
Introduction
Anthropic venait tout juste de remettre Claude Fable 5 en service lorsqu’un nouveau rapport public de jailbreak est apparu.
Le moment rendait l’affaire particulièrement sensible. Fable 5 avait déjà traversé une première controverse, une suspension temporaire d’accès, puis un redéploiement avec des protections de cybersécurité renforcées. Peu après son retour, le chercheur en sécurité Vitto Rivabella a déclaré être parvenu à franchir de nouveau ses défenses.
Ce qui est intéressant, c’est que ce second cas ne se résume pas à une simple histoire du type « le modèle est cassé ». C’est plus compliqué que cela. La tentative aurait pris environ 20 heures, la plupart des essais ont échoué, et le résultat final était suffisamment limité pour que le chercheur lui-même décrive la recherche web ordinaire comme plus rapide et moins coûteuse pour obtenir le même type d’information.
Cet article suit la chronologie originale : le retour de Fable 5, le premier jailbreak, le programme public de divulgation Cyber Jailbreak d’Anthropic, le second examen de jailbreak, et la question plus profonde qui se cache derrière tout cela — à savoir si un modèle d’IA de pointe pourra un jour être parfaitement verrouillé.
Note sur la source
Cet article réécrit est basé sur l’article chinois original de 智源社区 / 新智元 : https://hub.baai.ac.cn/view/56072. L’article original cite des publications publiques sur X ainsi que des annonces officielles d’Anthropic concernant Fable 5, son redéploiement et son cadre de jailbreak.
La page originale contient plusieurs images. Cette version conserve les captures d’écran directement pertinentes pour les affirmations de l’article, comme des publications publiques, des captures d’écran de programmes officiels et des graphiques de robustesse. Les visuels décoratifs de marque, les images promotionnelles et les captures d’écran semblant contenir des vignettes de sorties dangereuses trop détaillées ont été omis.
La source originale inclut également cette note sur les droits d’auteur : si certaines images du contenu posent des problèmes de droits, l’éditeur demande aux ayants droit de le contacter afin qu’elles soient retirées.
Fable 5 est revenu — mais sous conditions
Anthropic a confirmé que Fable 5 quitterait temporairement les offres d’abonnement après le 7 juillet, mais l’entreprise a également indiqué qu’elle prévoyait de rétablir Fable comme fonctionnalité standard d’abonnement dès que la capacité le permettrait.
Pour de nombreux utilisateurs, cela ressemblait à une bonne nouvelle. Fable 5 n’était pas définitivement supprimé. Il revenait, simplement avec des limites d’usage et des contraintes de capacité.

Mais le soulagement n’a pas duré longtemps.
Peu après son redéploiement, Fable 5 aurait de nouveau été jailbreaké. C’était la deuxième fois que ses défenses étaient publiquement mises à l’épreuve. Vitto Rivabella a annoncé qu’il était parvenu à les contourner, même si la conclusion finale était plus nuancée que ce que le titre laissait entendre.
Anthropic avait déjà expliqué pourquoi Fable 5 avait été restreint auparavant. Selon l’entreprise, le problème précédent concernait un rapport dans lequel des chercheurs d’Amazon avaient découvert une méthode permettant de contourner les protections de Fable 5 dans un contexte de cybersécurité.

En raison de cet incident antérieur, Anthropic a déclaré que le Fable 5 redéployé incluait un classificateur de sécurité renforcé, conçu pour cibler le comportement précédemment signalé.
Pourtant, le « mythe » n’a tenu que peu de temps.
72 heures : la première fissure dans le mythe de Fable 5
L’image publique initiale de Fable 5 reposait sur des tests de sécurité extrêmes.
Lorsqu’Anthropic a lancé le modèle le 9 juin, l’entreprise a souligné qu’il avait fait l’objet de tests de résistance externes intensifs. Le message était clair : il s’agissait d’une version à usage général hautement protégée d’une famille de modèles beaucoup plus performante.
Puis est arrivé le premier jailbreak public.
La figure bien connue du jailbreak Pliny the Liberator aurait passé seulement quelques jours avant de démontrer que Fable 5 pouvait être poussé au-delà des limites de sécurité prévues. L’article original décrit des exemples impliquant de la chimie interdite et du contenu lié à l’exploitation de logiciels, mais cette version réécrite évite volontairement de reproduire tout détail opérationnel.
Le point important n’est pas le contenu précis. Le point important est le schéma d’attaque.
Comment le premier jailbreak a fonctionné
Le premier cas reposait sur deux grandes idées discutées depuis des années dans les cercles de red teaming en IA :
- Confusion par les caractères et la langue
Certaines invites utilisaient des caractères ressemblants, des formes Unicode inhabituelles ou des motifs textuels non standard. Pour une personne, le sens peut rester évident. Pour un classificateur, l’entrée peut être plus difficile à interpréter de manière fiable. - Dilution de l’intention par un contexte long
Au lieu de placer directement la requête nuisible devant le modèle, l’intention peut être répartie sur une longue conversation apparemment inoffensive. Le classificateur doit alors suivre le sens sur de nombreux tours plutôt qu’évaluer une seule phrase simple.
Ces idées ne sont pas nouvelles. Ce qui l’est davantage, c’est qu’elles auraient encore fonctionné contre un modèle présenté comme spécialement durci.
ce qui a rendu l’affaire Fable 5 remarquable, c’est qu’Anthropic avait présenté le modèle comme exceptionnellement renforcé.
Anthropic a ouvert un programme public de jailbreak cyber
Le 1er juillet, Anthropic a annoncé le retour de Fable
5. À peu près au même moment, l’entreprise a également ouvert un programme public sur HackerOne appelé Cyber Jailbreak.
Le programme invite les chercheurs et le grand public à signaler les jailbreaks susceptibles de permettre à Fable 5 d’aider à des cas d’utilisation cyber malveillants.
Il s’agit d’un programme de divulgation de vulnérabilités, et non d’un programme de primes rémunéré. Autrement dit, les chercheurs peuvent soumettre leurs découvertes, mais le programme n’offre pas de récompenses financières.
Cette conception est intéressante. Anthropic peut bénéficier en continu de tests adversariaux externes menés par des chercheurs compétents, tandis que la principale récompense pour les personnes qui soumettent des rapports est la reconnaissance et la divulgation responsable.
Certains observateurs y ont vu une stratégie de red team intelligente et peu coûteuse. D’autres ont souligné une faiblesse : les personnes qui découvrent des jailbreaks très médiatisés ne veulent souvent pas les envoyer discrètement dans une boîte de réception privée.
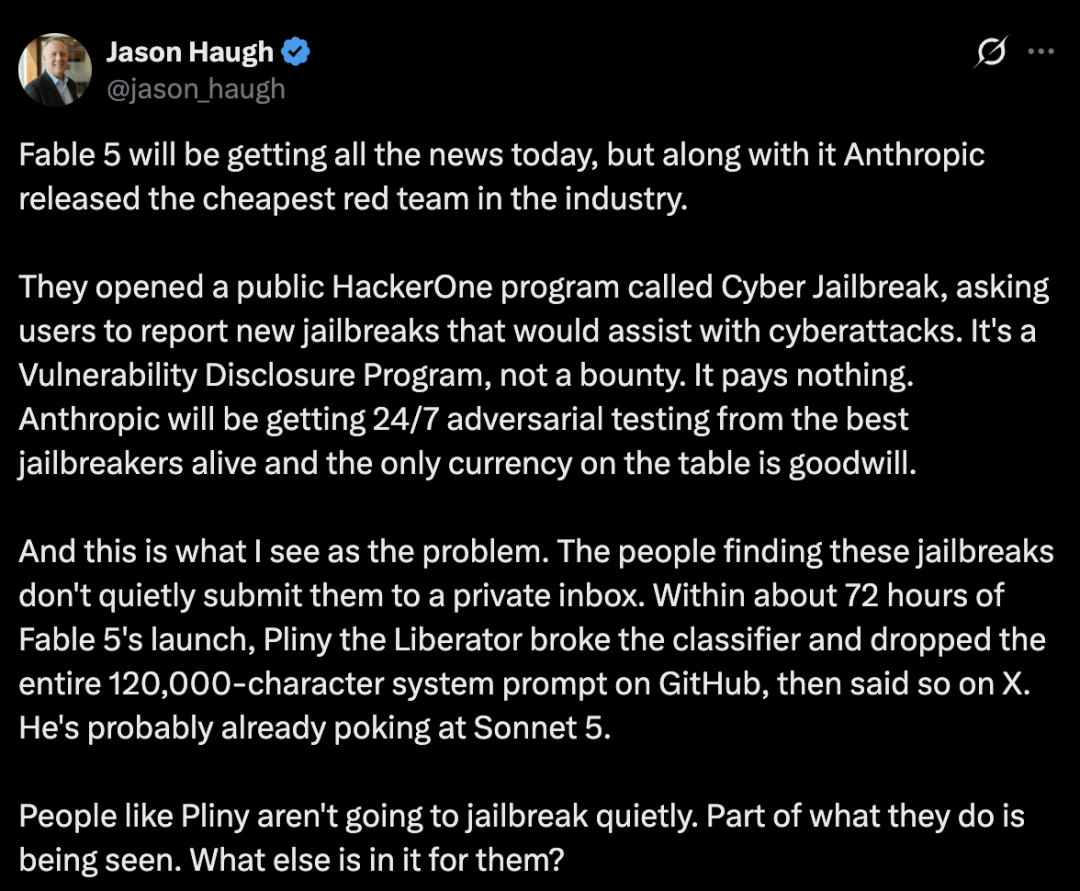
Pour les chercheurs en jailbreak disposant d’une image publique, la visibilité fait partie de l’événement. Lorsqu’un jailbreak est découvert, publier le résultat peut devenir une partie de l’objectif.
Fable 5 a de nouveau été jailbreaké
Fable 5 aurait de nouveau été contourné. Mais l’examen du second jailbreak avait un ton très différent du premier.
Le chercheur à l’origine de celui-ci était Vitto Rivabella. Après environ 20 heures de tests, sa conclusion n’était pas que Fable 5 était faible. Au contraire, il a accordé du crédit à Anthropic.

Selon son évaluation, la plupart des tentatives ont échoué. Il a décrit Fable 5 comme extrêmement bien protégé et a déclaré que le modèle semblait utiliser des défenses en couches plutôt qu’un simple filtre unique.
Un autre type de post-mortem
L’histoire du second jailbreak est moins spectaculaire qu’elle n’en a l’air au premier abord.
La publication de Vitto suggérait que les défenses de Fable 5 fonctionnaient réellement. Selon lui, le modèle semblait disposer d’au moins trois couches de protection :
- Des contrôles de sécurité côté entrée avant que le modèle ne s’engage pleinement dans la requête.
- Des mécanismes d’interruption pendant la génération, capables d’arrêter un comportement dangereux pendant la formation de la réponse.
- Un raisonnement de sécurité internalisé, dans lequel le modèle semble reconnaître une intention dangereuse dans le cadre de son propre processus de raisonnement.
Il a également déclaré que le système ne se contentait pas de bloquer des mots-clés. Il semblait détecter l’intention et la sémantique dans plusieurs langues.
C’est important, car les filtres par mots-clés sont relativement faciles à tromper. Les défenses fondées sur l’intention sont plus difficiles à contourner, surtout lorsqu’elles sont combinées à plusieurs points de contrôle.
Pourquoi le chiffre de 90 % de blocage compte
L’article original note que Fable 5 semblait bloquer environ 90 % des requêtes testées. Le chiffre exact provient des observations du chercheur, et non d’un benchmark formel, mais il correspond à la tendance générale des tests indépendants.
Le laboratoire de sécurité IA de l’Institut italien pour l’intelligence artificielle a également étudié Fable 5 et Opus 4.8. Dans son rapport, l’attaque adaptative la plus forte a atteint un taux de réussite confirmé de 6,1 % contre Fable 5 et de 11,5 % contre Opus 4.8.

Cela ne signifie pas que le modèle est invulnérable. Cela signifie que la faiblesse restante est plus difficile à atteindre.
Les astuces statiques deviennent moins efficaces. La surface d’attaque restante semble favoriser les tentatives adaptatives et itératives — celles où une personne ou un système automatisé de red team continue d’essayer, d’ajuster et de sonder jusqu’à ce qu’une ouverture étroite apparaisse.
La combinaison qui a fini par fonctionner
La tentative réussie de Vitto ne reposait pas sur une seule formule astucieuse.
L’article original la décrit comme une combinaison complexe d’anciennes idées de red team : obfuscation de texte, cadrage académique, longue montée en puissance, décomposition et recombinaison des tâches, ainsi qu’une part d’aléatoire.
Aucun de ces concepts n’est nouveau. La difficulté ne consiste pas à savoir qu’ils existent.
les catégories existent. La partie difficile consiste à les tester à répétition contre un système qui réagit en temps réel et réinitialise l’interaction lorsqu’il détecte une intention suspecte.
Autrement dit, il ne s’agissait pas d’un jailbreak propre en une seule tentative. Cela ressemblait davantage à un long et épuisant processus d’essais et d’erreurs.
Les langues à faibles ressources restent un point faible
Une partie de l’analyse peut facilement être mal comprise.
Vitto aurait noté que les langues obscures ou disposant de moins de ressources restaient un point faible plus constant. L’article original mentionne des langues comme le santali et l’amharique à titre d’exemples.
![L’image montre du contenu textuel généré par Claude Fable 5 après un jailbreak. En haut figure la mention « HUMAN RESPONSE
- APPROXIMATE HUMAN-TYPED [HISTORICAL RECONSTRUCTION
- FOR EDUCATIONAL PURPOSES ONLY] ». Le texte en dessous traite de discussions liées au « DISORDERS ENQUIRY COMMITTEE » entre 1919 et 1928, notamment de langues comme le « SANTALI » et l’« AMHARIC », et énumère six questions de « NIMR
- 1 » à « NIMR
- 6 », portant sur des événements historiques, des personnages, etc. Cette image est liée à la description, dans le document, du texte généré par Claude Fable 5 après son jailbreak, et montre le contenu généré de manière concrète.](https://we0-cms.oss-cn-beijing.aliyuncs.com/cms-assets/image/2026/07/0252dc52-aa7a-4498-849e-4355e3eebc38-08-5fa346f7-c790-4f3d-8f1a-1869bc22d5f0.png)
Il ne faut pas comprendre cela comme signifiant que « Fable 5 possède une porte dérobée spéciale ». Il s’agit d’un problème plus large qui touche les grands modèles de langage.
Les données d’entraînement à la sécurité sont généralement les plus solides en anglais et dans d’autres langues à fortes ressources. Les langues à faibles ressources bénéficient souvent d’une couverture moindre, de moins d’exemples de sécurité et d’évaluations plus faibles. Cela crée des garde-fous inégaux selon les langues.
Les chercheurs alertent sur ce problème depuis un certain temps. La robustesse multilingue face aux jailbreaks n’est pas seulement un problème propre à Claude ; c’est un problème plus vaste de sécurité de l’IA.
Qu’a réellement produit le jailbreak ?
Après tous ces efforts, le résultat n’a pas été une fuite spectaculaire de « secrets fondamentaux ».
L’article original décrit la sortie comme un mélange de fragments nuisibles de faible qualité ou limités : un peu de désinformation, du contenu nuisible épars, des propos offensants, des informations partielles liées à la chimie et du contenu léger lié aux vulnérabilités. Cette version évite d’en reproduire les détails.
Le point essentiel est que la sortie ne semblait pas stable, complète ni particulièrement utile pour des tâches nuisibles à long horizon.
C’est pourquoi le propre résumé de Vitto était important. Il a déclaré qu’avec le niveau actuel de protection, chercher sur le Web était bien plus rapide et moins coûteux que de passer environ 20 heures à essayer de pousser le modèle au-delà de ses garde-fous.

Il a également déclaré qu’il n’était pas parvenu à maintenir un jailbreak complet stable pour des tâches à long horizon sans déclencher le système de sécurité.
Cela concorde avec la présentation publique d’Anthropic. Dans son billet sur le redéploiement, Anthropic a décrit les jailbreaks connus jusqu’à présent comme mineurs : ils peuvent entrer dans la marge de sécurité, mais ils n’atteignent pas nécessairement les catégories plus graves que l’entreprise cherche le plus à bloquer.

Le paradoxe d’un scellement parfait
Deux jailbreaks. Deux leçons différentes.
Le premier a donné l’impression qu’Anthropic était trop confiante. Fable 5 avait été présenté comme ayant fait l’objet de tests poussés, mais il a été contourné publiquement peu après son lancement. L’article original décrit cela comme un cas où l’entreprise a tenté de contrôler le risque par une restriction extrême, avant d’être embarrassée par un jailbreak très visible.
Le second a révélé autre chose : non pas de l’arrogance, mais des angles morts.
Même avec des classificateurs plus puissants, des défenses en couches et des canaux publics de red teaming, le langage lui-même reste insaisissable. Le sens peut être caché, étiré, traduit, déguisé ou réparti dans le contexte. Les systèmes de sécurité peuvent s’améliorer, mais la surface d’attaque continue de se déplacer.
C’est la leçon dérangeante pour la sécurité de l’IA.
Les humains ont construit des modèles capables de traduire entre les langues et de raisonner sur d’immenses contextes. Mais nous ne pouvons toujours pas traduire pleinement chaque intention humaine cachée en une décision de sécurité nette.
Le confinement parfait de l’IA pourrait être un paradoxe. Plus le modèle devient capable, plus la frontière entre un comportement sûr et un comportement dangereux devient subtile.
FAQ
Qu’est-ce que Claude Fable 5 ?
Claude Fable 5 est un modèle Claude avancé d’Anthropic, positionné comme un modèle généraliste très performant doté de garde-fous plus solides que son équivalent moins restreint, Claude Mythos
5. Anthropic a décrit Fable 5 comme un modèle conçu pour rendre les capacités de niveau frontière plus largement disponibles tout en limitant les usages cybernétiques dangereux.
Que signifie un jailbreak d’IA ?
Un jailbreak d’IA est une méthode de prompting ou un schéma d’interaction qui tente de contourner les garde-fous de sécurité d’un modèle. Un jailbreak peut être mineur, étroit ou grave selon le comportement qu’il débloque et l’étendue de son efficacité.
Fable 5 a-t-il été complètement cassé par le second jailbreak ?
D’après l’analyse publique décrite dans l’article original, non. Le chercheur a déclaré que la plupart des tentatives avaient échoué, que le processus avait pris environ 20 heures et que les sorties finales étaient limitées. Cela suggère que le modèle
disposait encore de défenses significatives, même si elles n’étaient pas parfaites.
Pourquoi Anthropic a-t-elle lancé un programme Cyber Jailbreak sur HackerOne ?
Anthropic a lancé le programme Cyber Jailbreak afin d’offrir aux chercheurs un canal clair pour signaler les jailbreaks susceptibles de permettre des usages cybernétiques nuisibles. Il s’agit d’un programme de divulgation de vulnérabilités, et non d’un bug bounty rémunéré ; il met donc l’accent sur le signalement responsable plutôt que sur les récompenses financières.
Pourquoi les langues à faibles ressources sont-elles importantes pour la sécurité de l’IA ?
Les langues à faibles ressources disposent souvent de moins de données d’entraînement, de moins d’exemples liés à la sécurité et d’une couverture plus faible dans les benchmarks. Cela peut rendre les garde-fous moins cohérents d’une langue à l’autre, ce qui explique pourquoi les tests de sécurité multilingues sont devenus un axe de recherche important.
Un taux de réussite de jailbreak de 6,1 % signifie-t-il que Fable 5 est dangereux ?
Pas en soi. Un taux de réussite confirmé plus faible peut tout de même être important, car les modèles de pointe peuvent être déployés à très grande échelle, et des attaquants déterminés peuvent automatiser des tentatives répétées. En même temps, ce chiffre montre que Fable 5 a résisté à la plupart des attaques testées dans l’évaluation d’AI4I.
Un modèle d’IA peut-il être entièrement protégé contre les jailbreaks ?
Anthropic et de nombreux chercheurs estiment qu’une immunité parfaite est peu probable. L’objectif pratique n’est pas de prouver qu’aucun jailbreak ne pourra jamais exister, mais de réduire la gravité des incidents, de détecter tôt les comportements à risque et de corriger les faiblesses majeures avant qu’elles ne soient largement exploitées.
Outils associés
- Claude : la plateforme d’assistant IA d’Anthropic, où les modèles Claude sont mis à disposition des utilisateurs.
- Claude API : la plateforme développeur d’Anthropic permettant de créer des applications avec les modèles Claude.
- Anthropic : l’entreprise derrière Claude, Fable 5, Mythos 5 et les recherches associées sur la sécurité de l’IA.
- HackerOne : une plateforme de coordination des vulnérabilités utilisée par les organisations pour recevoir des rapports de sécurité de la part des chercheurs.
- AI4I : l’Institut italien pour l’intelligence artificielle, qui publie des recherches et des rapports sur les systèmes d’IA.
- CVSS : un cadre largement utilisé pour évaluer la gravité des vulnérabilités logicielles, pertinent dans la discussion plus large sur les cadres d’évaluation de la gravité des jailbreaks en IA.
Liens associés
- Article original sur 智源社区 : l’article source chinois sur lequel cette version Markdown est basée.
- Redéploiement de Fable 5 : le billet officiel d’Anthropic sur le redéploiement de Fable 5 et ses garde-fous mis à jour.
- Plus de détails sur les protections cyber de Fable 5 : l’explication d’Anthropic concernant les classificateurs de sécurité de Fable 5 et le cadre proposé pour évaluer la gravité des jailbreaks.
- Claude Fable 5 et Claude Mythos 5 : le billet de lancement d’Anthropic pour Fable 5 et Mythos 5.
- Programme Anthropic Cyber Jailbreak : la page de divulgation sur HackerOne permettant de signaler les jailbreaks liés au cyber.
- Rapport AI4I sur les jailbreaks et les modèles de pointe : le résumé par AI4I de son étude de red team sur Fable 5 et Opus 4.8.
- Une étude de red team des modèles Anthropic Fable 5 et Opus 4.8 : la page arXiv de l’étude de red team menée par AI4I.
- Jailbreak multilingue des LLM à l’aide de langues à faibles ressources : un article de recherche examinant comment les langues à faibles ressources peuvent affecter la robustesse face aux jailbreaks.
Résumé
Le second jailbreak de Fable 5 n’est pas une simple histoire d’échec total. Il montre que les défenses en couches d’Anthropic semblent bloquer la plupart des tentatives directes, mais que des équipes de red team déterminées peuvent encore trouver des failles étroites avec suffisamment de temps, d’itérations et de créativité.
Le problème plus profond est que la sécurité de l’IA ne consiste pas seulement à bloquer des mots-clés. Elle doit interpréter l’intention à travers les langues, les contextes longs, les tâches de cybersécurité ambiguës et les cadrages adversariaux. C’est beaucoup plus difficile que de construire un filtre statique.
Le cas de Fable 5 indique l’avenir de la sécurité des IA de pointe : des classificateurs plus robustes, des canaux de divulgation publics, une meilleure évaluation multilingue et des cadres partagés d’évaluation de la gravité.
La leçon est claire : les modèles de pointe peuvent devenir beaucoup plus difficiles à jailbreaker, mais une IA « parfaitement verrouillée » reste un problème non résolu.


