros activados | Longitud de contexto | Posicionamiento |
Qwen-AgentWorld-35B-A3B | 35B | 3B | 256K tokens | Modelo abierto público y eficiente |
Qwen-AgentWorld-397B-A17B | 397B | 17B | No aparece claramente en la tabla original | Modelo de referencia insignia |
AgentWorldBench | — | — | — | Benchmark de evaluación |
Detalles de la arquitectura 35B-A3B
Modelo base: Qwen3.5-35B-A3B-Base
Tipo de modelo: Modelo de lenguaje causal / Modelo de mundo lingüístico
Estilo de arquitectura: Atención lineal híbrida + MoE
Dimensión oculta: 2048
Capas: 40 capas
Distribución de capas: grupos repetidos con componentes Gated DeltaNet, Gated Attention y MoE
Expertos: 256 expertos
Expertos activados: 8 expertos enrutados + 1 experto compartido
Longitud de contexto: 262,144 tokens
Contexto mínimo recomendado: 128K tokens para una mejor calidad de simulación de trayectorias largas
La documentación oficial de Hugging Face también señala que el modelo es compatible con Transformers, vLLM y SGLang.
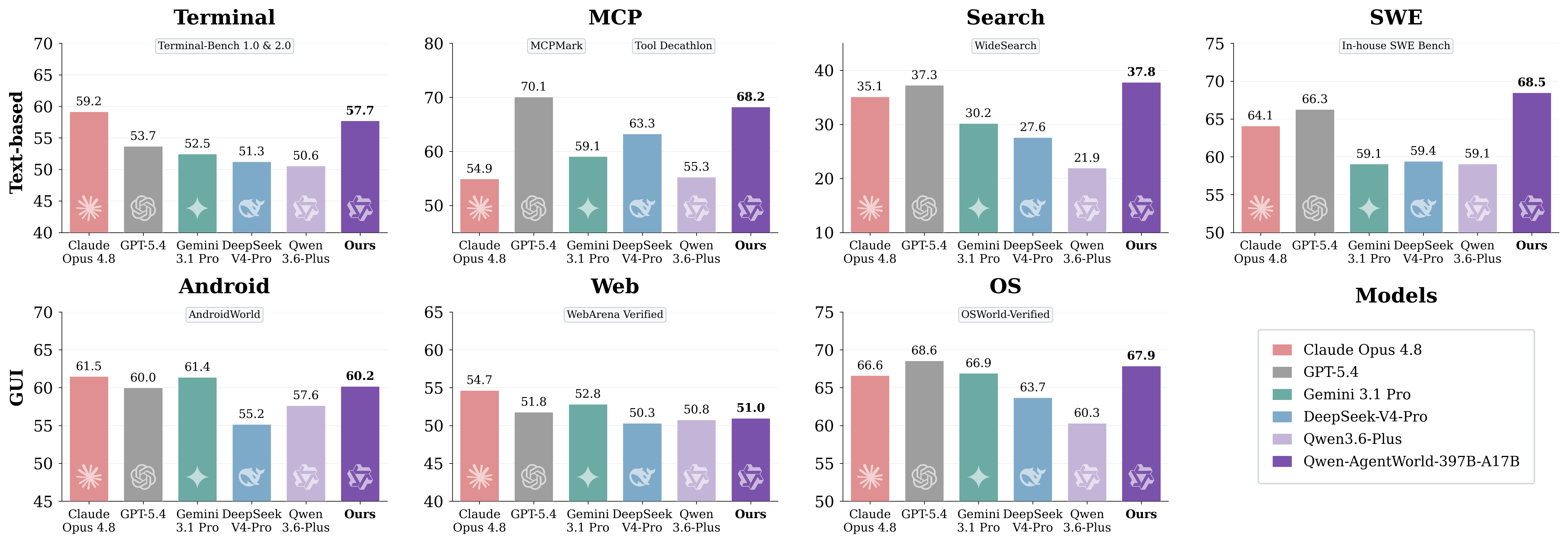
6. Comparación de rendimiento: resultados de AgentWorldBench
AgentWorldBench puntúa cada modelo en cinco dimensiones: Formato, Factualidad, Coherencia, Realismo y Calidad. Las puntuaciones se normalizan en una escala de 0 a 100, donde una puntuación más alta es mejor.
Clasificación completa por puntuación general
Modelo | MCP | Búsqueda | Terminal | SWE | Android | Web | SO | General |
Qwen-AgentWorld-397B-A17B | 68.24 | 37.82 | 57.73 | 68.49 | 60.20 | 50.98 | 67.89 | 58.71 |
GPT-5.4 | 70.10 | 37.26 | 53.69 | 66.29 | 60.00 | 51.80 | 68.58 | 58.25 |
Claude Opus 4.6 | 69.90 | 29.30 | 57.51 | 64.55 | 61.74 | 51.42 | 70.20 | 57.80 |
Claude Opus 4.8 | 54.93 | 35.14 | 59.18 | 64.10 | 61.50 | 54.66 | 66.62 | 56.59 |
Qwen-AgentWorld-35B-A3B | 64.79 | 36.69 | 53.96 | 65.63 | 58.17 | 49.55 | 65.92 | 56.39 |
Claude Sonnet 4.6 | 70.00 | 28.79 | 56.98 | 64.52 | 58.03 | 50.78 | 63.17 | 56.04 |
Qwen3.5-397B-A17B | 68.31 | 30.81 | 55.30 | 64.44 | 54.90 | 48.55 | 54.74 | |
Gemini 3.1 Pro | 59.07 | 30.21 | 52.47 | 59.07 | 61.40 | 52.83 | 66.92 | 54.57 |
DeepSeek-V4-Pro | 63.27 | 27.61 | 51.26 | 59.44 | 55.17 | 50.32 | 63.70 | 52.97 |
Qwen3.5-35B-A3B | 57.87 | 25.98 | 46.13 | 47.58 | 53.18 | 47.10 | 56.27 | 47.73 |
Conclusiones clave del artículo original:
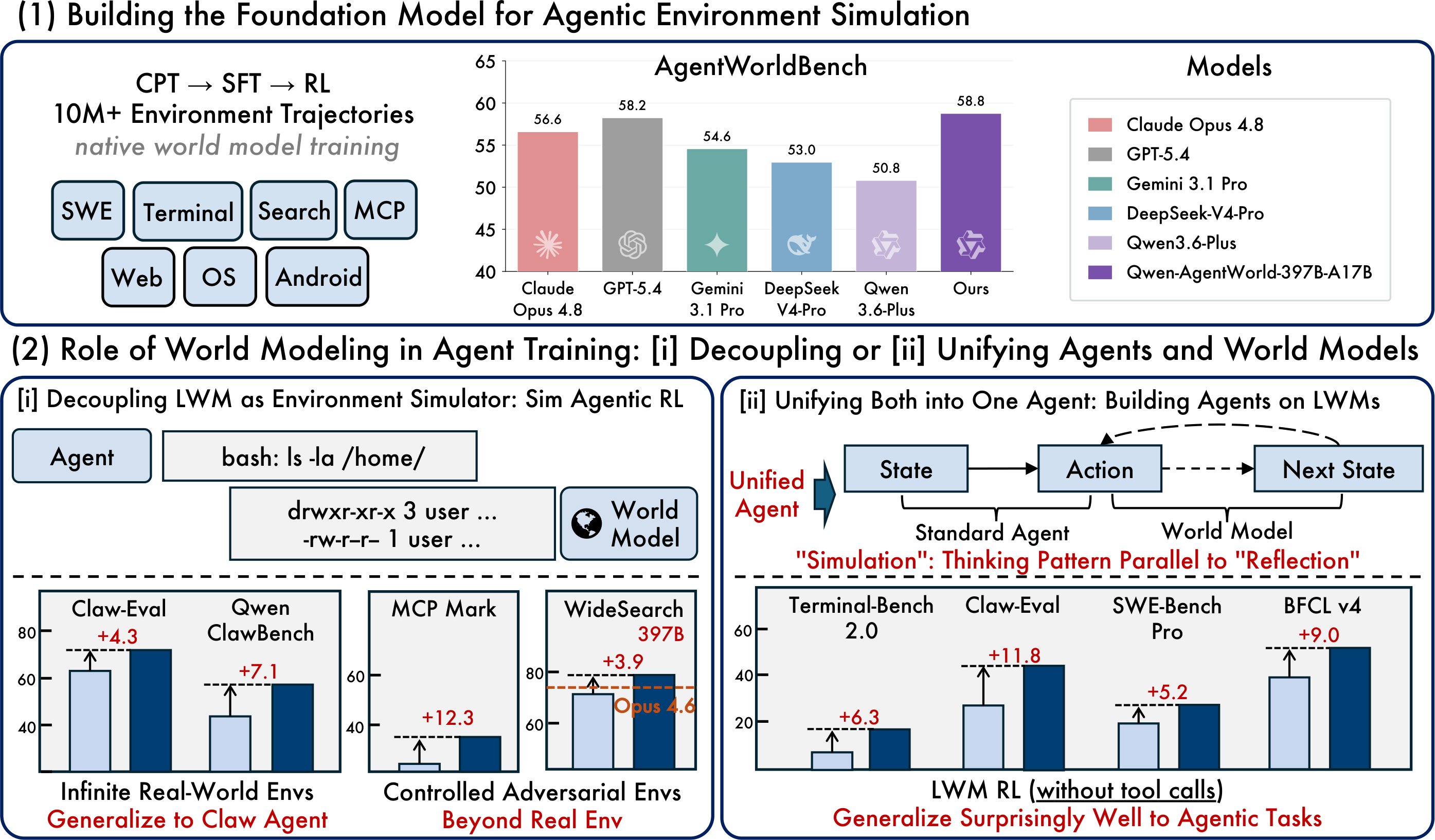
Qwen-AgentWorld-397B-A17Balcanza una puntuación general de 58.71 y ocupa el primer lugar en la tabla de AgentWorldBench indicada.Qwen-AgentWorld-35B-A3Bmejora en +8.66 puntos con respecto al modelo baseQwen3.5-35B-A3B.
Nota práctica: Trata las cifras de referencia como datos de referencia de la configuración oficial del benchmark. Los resultados reales dependerán del hardware, el diseño de prompts, el marco de servicio, la longitud del contexto y el entorno que se esté simulando.
7. Cuatro patrones de aplicación y resultados experimentales
Patrón 1: Expansión generalizable de entornos OOD
El artículo original describe el uso de Qwen-AgentWorld-397B-A17B para RL simulado en 4000 entornos OpenClaw fuera de distribución, y luego la evaluación de la generalización zero-shot en nuevos dominios.
Método de entrenamiento | Claw-Eval | QwenClawBench |
SFT base | 65.4 | 47.9 |
RL simulado con un simulador de modelo general | 66.7 | 47.8 |
RL simulado con el simulador Qwen-AgentWorld | 69.7 | 55.0 |
Mejora | +4.3 | +7.1 |
Patrón 2: Simulación controlable — Perturbación dirigida por MCP
Las perturbaciones controladas pueden revelar los puntos débiles de un agente con mayor eficacia que el entrenamiento estándar en un entorno real.
Configuración | Decatlón de herramientas | MCPMark |
SFT base | 32.4 | 21.5 |
RL simulado sin control | 31.5 | 24.6 |
RL simulado con control | 36.1 | 33.8 |
Mejora | +3.7 | +12.3 |
Patrón 3: Construcción de mundos ficticios — Dominio de búsqueda
El experimento del dominio de búsqueda utiliza un mundo de búsqueda ficticio pero autoconsistente para el entrenamiento, y luego evalúa la generalización en tareas de búsqueda reales.
Configuración | Ítem F1 de WideSearch | Fila F1 de WideSearch |
SFT base, 35B | 34.02 | 13.72 |
+ mundo ficticio con RL simulada | 50.31 | 24.21 |
Mejora | +16.29 | +10.49 |
Patrón 4: Modelo fundacional de agente — Transferencia de calentamiento de RL de LWM
El artículo también describe el calentamiento de RL de LWM como una forma de mejorar el rendimiento de los agentes posteriores sin ajuste fino adicional de RL en esas tareas específicas.
Métrica | Terminal-Bench 2.0 | SWE-Bench Verified | SWE-Bench Pro | WideSearch F1 | Claw-Eval | BFCL v4 |
SFT base | 33.25 | 64.47 | 42.18 | 33.38 | 53.60 | 62.29 |
+ calentamiento LWM RL | 39.55 | 67.86 | 47.42 | 46.17 | 64.88 | 71.25 |
Mejora | +6.30 | +3.39 | +5.24 | +12.79 | +11.28 | +8.96 |
Punto destacado: Los datos de calentamiento provienen de trayectorias de un solo turno y no agénticas, pero la mejora se transfiere a tareas de agentes más complejas, de varios turnos y con llamadas a herramientas. Esto sugiere que el conocimiento de modelado del mundo puede transferirse más allá de su formato de entrenamiento original.
8. Guía rápida de implementación
Método 1: Implementar con SGLang
SGLang se recomienda en el artículo original para un servicio rápido.
pip install sglangpython -m sglang.launch_server \
--model-path Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tp-size 4 \
--context-length 262144 \
--reasoning-parser qwen3Después del inicio, el endpoint de la API compatible con OpenAI es:
http://localhost:8000/v1Método 2: Implementar con vLLM
pip install vllmvllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--trust-remote-codeNota de la documentación oficial: La tarjeta del modelo actual en Hugging Face también recomienda usar
--language-model-onlycon vLLM porque la arquitectura del modelo incluye definiciones de componentes visuales, mientras que el checkpoint contiene pesos del modelo de lenguaje. Si falla la inicialización de vLLM, prueba a añadir esa opción.
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--language-model-only \
--trust-remote-codeMétodo 3: Inferencia local con Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
messages = [
{
"role": "system",
"content": "Eres un modelo de mundo lingüístico que simula un entorno de terminal Linux. "
"Dado el comando del usuario, predice la salida de la terminal."
},
{
"role": "user",
"content": "Acción: execute_bash\nComando: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)Método 4: Llamar a través de una API compatible con OpenAI
Este método funciona después de servir el modelo mediante SGLang o vLLM.
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
messages = [
{
"role": "system",
"content": "Eres un modelo de mundo lingüístico que simula un entorno de terminal Linux."
},
{
"role": "user",
"content": "Acción: execute_bash\nComando: pwd"
}
]
response = client.chat.completions.create(
model="Qwen/Qwen-AgentWorld-35B-A3B",
messages=messages,
max_tokens=32768,
temperature=0.6,
)
print(response.choices[0].message.content)Mejores prácticas
Muestreo recomendado:
temperature=0.6,top_p=0.95,top_k=20
Longitud de salida recomendada: alrededor de 32,768 tokens para la mayoría de las observaciones largas
Usa los prompts de sistema específicos del dominio del directorio
prompts/del repositorio para mejorar la calidad de la simulaciónMantén la longitud del contexto en al menos
128Ksiempre que sea posible; el contexto predeterminado del modelo es de256K
9. Flujo de trabajo de evaluación de AgentWorldBench
Si quieres probar tu propio modelo de mundo en AgentWorldBench, el artículo original ofrece un flujo de trabajo de tres pasos.
# 1. Clonar el repositorio de evaluación
git clone https://github.com/QwenLM/Qwen-AgentWorld.git
cd Qwen-AgentWorld
# 2. Descargar el conjunto de datos de evaluación
huggingface-cli download Qwen/AgentWorldBench --repo-type dataset --local-dir ./AgentWorldBench
# 3. Instalar dependencias
pip install openai
cd eval
# Paso 1: inferencia del modelo de mundo
python eval.py infer \
--data-dir ../AgentWorldBench \
--model-base-url http://localhost:8000/v1 \
--model-name Qwen/Qwen-AgentWorld-35B-A3B \
--output-dir ./results
# Paso 2: puntuación con un juez LLM. Esto requiere una clave de API de OpenAI.
export OPENAI_API_KEY="your-api-key"
python eval.py judge \
--predictions ./results/predictions.jsonl \
--judge-base-url https://api.openai.com/v1 \
--judge-model gpt-5.2-2025-12-11 \
--output-dir ./results
# Paso 3: agregar las puntuaciones
python eval.py score --predictions ./results/judged.jsonlCada muestra de prueba incluye datos de observación de referencia obtenidos de la ejecución en un entorno real. El benchmark evalúa la capacidad de modelado del mundo en términos de formato, veracidad, coherencia, realismo y calidad.
10. Sugerencias para el ajuste fino
Si deseas personalizar Qwen-AgentWorld para un dominio específico, el artículo original recomienda tres marcos comunes de ajuste fino.
Marco | Fortaleza | Escenario adecuado |
Alta integración con ModelScope | Experimentos rápidos y flujos de trabajo del ecosistema de Alibaba | |
Comunidad activa y amplio soporte para estrategias de entrenamiento | Implementación práctica de ingeniería | |
Fuerte optimización de memoria | Ajuste fino con recursos limitados |
11. Notas sobre la fuente y gestión de imágenes
El artículo original incluye varias imágenes relacionadas con los dominios de Qwen-AgentWorld y los resultados de referencia. Estas se mantuvieron en las secciones correspondientes.
Los iconos de la plataforma CSDN, los módulos de promoción, los bloques de suscripción del autor, los códigos QR, los botones de recompensa y las imágenes de recomendación no relacionadas se eliminaron de acuerdo con los requisitos de publicación.
Preguntas frecuentes
¿Qué es Qwen-AgentWorld?
Qwen-AgentWorld es un modelo de mundo lingüístico del equipo de Qwen. Predice el siguiente estado del entorno después de que un agente realiza una acción, lo que lo hace útil para la simulación, el entrenamiento y la evaluación de agentes.
¿Qwen-AgentWorld es lo mismo que un modelo de chat normal?
No. Un modelo de chat normal está optimizado principalmente para la conversación y el seguimiento de instrucciones. Qwen-AgentWorld está entrenado como simulador de entornos, por lo que su principal caso de uso es predecir observaciones en entornos de interacción de agentes.
¿Qué modelo de Qwen-AgentWorld está disponible públicamente?
Las páginas oficiales enumeran Qwen-AgentWorld-35B-A3B como los pesos del modelo publicados públicamente. AgentWorldBench también está disponible como referencia de evaluación. El modelo más grande de 397B aparece en las tablas de referencia, pero la publicación pública del modelo apunta principalmente a la versión 35B-A3B.
¿Se puede implementar Qwen-AgentWorld con vLLM?
Sí. La tarjeta del modelo de Hugging Face incluye un ejemplo de servicio con vLLM. Si tienes problemas de inicialización, la tarjeta oficial del modelo recomienda añadir --language-model-only porque el checkpoint contiene pesos del modelo de lenguaje.
¿Se puede desplegar Qwen-AgentWorld con SGLang?
Sí. SGLang es una de las opciones de servicio recomendadas y puede exponer un endpoint de API compatible con OpenAI. Luego, el modelo se puede invocar mediante solicitudes de API locales.
¿Por qué Qwen-AgentWorld necesita una ventana de contexto larga?
La simulación de entornos de agentes suele depender de historiales de interacción largos. Una ventana de contexto más corta puede perder información de estado importante, por lo que la guía oficial recomienda mantener al menos 128K tokens siempre que sea posible.
¿Para qué se utiliza AgentWorldBench?
AgentWorldBench es el benchmark publicado junto con Qwen-AgentWorld. Evalúa modelos de mundo lingüísticos en siete dominios utilizando dimensiones como formato, factualidad, coherencia, realismo y calidad.
¿Es Qwen-AgentWorld adecuado para uso en producción?
Puede ser útil para investigación, evaluación, simulación y experimentos internos. Para sistemas de producción, aún debes evaluar la latencia, el coste de hardware, la seguridad, la fiabilidad de los prompts y si los resultados simulados se ajustan lo suficiente a tu entorno real.
Herramientas relacionadas
GitHub de Qwen-AgentWorld: Repositorio oficial del código, los prompts y el flujo de trabajo de evaluación de Qwen-AgentWorld.
Qwen-AgentWorld-35B-A3B en Hugging Face: Página oficial del modelo para los pesos públicos 35B-A3B.
AgentWorldBench: Conjunto de datos de referencia oficial para evaluar modelos de mundo lingüísticos.
SGLang: Un marco de servicio rápido para modelos de lenguaje grandes.
vLLM: Un motor de inferencia de alto rendimiento para servir LLM.
Transformers: Biblioteca de Hugging Face para la carga e inferencia de modelos locales.
SDK de Python de OpenAI: Cliente de Python que puede llamar a servidores locales de modelos compatibles con OpenAI.
ms-swift: el framework de entrenamiento y ajuste fino de ModelScope para flujos de trabajo con LLM.
Enlaces relacionados
Informe técnico de Qwen-AgentWorld: El artículo oficial de arXiv que presenta el modelo, el benchmark y la configuración de entrenamiento.
Blog oficial de Qwen-AgentWorld: La publicación oficial de lanzamiento de Qwen para el proyecto.
Repositorio de GitHub de Qwen-AgentWorld: Fuente principal para prompts, scripts de evaluación y documentación del proyecto.
Ficha del modelo Qwen-AgentWorld-35B-A3B: Página oficial de Hugging Face con ejemplos de despliegue e inferencia.
Conjunto de datos AgentWorldBench: Conjunto de datos benchmark oficial utilizado para la evaluación del modelo.
Documentación de SGLang: Documentación para servir LLM con SGLang.
Documentación de vLLM: Documentación para inferencia de LLM de alto rendimiento y servicio compatible con OpenAI.
LLaMA-Factory: Marco popular de código abierto para experimentos de ajuste fino e implementación de LLM.


