
Qwen-AgentWorld — это языковая модель мира, выпущенная командой Qwen для симуляции агентных сред. В отличие от обычной чат-модели, которая в основном отвечает на вопросы, она предназначена для прогнозирования того, что вернёт среда после выполнения агентом действия.
Это делает её особенно актуальной для исследований ИИ-агентов, симулированного обучения с подкреплением, оценки бенчмарков и локальных экспериментов, связанных с терминалом, разработкой программного обеспечения, поиском, MCP, вебом, операционными системами и средами в стиле Android.
Эта статья представляет собой слегка переработанную и переведённую версию оригинальной китайской статьи. Структура, техническая последовательность, команды, таблицы и ключевые идеи сохранены, а язык был адаптирован для более плавного чтения на английском и SEO-публикации.
Примечание об источнике: Оригинальная статья была опубликована на CSDN и указывает, что распространяется по лицензии CC BY-SA 4.0. Оригинальный источник: Полное руководство по развёртыванию Qwen-AgentWorld: бесплатно и с открытым исходным кодом, производительность выше GPT-5.4, запуск за 5 минут. Примечание о проверке: Официальные страницы Qwen подтверждают публичный релиз весов модели
Qwen-AgentWorld-35B-A3BиAgentWorldBench. Более крупнаяQwen-AgentWorld-397B-A17Bвключена в официальные результаты бенчмарков, однако публичная страница модели и релиз на GitHub в основном указывают на веса модели 35B-A3B.
1. Предыстория: зачем нам нужна языковая модель мира?
За последние два года ИИ-агенты быстро превратились из простых чат-ассистентов в инструменты, которые могут работать с веб-сайтами, выполнять команды терминала, управлять мобильными приложениями и решать задачи программной инженерии.
Однако обучение сильного агента обходится дорого. Оно часто требует больших объемов взаимодействия с реальной средой, а это создает несколько практических проблем:
Создание и поддержка сред — утомительный процесс.
Сбор данных идет медленно и плохо масштабируется.
Реальные среды сопряжены с рисками, особенно при тестировании случаев отказа или внесении контролируемых нарушений.
Языковая модель мира, или LWM, создается для решения этой проблемы. Идея проста, но эффективна: позволить модели играть роль среды. Получив действие агента и историю взаимодействия, модель прогнозирует следующее состояние среды.
При такой схеме агенты могут обучаться и оцениваться в симуляции, а не всегда полагаться на реальные системы.
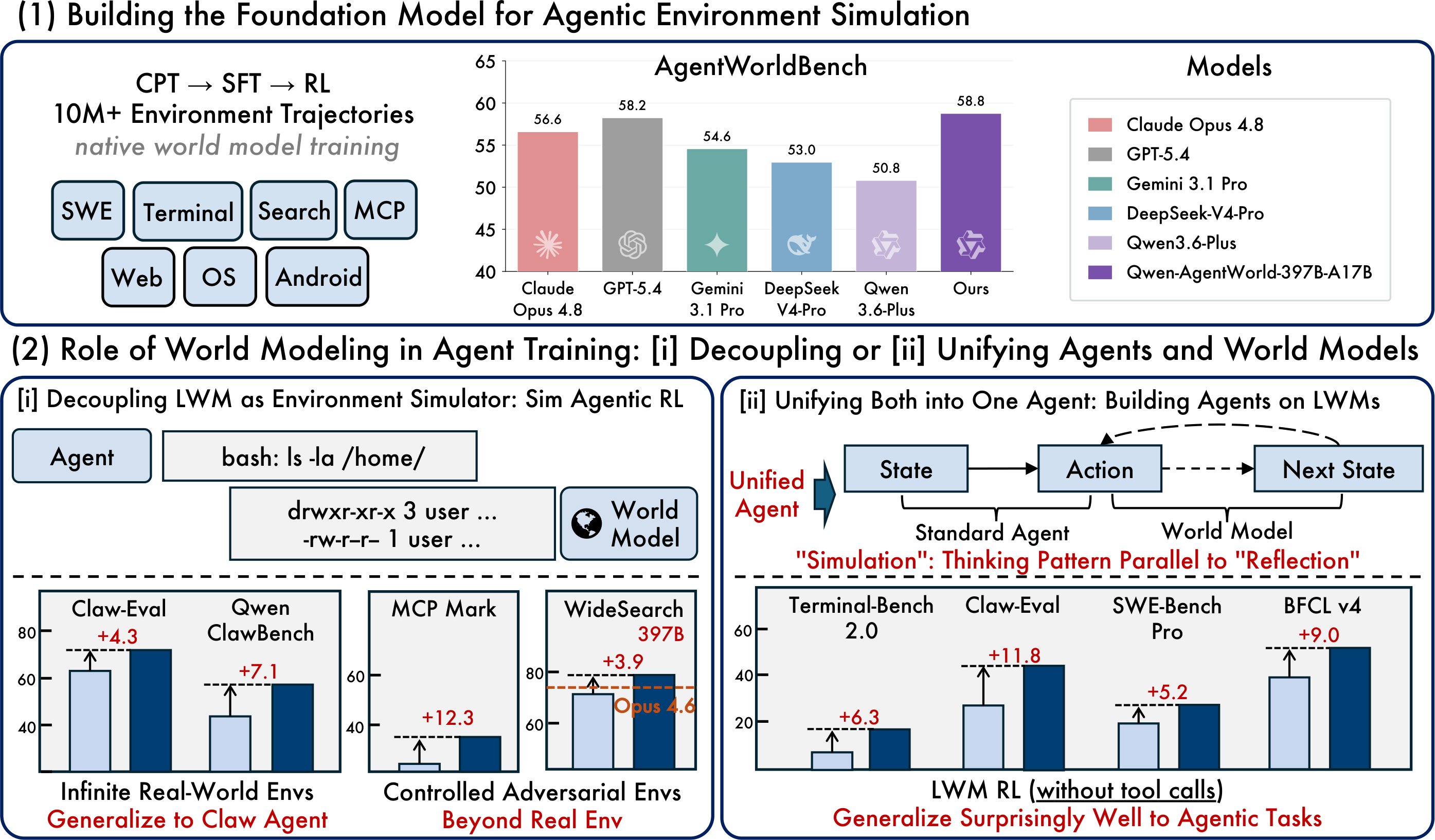
24.06.2026 команда Qwen выпустила Qwen-AgentWorld — нативную языковую модель мира, которая объединяет семь доменов взаимодействия агентов в одной модели. Также был выпущен сопутствующий бенчмарк AgentWorldBench.
Официальные ресурсы:
GitHub: QwenLM/Qwen-AgentWorld
2. Основная идея: что делает её «нативной» мировой моделью?
Слово нативной здесь важно. Qwen-AgentWorld — это не просто универсальная LLM, адаптированная после обучения для имитации среды. Её цель моделирования мира встроена в процесс обучения с самого начала.
Параметр сравнения | Традиционный подход | Qwen-AgentWorld |
Отправная точка обучения | Дообучение универсальной LLM | Рассматривает моделирование среды как цель уже начиная с CPT |
Процесс обучения | Обычно только SFT или RL | CPT → SFT → RL |
Знание среды | Добавляется с помощью дополнительных данных или адаптации | Интернализуется в ходе обучения |
Один или несколько доменов | Семь доменов в одной модели |
Иными словами, Qwen-AgentWorld — это не просто общая модель, обёрнутая подсказками. Она обучается с нижних уровней конвейера предсказывать следующее состояние среды.
Это даёт модели более структурированное понимание динамики среды, особенно при моделировании длинных траекторий взаимодействия.
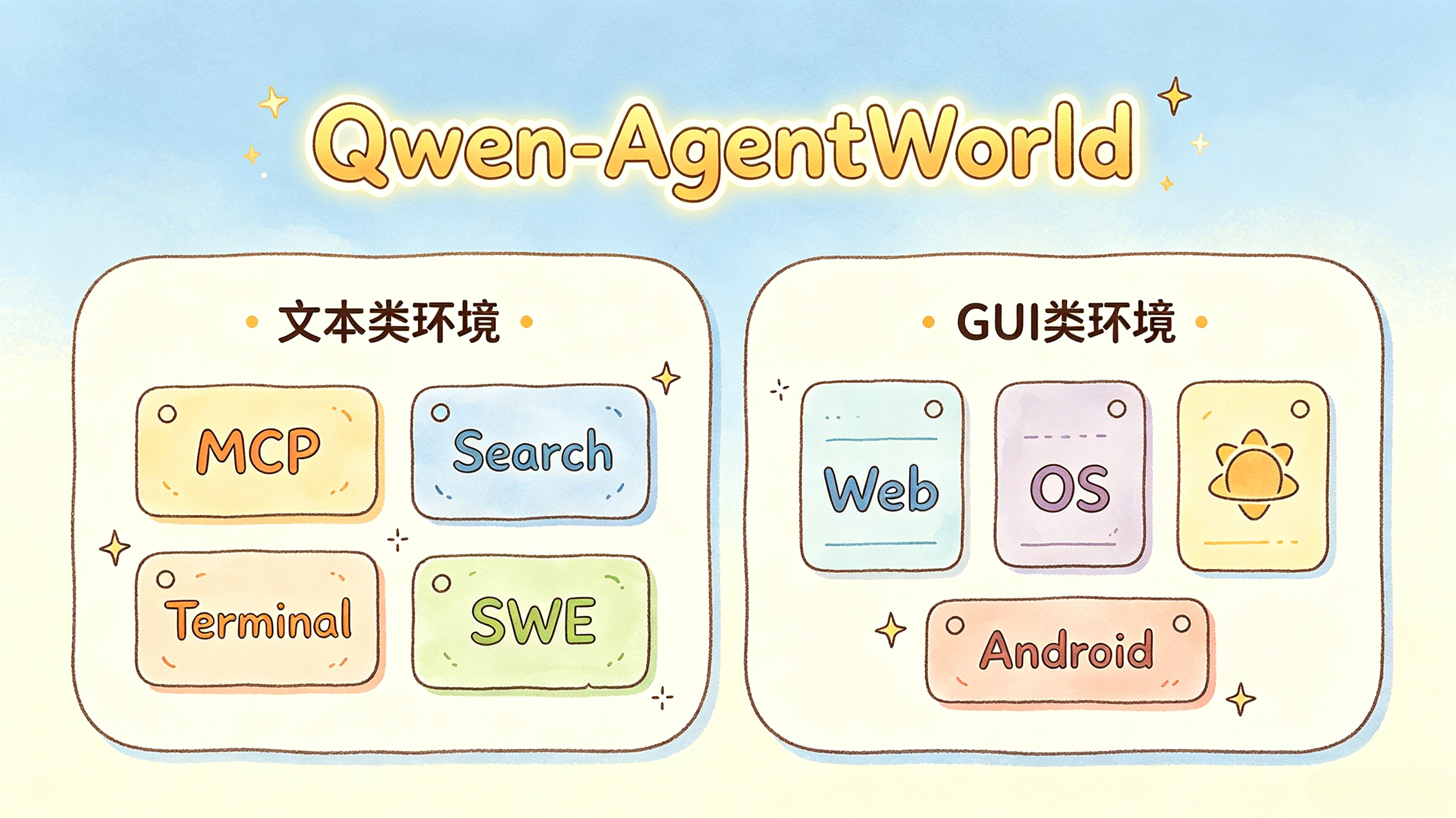
3. Семь доменов: текстовые и GUI-среды в одной модели
Qwen-AgentWorld разделяет сценарии взаимодействия агентов на две большие группы: текстовые среды и GUI-среды.
┌──────────────────────────────────────────┐
│ Qwen-AgentWorld │
│ │
│ Текстовые среды GUI-среды │
│ ┌──────────┐ ┌──────────────────┐ │
│ │ MCP │ │ Web │ │
│ │ Поиск │ │ OS │ │
│ │ Терминал│ │ Android │ │
│ │ SWE │ └──────────────────┘ │
│ └──────────┘ │
└──────────────────────────────────────────┘Домен | Тип | Описание |
MCP | Текст | Вызовы инструментов и взаимодействия по протоколу контекста модели |
Поиск | Текст | Взаимодействие с поисковой системой и поведение при извлечении данных |
Терминал | Текст | Выполнение команд в терминале Linux |
SWE | Текст | Задачи программной инженерии, такие как исправление кода |
Веб | Графический интерфейс | Взаимодействие с браузером и веб-страницами |
ОС | Графический интерфейс | Взаимодействие с настольной операционной системой |
Android | Графический интерфейс | Взаимодействие с мобильными приложениями и интерфейсом в стиле Android |
В трех доменах с графическим интерфейсом наблюдения представлены в виде кода, пригодного для рендеринга, а не необработанных пиксельных кадров. Это позволяет текстовой модели мира охватывать визуальные среды без непосредственной обработки полных последовательностей изображений.
Модель была обучена на более чем 10 миллионах реальных траекторий взаимодействия в семи доменах.
4. Трехэтапный конвейер обучения
Qwen-AgentWorld использует связанный трехэтапный конвейер обучения: CPT → SFT → RL.
Этап 1: CPT — внедрение знаний о среде
В ходе непрерывного предварительного обучения модель обучается на крупномасштабных траекториях взаимодействия с реальной средой. Этот этап встраивает динамику среды в веса модели.
В оригинальной статье также упоминается информационно-теоретическая маска потерь на уровне реплик. Цель — определить, какие реплики диалога действительно несут информацию о состоянии среды, и уменьшить шум от менее полезных реплик.
Этап 2: SFT — активация рассуждения в стиле цепочки мыслей
Контролируемая тонкая настройка превращает предсказание следующего состояния в шаблон рассуждения в стиле цепочки мыслей.
Вместо того чтобы напрямую выводить предсказанный результат, модель учится рассуждать о том, почему состояние должно измениться, прежде чем сгенерировать следующее наблюдение.
Этап 3: RL — повышение точности симуляции
Этап обучения с подкреплением использует гибридные сигналы вознаграждения, включая алгоритм GSPO, для улучшения качества вывода.
Оптимизация сосредоточена на:
Корректности формата
Фактической точности
Согласованность контекста
Реалистичность
Общее качество симуляции
Эмерджентные поведения, упомянутые в оригинальной статье: Сообщается, что Qwen-AgentWorld демонстрирует поведение самокоррекции, предотвращение утечки информации в сценариях поиска и многошаговое причинно-следственное рассуждение для некоторых предсказаний вывода команд.
5. Список моделей с открытым исходным кодом
Релиз | Параметры | Активированные параметры | Длина контекста | Позиционирование |
Qwen-AgentWorld-35B-A3B | 35B | 3B | 256K токенов | Общедоступная, эффективная открытая модель |
Qwen-AgentWorld-397B-A17B | 397B | 17B | Не указано явно в исходной таблице | Флагманская эталонная модель |
AgentWorldBench | — | — | — | Эталонный тест для оценки |
Детали архитектуры 35B-A3B
Базовая модель: Qwen3.5-35B-A3B-Base
Тип модели: каузальная языковая модель / языковая модель мира
Стиль архитектуры: гибридное линейное внимание + MoE
Скрытая размерность: 2048
Слои: 40 слоев
Компоновка слоев: повторяющиеся группы с компонентами Gated DeltaNet, Gated Attention и MoE
Эксперты: 256 экспертов
Активированные эксперты: 8 маршрутизируемых экспертов + 1 общий эксперт
Длина контекста: 262 144 токена
Рекомендуемый минимальный контекст: 128K токенов для более высокого качества моделирования длинных траекторий
Официальная документация Hugging Face также отмечает, что модель совместима с Transformers, vLLM и SGLang.
6. Сравнение производительности: результаты AgentWorldBench
AgentWorldBench оценивает каждую модель по пяти параметрам: Формат, Фактическая точность, Согласованность, Реализм и Качество. Оценки нормализованы по шкале от 0 до 100, где большее значение означает лучший результат.
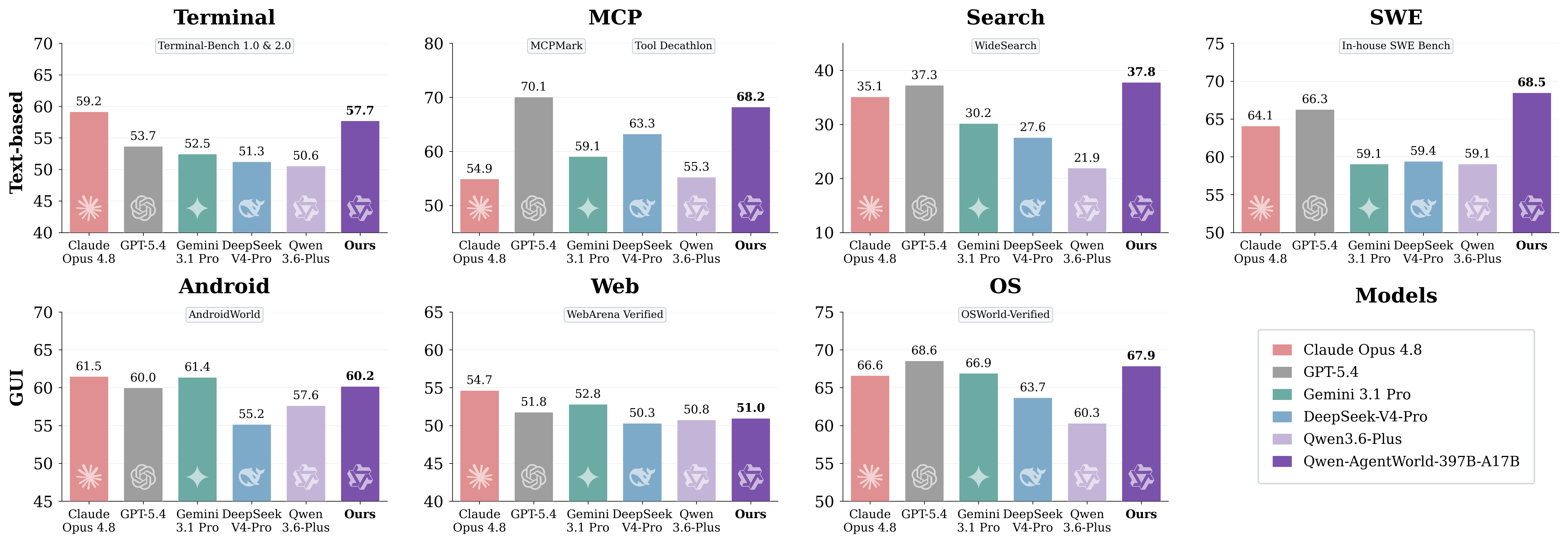
Полный рейтинг по общему баллу
Модель | MCP | Поиск | Терминал | SWE | Android | Веб | ОС | Итого |
Qwen-AgentWorld-397B-A17B | 68.24 | 37.82 | 57.73 | 68.49 | 60.20 | 50.98 | 67.89 | 58.71 |
GPT-5.4 | 70.10 | 37.26 | 53.69 | 66.29 | 60.00 | 51.80 | 68.58 | 58.25 |
Claude Opus 4.6 | 69.90 | 29.30 | 57.51 | 64.55 | 61.74 | 51.42 | 70.20 | 57.80 |
Claude Opus 4.8 | 54.93 | 35.14 | 59.18 | 64.10 | 61.50 | 54.66 | 66.62 | 56.59 |
Qwen-AgentWorld-35B-A3B | 64.79 | 36.69 | 53.96 | 65.63 | 58.17 | 49.55 | 65.92 | 56.39 |
Claude Sonnet 4.6 | 70.00 | 28.79 | 56.98 | 64.52 | 58.03 | 50.78 | 63.17 | 56.04 |
Qwen3.5-397B-A17B | 68.31 | 30.81 | 55.30 | 64.44 | 54.90 | 48.55 | 54.74 | |
Gemini 3.1 Pro | 59.07 | 30.21 | 52.47 | 59.07 | 61.40 | 52.83 | 66.92 | 54.57 |
DeepSeek-V4-Pro | 63.27 | 27.61 | 51.26 | 59.44 | 55.17 | 50.32 | 63.70 | 52.97 |
Qwen3.5-35B-A3B | 57.87 | 25.98 | 46.13 | 47.58 | 53.18 | 47.10 | 56.27 | 47.73 |
Ключевые выводы из исходной статьи:
Qwen-AgentWorld-397B-A17Bдостигает общего балла 58.71 и занимает первое место в приведённой таблице AgentWorldBench.Qwen-AgentWorld-35B-A3Bулучшает результат на +8.66 балла по сравнению с базовой модельюQwen3.5-35B-A3B.
Практическое замечание: Рассматривайте показатели бенчмарков как справочные данные из официальной конфигурации тестирования. Реальные результаты будут зависеть от аппаратного обеспечения, дизайна промптов, фреймворка для обслуживания модели, длины контекста и моделируемой среды.
7. Четыре шаблона применения и экспериментальные результаты
Шаблон 1: Обобщаемое расширение OOD-среды
В оригинальной статье описывается использование Qwen-AgentWorld-397B-A17B для имитационного RL в 4 000 средах OpenClaw вне распределения, а затем тестирование обобщения zero-shot в новых доменах.
Метод обучения | Claw-Eval | QwenClawBench |
Базовое SFT | 65.4 | 47.9 |
Sim RL с симулятором на основе универсальной модели | 66.7 | 47.8 |
Sim RL с симулятором Qwen-AgentWorld | 69.7 | 55.0 |
Улучшение | +4.3 | +7.1 |
Шаблон 2: управляемая симуляция — целевое возмущение MCP
Управляемые возмущения могут выявлять слабые места агента эффективнее, чем стандартное обучение в реальной среде.
Конфигурация | Tool Decathlon | MCPMark |
Базовая SFT | 32.4 | 21.5 |
Sim RL без контроля | 31.5 | 24.6 |
Sim RL с контролем | 36.1 | 33.8 |
Улучшение | +3.7 | +12.3 |
Паттерн 3: Построение вымышленного мира — поисковая область
Эксперимент в поисковой области использует вымышленный, но внутренне согласованный поисковый мир для обучения, а затем оценивает обобщение на реальных поисковых задачах.
Конфигурация | WideSearch F1 по элементам | WideSearch F1 по строкам |
Базовая SFT, 35B | 34.02 | 13.72 |
+ Sim RL, вымышленный мир | 50.31 | 24.21 |
Улучшение | +16.29 | +10.49 |
Паттерн 4: Базовая модель агента — перенос разогрева LWM RL
В статье также описывается прогрев LWM RL как способ улучшить производительность последующих агентов без дополнительной тонкой настройки RL для этих конкретных задач.
Метрика | Terminal-Bench 2.0 | SWE-Bench Verified | SWE-Bench Pro | WideSearch F1 | Claw-Eval | BFCL v4 |
Базовая SFT | 33.25 | 64.47 | 42.18 | 33.38 | 53.60 | 62.29 |
+ прогрев LWM RL | 39.55 | 67.86 | 47.42 | 46.17 | 64.88 | 71.25 |
Улучшение | +6.30 | +3.39 | +5.24 | +12.79 | +11.28 | +8.96 |
Главное: Данные для прогрева получены из одношаговых, неагентных траекторий, однако улучшение переносится на более сложные многошаговые агентные задачи с вызовом инструментов. Это указывает на то, что знания о моделировании мира могут переноситься за пределы исходного формата обучения.
8. Краткое руководство по развертыванию
Метод 1: развертывание с помощью SGLang
SGLang рекомендуется в оригинальной статье для быстрого обслуживания.
pip install sglangpython -m sglang.launch_server \
--model-path Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tp-size 4 \
--context-length 262144 \
--reasoning-parser qwen3После запуска OpenAI-совместимая конечная точка API:
http://localhost:8000/v1Метод 2: развертывание с помощью vLLM
pip install vllmvllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--trust-remote-codeПримечание из официальной документации: Текущая карточка модели на Hugging Face также рекомендует использовать
--language-model-onlyс vLLM, поскольку архитектура модели включает определения визуальных компонентов, тогда как контрольная точка содержит веса языковой модели. Если инициализация vLLM завершается ошибкой, попробуйте добавить этот флаг.
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--language-model-only \
--trust-remote-codeМетод 3: локальный инференс с помощью Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
messages = [
{
"role": "system",
"content": "Вы — языковая мировая модель, симулирующая среду терминала Linux. "
"По команде пользователя предскажите вывод терминала."
},
{
"role": "user",
"content": "Действие: execute_bash\nКоманда: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True)
print(response)Метод 4: Вызов через API, совместимый с OpenAI
Этот метод работает после развертывания модели через SGLang или vLLM.
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
messages = [
{
"role": "system",
"content": "Вы — языковая мировая модель, симулирующая среду терминала Linux."
},
{
"role": "user",
"content": "Действие: execute_bash\nКоманда: pwd"
}
]
response = client.chat.completions.create(
model="Qwen/Qwen-AgentWorld-35B-A3B",
messages=messages,
max_tokens=32768,
temperature=0.6,
)
print(response.choices[0].message.content)Рекомендации
Рекомендуемые параметры сэмплирования:
temperature=0.6,top_p=0.95,top_k=20
Рекомендуемая длина вывода: около 32,768 токенов для большинства длинных наблюдений
Используйте доменно-специфичные системные промпты из каталога
prompts/репозитория для более высокого качества симуляцииПо возможности поддерживайте длину контекста не менее
128K; контекст модели по умолчанию составляет256K
9. Рабочий процесс оценки AgentWorldBench
Если вы хотите протестировать собственную мировую модель на AgentWorldBench, в оригинальной статье предлагается трехэтапный рабочий процесс.
# 1. Клонируйте репозиторий оценки
git clone https://github.com/QwenLM/Qwen-AgentWorld.git
cd Qwen-AgentWorld
# 2. Загрузите набор данных для оценки
huggingface-cli download Qwen/AgentWorldBench --repo-type dataset --local-dir ./AgentWorldBench
# 3. Установите зависимости
pip install openai
cd eval
# Шаг 1: инференс мировой модели
python eval.py infer \
--data-dir ../AgentWorldBench \
--model-base-url http://localhost:8000/v1 \
--model-name Qwen/Qwen-AgentWorld-35B-A3B \
--output-dir ./results
# Шаг 2: оценивание судьей LLM. Для этого требуется ключ API OpenAI.
export OPENAI_API_KEY="your-api-key"
python eval.py judge \
--predictions ./results/predictions.jsonl \
--judge-base-url https://api.openai.com/v1 \
--judge-model gpt-5.2-2025-12-11 \
--output-dir ./results
# Шаг 3: агрегирование оценок
python eval.py score --predictions ./results/judged.jsonlКаждый тестовый пример включает эталонные данные наблюдений, полученные при выполнении в реальной среде. Бенчмарк оценивает способность к моделированию мира по формату, фактической точности, согласованности, реалистичности и качеству.
10. Рекомендации по дообучению
Если вы хотите адаптировать Qwen-AgentWorld для конкретной области, в оригинальной статье рекомендуются три распространённых фреймворка для дообучения.
Фреймворк | Сильная сторона | Подходящий сценарий |
Высокая интеграция с ModelScope | Быстрые эксперименты и рабочие процессы экосистемы Alibaba | |
Активное сообщество и широкая поддержка стратегий обучения | Практическое инженерное развертывание | |
Сильная оптимизация памяти | Дообучение в условиях ограниченных ресурсов |
11. Примечания к источнику и обработка изображений
Оригинальная статья включает несколько изображений, связанных с доменами Qwen-AgentWorld и результатами бенчмарков. Они были сохранены в соответствующих разделах.
Иконки платформы CSDN, рекламные модули, блоки подписки на автора, QR-коды, кнопки вознаграждения и несвязанные рекомендательные изображения были удалены в соответствии с требованиями к публикации.
FAQ
Что такое Qwen-AgentWorld?
Qwen-AgentWorld — это языковая модель мира от команды Qwen. Она предсказывает следующее состояние среды после того, как агент выполняет действие, что делает её полезной для симуляции, обучения и оценки агентов.
Qwen-AgentWorld — это то же самое, что обычная чат-модель?
Нет. Обычная чат-модель в основном оптимизирована для ведения диалога и следования инструкциям. Qwen-AgentWorld обучена как симулятор среды, поэтому её основной сценарий использования — предсказание наблюдений в средах взаимодействия агентов.
Какая модель Qwen-AgentWorld доступна публично?
На официальных страницах Qwen-AgentWorld-35B-A3B указана как публично выпущенные веса модели. AgentWorldBench также доступен как оценочный бенчмарк. Более крупная модель 397B фигурирует в таблицах бенчмарков, но публичный релиз модели в основном указывает на версию 35B-A3B.
Можно ли развернуть Qwen-AgentWorld с помощью vLLM?
Да. Карточка модели Hugging Face включает пример развертывания с vLLM. Если вы столкнетесь с проблемами инициализации, официальная карточка модели рекомендует добавить --language-model-only, поскольку контрольная точка содержит веса языковой модели.
Можно ли развернуть Qwen-AgentWorld с помощью SGLang?
Да. SGLang является одним из рекомендуемых вариантов обслуживания и может предоставлять API-эндпоинт, совместимый с OpenAI. После этого модель можно вызывать через локальные API-запросы.
Почему Qwen-AgentWorld требуется длинное контекстное окно?
Симуляция агентной среды часто зависит от длинной истории взаимодействий. Более короткое контекстное окно может потерять важную информацию о состоянии, поэтому официальные рекомендации советуют по возможности сохранять не менее 128 тыс. токенов.
Для чего используется AgentWorldBench?
AgentWorldBench — это бенчмарк, выпущенный вместе с Qwen-AgentWorld. Он оценивает языковые модели мира в семи областях по таким параметрам, как формат, фактическая точность, согласованность, реалистичность и качество.
Подходит ли Qwen-AgentWorld для использования в продакшене?
Он может быть полезен для исследований, оценки, симуляции и внутренних экспериментов. Для продакшн-систем всё равно необходимо оценить задержку, стоимость оборудования, безопасность, надежность промптов и то, насколько точно смоделированные результаты соответствуют вашей реальной среде.
Связанные инструменты
Qwen-AgentWorld GitHub: Официальный репозиторий кода, промптов и рабочего процесса оценки Qwen-AgentWorld.
Qwen-AgentWorld-35B-A3B на Hugging Face: Официальная страница модели для общедоступных весов 35B-A3B.
AgentWorldBench: Официальный бенчмарк-набор данных для оценки языковых моделей мира.
SGLang: Быстрый фреймворк для обслуживания больших языковых моделей.
vLLM: Высокопроизводительный инференс-движок для обслуживания LLM.
Transformers: Библиотека Hugging Face для локальной загрузки моделей и инференса.
OpenAI Python SDK: Python-клиент, который может обращаться к OpenAI-совместимым локальным серверам моделей.
ms-swift: фреймворк ModelScope для обучения и тонкой настройки рабочих процессов LLM.
Связанные ссылки
Технический отчет Qwen-AgentWorld: официальная статья на arXiv, представляющая модель, бенчмарк и конфигурацию обучения.
Официальный блог Qwen-AgentWorld: официальный пост Qwen о выпуске проекта.
GitHub-репозиторий Qwen-AgentWorld: основной источник промптов, скриптов оценки и документации проекта.
Карточка модели Qwen-AgentWorld-35B-A3B: официальная страница Hugging Face с примерами развертывания и инференса.
Набор данных AgentWorldBench: официальный бенчмарк-набор данных, используемый для оценки модели.
Документация SGLang: документация по обслуживанию LLM с помощью SGLang.
Документация vLLM: документация по высокопроизводительному инференсу LLM и обслуживанию, совместимому с OpenAI.
LLaMA-Factory: Популярный фреймворк с открытым исходным кодом для экспериментов с тонкой настройкой и развертыванием LLM.


