
簡短回答:不是,但方向很重要
DiffusionGemma 並不是 Google 宣告 下一個權杖預測 的終結。更適合將它理解為一個嚴肅的 實驗性 訊號:Google 正在測試一條不同的 AI 文字生成 路徑,在這條路徑中,速度、平行處理,以及互動式 本機工作流程,比標準 LLM 熟悉的一次一個權杖節奏更重要。
Google 將 DiffusionGemma 描述為一個以 文字擴散 為核心打造的 實驗性 開放模型。它不是嚴格由左至右產生文字,而是透過精煉一個充滿雜訊或預留位置權杖的畫布來生成文字區塊。實際上的承諾很簡單:如果模型能一次處理多個位置,就能更有效率地使用 GPU 運算,並在某些使用情境下降低 推論延遲。
但這並不表示 自迴歸 語言模型明天就會被取代。Google 自家的發表文章對取捨說得很謹慎。文中表示,對於需要最高 生產品質 的應用,標準 Gemma 4 模型仍然是建議選擇。這一句話很重要。DiffusionGemma 是一個著重速度的研究與開發者模型,而不是主流 LLM 範式的通用替代品。
為什麼下一個權杖預測成為預設做法
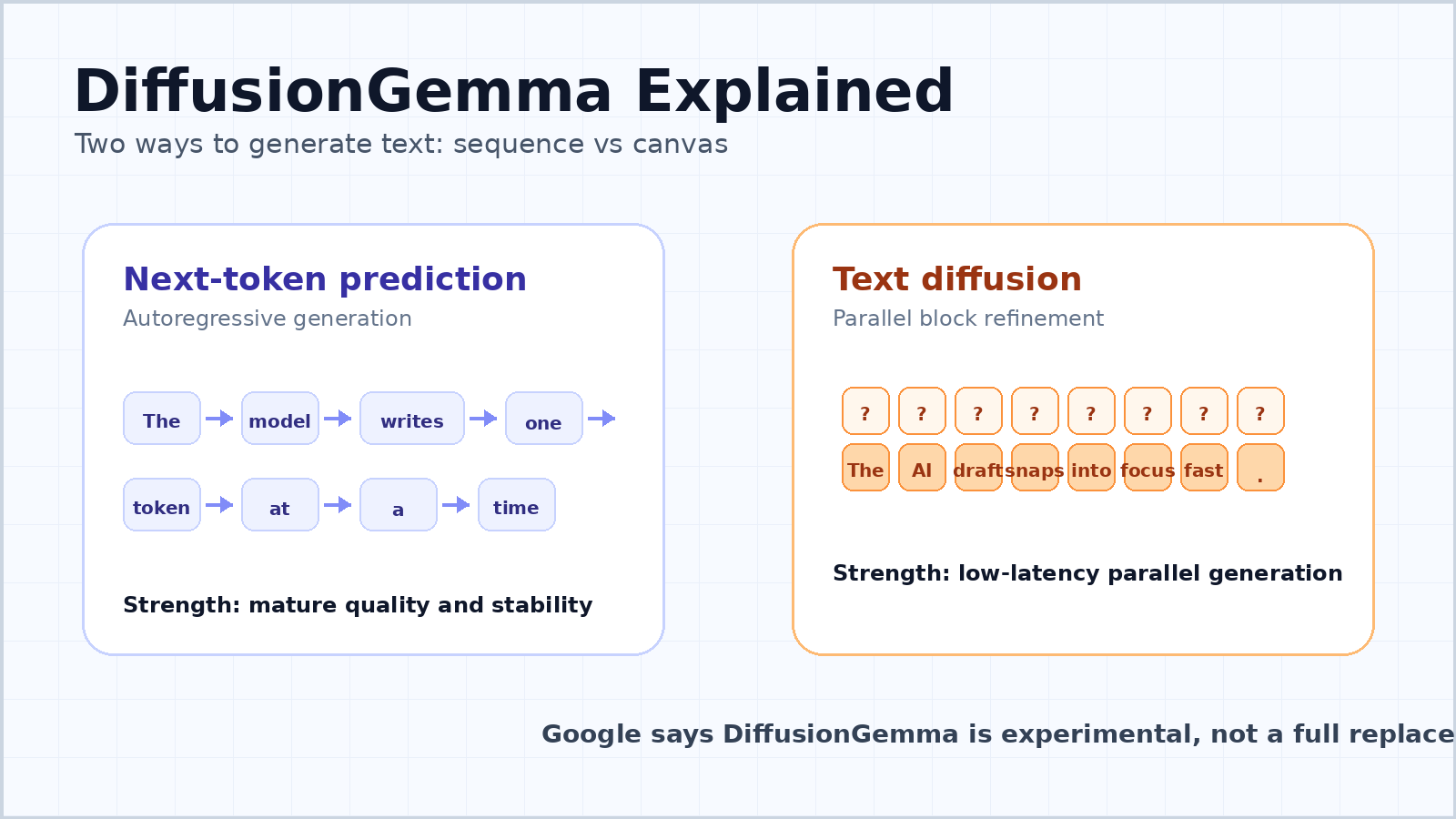
多數現代聊天機器人與大型語言模型都是 自迴歸 的。它們讀取提示,接著預測下一個權杖,再預測之後的下一個權杖,並持續下去直到答案完成。這就是 下一個權杖預測 背後簡單的心智模型。
它之所以成為主流並非偶然。自迴歸 模型具備彈性、穩定,且容易擴展。它們可以生成可變長度的文字、維持由左至右的一致性,並且在聊天、程式碼撰寫、翻譯、摘要、推理與工具使用等場景中表現良好。這種方法也自然符合書面語言展開的方式。
弱點在於延遲。逐權杖 模型具有序列相依性:第 100 個權杖依賴第 1 到第 99 個權杖,而第 101 個權杖又依賴第 100 個權杖。即使 GPU 很強大,模型仍必須逐步走完整個序列。對於一名使用者提出一個問題的情境,許多硬體資源可能仍未被充分利用,因為模型正在等待記憶體搬移與序列式解碼。
DiffusionGemma 有什麼不同
DiffusionGemma 從 擴散模型 取得靈感,這類生成式模型家族因影像與影片生成而聞名。擴散模型 不是一次繪出一個權杖作為答案,而是從雜訊或不確定性開始,並逐步將其精煉成連貫的輸出。
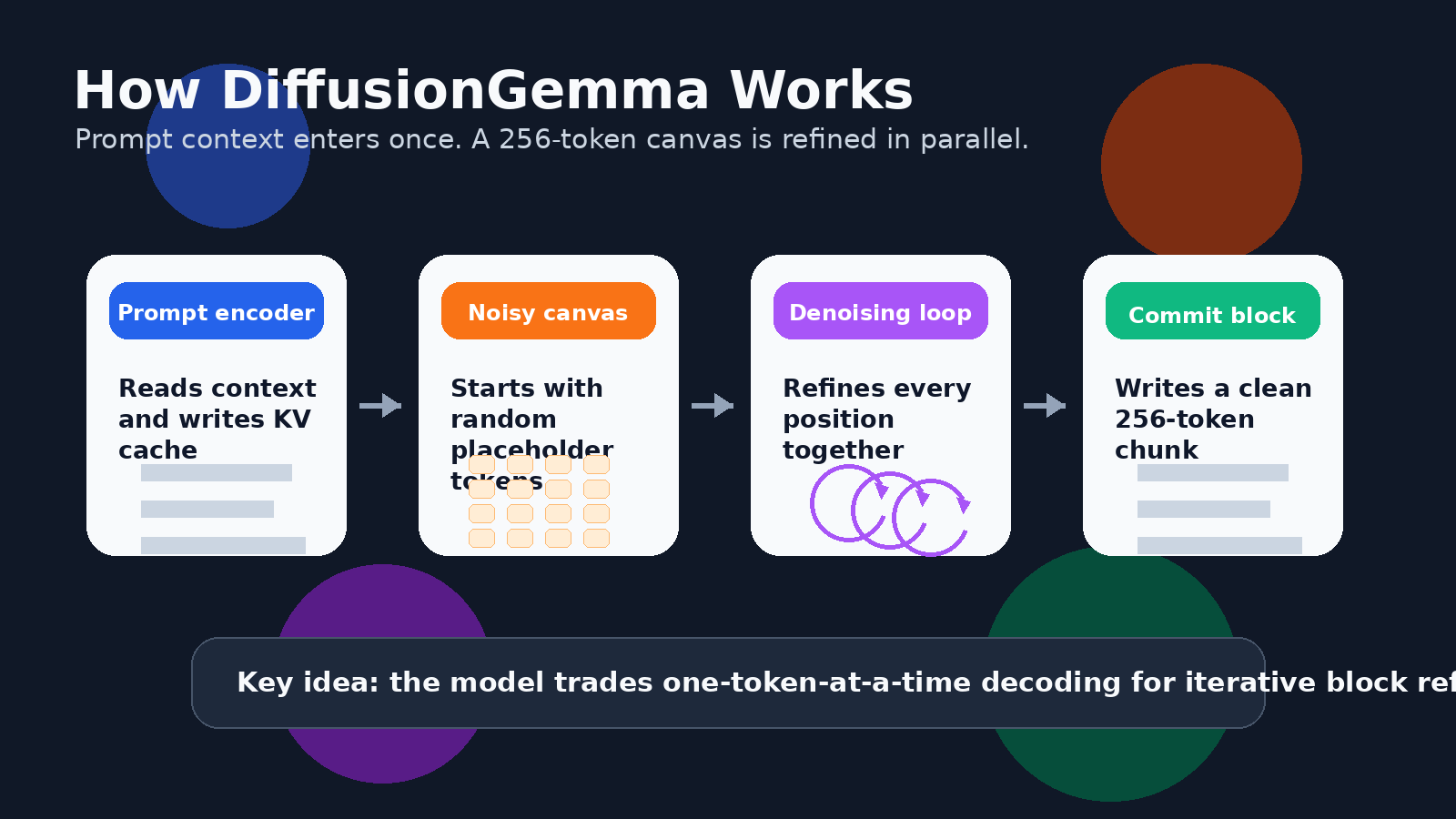
對文字來說,這表示模型可以平行處理一個權杖區塊。Google 的開發者指南描述了一個 256 權杖畫布。模型從一個充滿隨機預留位置權杖的畫布開始,接著反覆對整個區塊去雜訊。信心較高的權杖位置會成為錨點,不確定的位置則再次被精煉,而整個區塊會逐漸變得清晰。
這不等於一次生成一整篇長文。DiffusionGemma 對較長輸出採用 區塊自迴歸 方法。一旦一個 256 權杖區塊被完全精煉,就會被提交到 KV 快取,然後模型移到下一個區塊。因此,它在區塊之間仍有由左至右的結構,但在每個區塊內可以一起精煉許多權杖。
為什麼它可能更快
速度的關鍵在於硬體瓶頸。傳統 自迴歸 模型可能受限於記憶體頻寬,因為模型在一次生成一個權杖時會反覆載入權重。DiffusionGemma 試圖透過在每個區塊內提供 GPU 更大的平行工作負載,將更多工作轉向運算端。
Google 表示,DiffusionGemma 在專用 GPU 上可提供最高四倍更快的權杖生成速度,範例包括在單張 NVIDIA H100 上每秒超過 1000 個權杖,以及在 RTX 5090 上每秒超過 700 個權杖。這些數字並不是對每項任務、裝置或批次大小的一體適用承諾。它們代表的是一種特定、對硬體友善的生成模式。
這就是為什麼 DiffusionGemma 對本機與互動式工作流程特別有趣。如果使用者需要快速編輯、程式碼補全、結構化草稿或快速迭代,GPU 可能還有多餘的運算資源,而自回歸模型無法充分利用。擴散語言模型可能更適合這類低批次、重視速度的工作負載。
雙向注意力與自我修正的角色
最重要的差異之一是雙向注意力。在去噪過程中,畫布上的 token 可以關注區塊中的其他位置,而不只是先前的 token。這會改變生成的感受。模型可以利用缺失或不確定片段兩側的脈絡。
這對非線性的文字問題特別有用。Google 指出,行內編輯、程式碼補全、數學圖形,甚至數獨風格的受限生成,都是未來位置很重要的例子。標準自回歸模型在許多任務上可能很強,但一旦它輸出早期 token,通常就會被它綁住。擴散式去噪會在區塊定稿前創造修訂空間。
這也是為什麼自我修正這個詞一直出現在 DiffusionGemma 周圍。模型不只是單純打字。它會反覆評估整個畫布,保留有信心的位置、替換不確定的位置,並持續細化區塊直到收斂。
26B MoE 設計代表什麼
DiffusionGemma 基於 Gemma 4 家族的 26B 專家混合設計,在推論期間只使用較小的活躍子集。Google 的 AI 文件將其描述為一個約有 4B 活躍參數的 26B 模型,而開發者指南則說明,該模型在量化後設計上可符合 18GB VRAM 的限制。
核心概念是效率。稀疏 MoE 模型可以擁有龐大的總參數量,同時只為特定 token 或任務啟用選定的專家。這可以在不要求完整模型每一步都處於活躍狀態的情況下提升能力。
對開發者而言,這點很重要,因為 DiffusionGemma 不只是實驗室展示。它以 Apache 2.0 授權釋出為開放權重模型,並提供 vLLM、Hugging Face、Google Cloud Model Garden 以及其他部署路徑的文件。Google 顯然是在邀請生態系測試以擴散為基礎的生成是否能在真實應用中變得實用。
DiffusionGemma 適合哪些情境

最適合的使用案例不一定是長篇高品質寫作,而是速度關鍵的任務,使用者能從快速迭代中受益。行內編輯就是一個例子。與其等待模型逐個 token 重寫段落,擴散模型可以快速細化整個片段。
程式碼補全是另一個很有潛力的候選情境。開發者可能需要模型填補函式中間的內容,或在理解前後文的情況下調整一段程式碼。雙向注意力在這裡很有用,因為模型可以同時推理缺失區段兩側的內容。
結構化與受限生成也很有趣。如果輸出有多重相依性,例如表格、謎題、範本或正式結構描述,區塊細化可以給模型更多空間在各位置之間協調。這就是為什麼 DiffusionGemma 不只是關於變得更快。它也指向一種不同的生成互動方式。
自回歸模型仍然勝出的地方
取捨在於品質。Google 明確表示 DiffusionGemma 優先考量速度與平行版面生成,而其整體輸出品質低於標準 Gemma 4。這是它不應被描述為直接取代下一個 token 預測的核心原因。
自回歸模型仍然有重大優勢。它們已針對正式環境深度最佳化,在許多通用任務上表現強大,並由成熟的服務堆疊支援。它們也自然適用於模型以穩定序列延展文字的對話流程。
實際的未來很可能不是一種解碼方法取代另一種。更可能的是,AI 系統會將不同任務路由到不同的生成策略。自回歸模型可能仍是高品質通用聊天與推理的預設選項,而擴散語言模型則可能驅動快速編輯、本機生成、程式碼補全,以及其他互動式工作負載。
開發者接下來應該關注什麼
最大的問題在於 diffusion language model 是否能在保有延遲優勢的同時縮小品質差距。如果輸出需要太多修正,光有速度並不足夠。但如果品質提升,這種架構可能會對本地 AI、IDE 助手、文件編輯與即時介面變得非常重要。
第二個問題是服務基礎架構。支援 vLLM 很重要,因為 diffusion language model 需要不同的解碼行為:bidirectional attention、反覆去噪、自訂取樣,以及區塊層級的提交邏輯。如果推論框架能讓這些變得容易,更多開發者就會進行實驗。
第三個問題是產品設計。擴散文字模型不只是更快的聊天機器人。它的自然介面可能更像是一個智慧編輯器,會修改畫布、填補空缺,並就地改善草稿。這可能會改變使用者體驗 AI 寫作與程式設計工具的方式。
最終重點
DiffusionGemma 並不表示 Google 現在要取代 next-token prediction。它表示 Google 正在讓 text diffusion 變得足夠實用,讓開發者能在真實工作流程中測試。
重要的轉變不只是更快的文字生成,而是語言生成不一定總要像模型從左到右打字一樣。有時候,更好的互動方式是一個能並行精修的畫布。
如果這種模式持續改善,AI text generation 可能會變得更快、更具互動性,也更適合本地裝置。但就目前而言,DiffusionGemma 應被理解為一個實驗性開放模型,並傳達非常明確的訊息:語言生成的未來可能不只包含一種解碼路徑。
快速比較
問題 | 自回歸 LLM | DiffusionGemma |
生成模式 | 依序預測下一個權杖 | 並行精修權杖畫布 |
優勢 | 高品質的正式環境輸出 | 低延遲互動式生成 |
脈絡流動 | 解碼期間主要由左至右 | 在每個去噪畫布內為雙向 |
最適合 | 一般聊天、推理、成熟的服務部署 | 編輯、程式碼補全、快速本地工作流程 |
狀態 | 主流正式環境典範 | 實驗性開放模型 |
行動呼籲
如果你正在打造 AI 產品,不要把 DiffusionGemma 視為單純的替代模型。應該把它當成一種新的生成模式,在推論延遲、本地回應速度與非線性編輯最重要的情境中進行測試。
對於打造開發者工具、寫作助手、程式設計工作流程或裝置端 AI 體驗的團隊來說,這是一種值得及早進行基準測試的架構。
常見問題
DiffusionGemma 是什麼?
DiffusionGemma 是 Google 的實驗性開放文字生成模型,使用離散擴散來並行精修權杖區塊,而不是只依賴逐一權杖生成。
Google 要取代下一個權杖預測嗎?
不是。Google 仍建議使用標準 Gemma 4 以獲得最高的正式環境品質。DiffusionGemma 是實驗性模型,並針對速度關鍵的工作流程最佳化。
為什麼 DiffusionGemma 比較快?
它會在 256 個權杖的畫布上並行運作,將更多工作轉向 GPU 運算,而不是嚴格一次只生成一個權杖。
什麼是 256-token 畫布?
它是由一組 token 位置構成的區塊,模型會先初始化、去噪、精煉,然後在移至下一個區塊前提交。
誰應該測試 DiffusionGemma?
從事本機推論、行內編輯、程式碼補全、快速草擬,以及其他低延遲互動式 AI 工具的開發人員都應該關注。
相關工具
- Gemma 文件
- vLLM
- Colab
- Kaggle
來源
- 開發人員指南
- Gemma 文件
- DeepMind
- HF 模型
- vLLM 部落格
- NTP 調查


