
引言
本周的 HyperAI 更新聚焦于音频、视频、图像理解、OCR 和语音识别模型的强大组合。头条项目是 Irodori-TTS-500M-v3,这是一个开放的日语文本转语音模型,结合了高保真 48 kHz 语音生成、零样本声音克隆,以及通过表情符号标注实现的细粒度风格控制。
本次更新还包括用于基于提示词的音频分离、视频抠图、4D 世界模拟、视频转音频生成、文档 OCR、端侧分割、表现力音频编辑和低延迟流式 ASR 的工具。以下是对原始每周汇总的整理版,可直接用于发布,并保留了有用截图的原始上下文。
来源说明
本文基于 BAAI Hub / HyperAI 发布于 的每周更新。原页面说明文章来源于微信,如有版权问题,图片可删除。
二维码、宣传海报、群邀请图片和无关推荐横幅已被有意移除。DiaMoE-TTS 和 DreamOmni2 的图片链接保留在其原始位置,但在检查过程中其预览请求超时,因此此处仅作说明,而不将其视为已完全验证的截图。
每周 HyperAI 更新概览
从 6 月 27 日到 7 月 3 日,HyperAI 在其官方网站上更新了多项公开资源:
- 12 篇精选公开教程
- 5 条热门 AI 百科条目
- 4 个 7 月 AI 会议截止日期
本周的主线是实践性实验。大多数条目并不只是论文介绍;它们提供了在线演示或可运行的 notebook,使用户能够快速测试模型行为。
精选公开教程
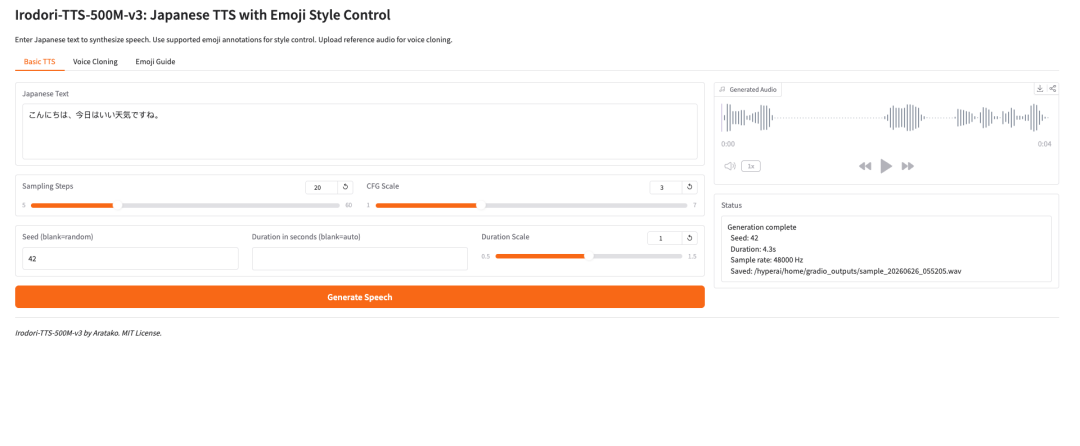
- Irodori-TTS-500M-v3:支持表情符号风格控制的日语 TTS
Irodori-TTS 是开发者 Aratako 于 2026 年发布的开源日语文本转语音项目。本次重点介绍的模型 Irodori-TTS-500M-v3 面向日语语音合成、零样本声音克隆,以及由表情符号引导的语音风格控制。
该模型基于 Rectified Flow Diffusion Transformer(RF-DiT) 架构构建,并在连续的 DACVAE 潜在空间中生成语音。在实际使用中,最有趣的一点是,它可以仅通过一段很短的参考音频克隆目标声音,通常约为 3 到 10 秒,且无需额外微调。
它还支持通过表情符号标注进行风格控制。这使得该模型比基础 TTS 系统更加灵活:用户可以用更轻量的方式引导语气、情绪、语速,以及细微的非语言表达。
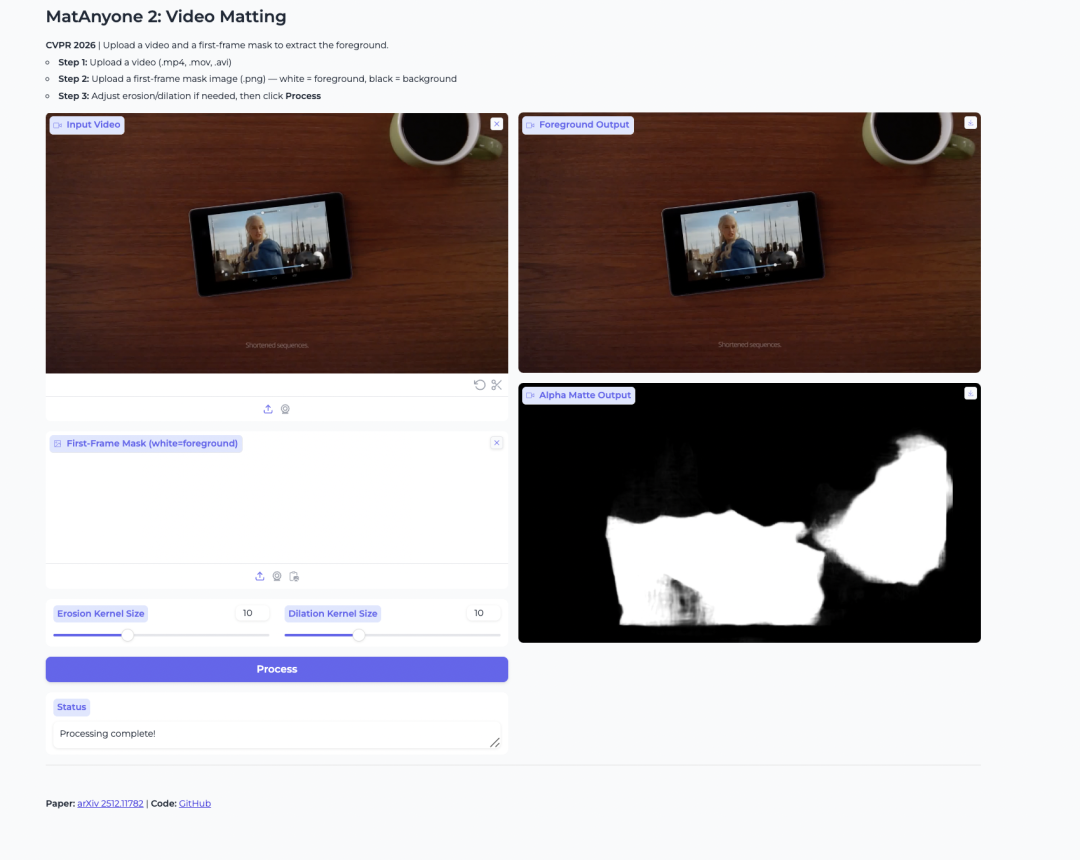
- MatAnyone 2:用于前景提取的视频抠图
MatAnyone 2 是由 NTU S-Lab 和商汤科技发布的视频抠图模型。它用于从视频中提取人物前景并生成 alpha 蒙版。
该模型通过使用学习型质量评估器来提升稳定性。这有助于减少边界伪影,并保留头发、半透明边缘和前景轮廓等细节。当用户希望在多人视频中分离特定人物时,它也很有用。
在线演示:
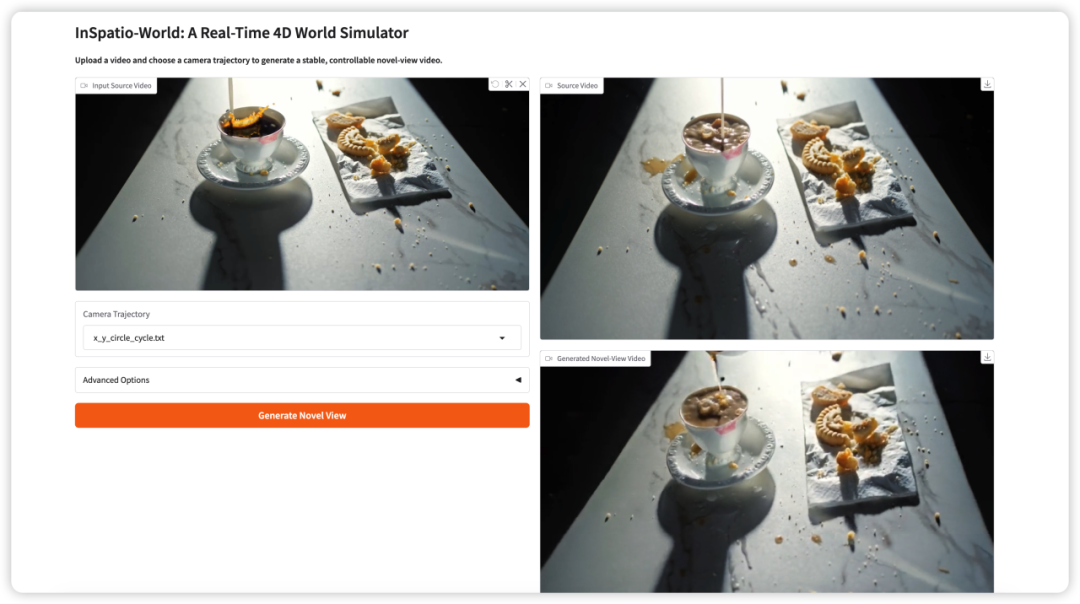
- InSpatio-World:实时 4D 世界模拟
InSpatio-World 是 InSpatio 团队于 2026 年发布的实时 4D 世界模拟器。它可以接收输入视频和指定的相机轨迹,然后生成稳定的新视角视频。
其核心思想是让视频场景更具可控性。用户无需被动观看固定相机视角,而是可以定义相机运动,并在保持时间一致性的同时,从新视角探索场景。
- DiaMoE-TTS:基于 IPA 的多方言语音合成
DiaMoE-TTS 是来自 Giant AI Lab 的多方言语音合成框架。它使用国际音标,即 IPA,作为方言语音生成的统一前端。
该模型将专家混合设计与 LoRA 和条件适配器等参数高效适配方法相结合。即使可用数据有限,这也能让系统更快适配新方言。
![图片展示了DiaMoE-TTS: Multi-Dialect Speech Synthesis的界面。]
上方介绍了基于 IPA 的 Mixture-of-Experts 设计以及 LoRA、条件适配器等参数高效适应方法。中间是“Generate Speech”按钮,下方有示例文本输入框,支持 9 种中国方言;右侧显示生成语音波形及语音参考(方言提示)。底部列出支持的方言及对应提示声音,还标注了模型使用 KPL 模型进行方言合成、生成时间等信息。该图与文档中介绍 DiaMoE-TTS 模型的内容相关,直观呈现其操作界面及功能。](https://we0-cms.oss-cn-beijing.aliyuncs.com/cms-assets/image/2026/07/094c618c-2830-4af5-9cdc-ca950fe12565-05-c0ba34b2-8a4a-4e6a-9d15-517f152cb52a.png)
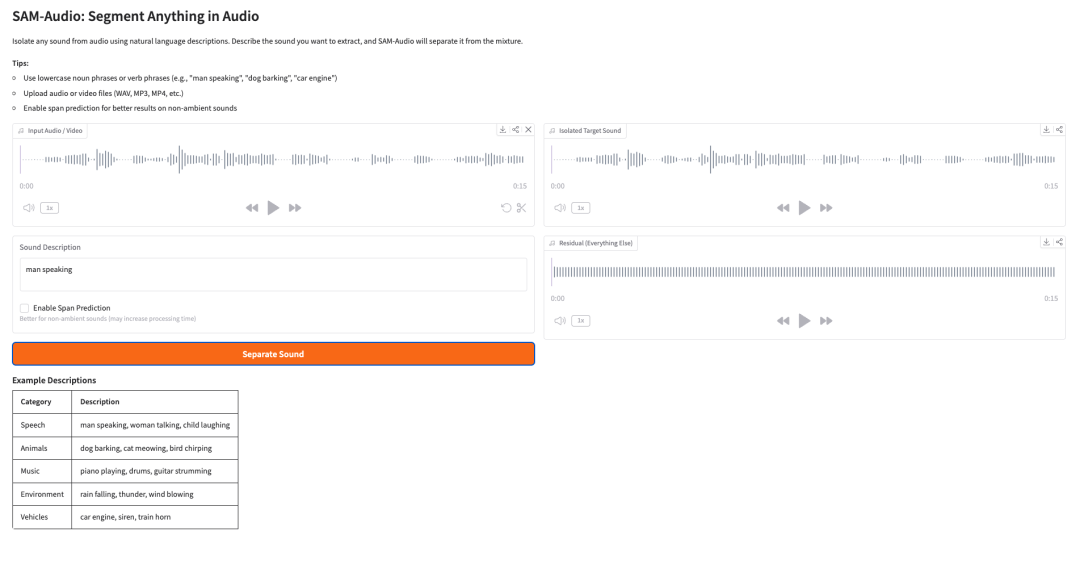
- SAM-Audio:音频中的“分割一切”
SAM-Audio 是 Meta 的音频源分离基础模型。它可以使用自然语言描述、视频中的视觉线索或选定的时间片段,从混合音频信号中分离出目标声音。
例如,用户可以描述他们想要分离的声音,如“男人说话”“狗叫”“汽车引擎”或“钢琴演奏”。随后,模型会尝试从混合音频中的其他声音里分离出目标音频。
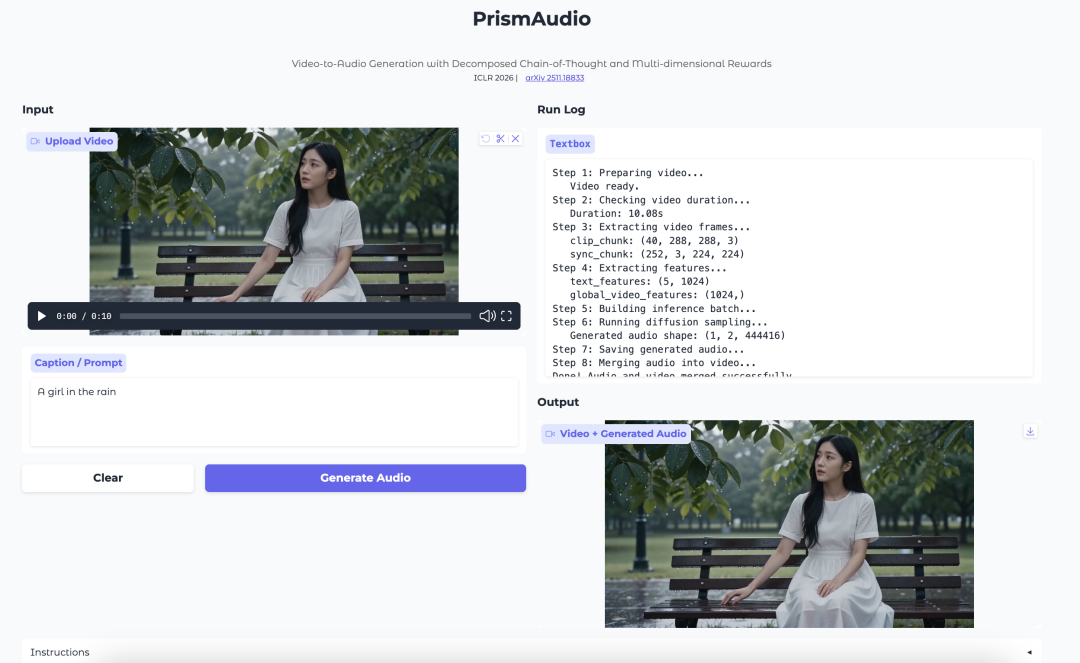
- PrismAudio:基于分解式思维链和多维奖励的视频转音频生成
PrismAudio 是通义实验室推出的视频转音频生成模型。它专注于生成与视频的视觉场景、时序、氛围和空间感相匹配的音频。
该模型引入了分解式思维链规划流程。它并不把视频转音频生成视为单一推理步骤,而是将该过程拆分为语义、时间、美学和空间等维度。每个维度都配有用于强化学习的针对性奖励信号。
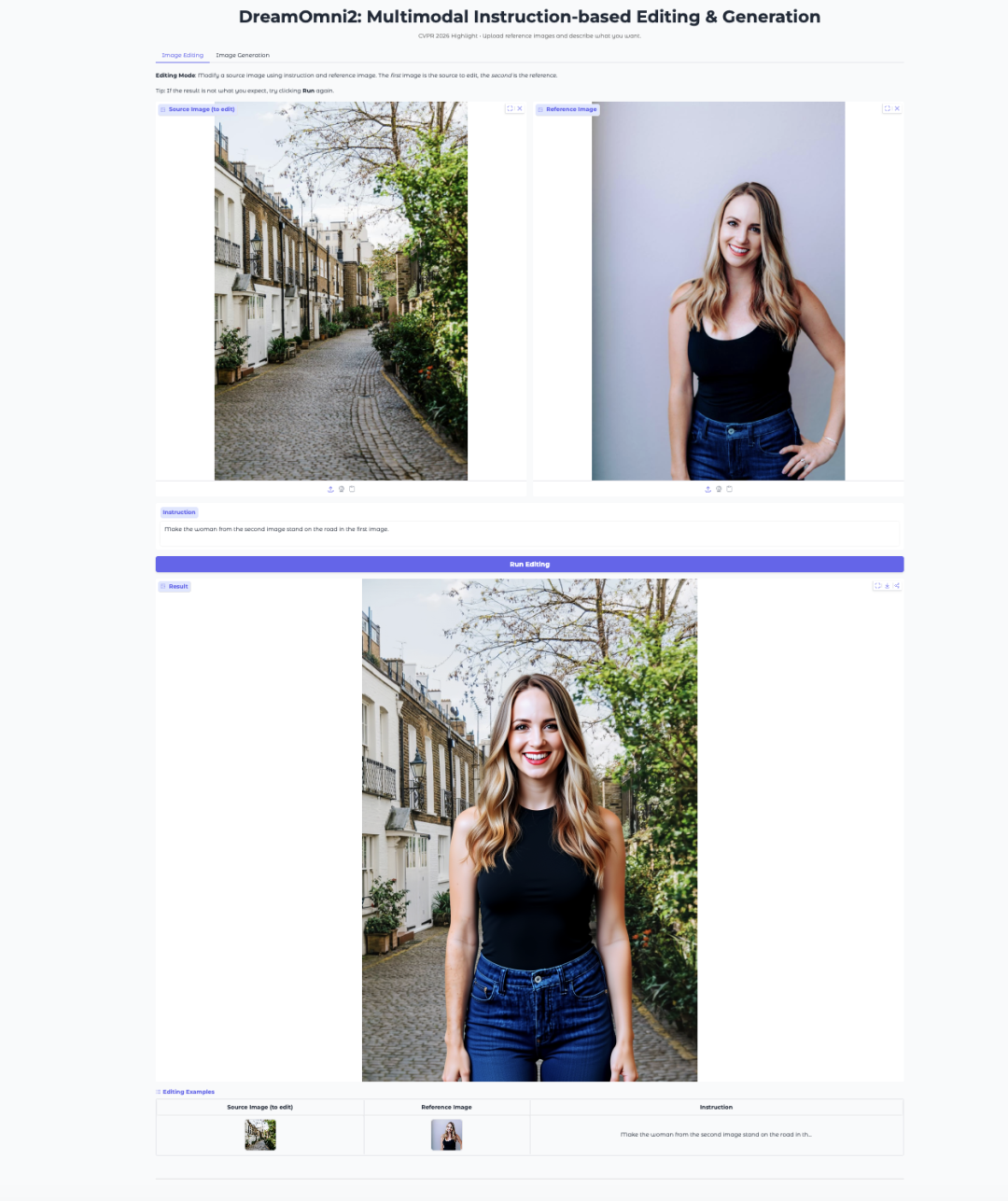
- DreamOmni2:基于多模态指令的图像编辑与生成
DreamOmni2 是香港中文大学 JIA Lab 推出的多模态图像编辑与生成模型。该模型已被 CVPR 2026 接收为 Highlight 论文。
该模型基于 FLUX.1-Kontext-dev 构建,并使用微调后的 Qwen2.5-VL-7B 视觉语言模型处理指令。它支持将自然语言提示与参考图像结合使用,因此适用于对象替换、风格迁移、姿态模仿和概念驱动生成等任务。
- PixelRefer:面向图像和视频的细粒度对象理解
PixelRefer 是阿里巴巴达摩院推出的统一图像与视频对象理解框架。它专注于细粒度的对象中心理解,而不仅仅是描述整个场景。
该框架支持区域级指向、图像描述和问答。它还引入了尺度自适应对象分词器,以及更轻量的 PixelRefer-Lite 变体,使对象表示更加紧凑高效。

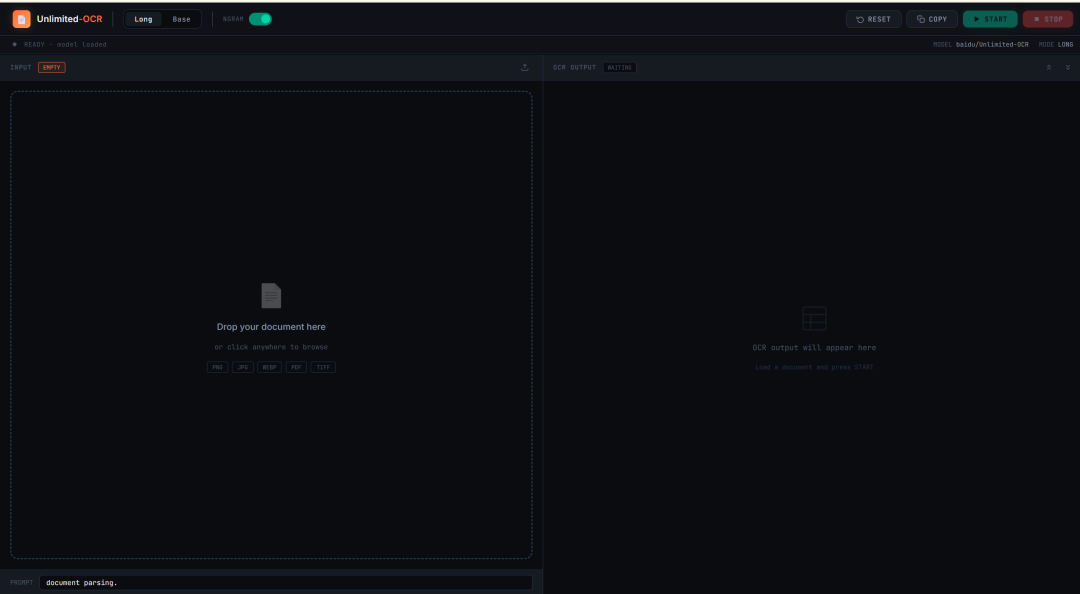
- Unlimited-OCR:一次性长文档 OCR 与版面解析
Unlimited-OCR 是百度于 2026 年发布的 OCR 与文档版面解析项目。它面向长文档解析而设计,而不仅仅是单页识别。
该项目可以处理单个文档图像、多页图像以及从 PDF 转换而来的页面。它尤其适用于论文、报告、扫描文档、长表格和多页结构化材料。
- EdgeTAM:面向边缘设备的可提示图像与视频分割
EdgeTAM 是由 Meta Reality Labs 和 NTU S-Lab 开发的端侧 Track Anything Model。它面向资源受限设备设计,同时保留了 SAM 风格模型的交互式分割能力。
该模型通过 2D Spatial Perceiver 和蒸馏流水线降低了 SAM 2 的内存注意力瓶颈。在实际应用中,这意味着它可以支持可提示的
在边缘硬件上更高效地进行分割和视频对象跟踪。

- Step-Audio-EditX:零样本语音克隆与富有表现力的音频编辑
Step-Audio-EditX 是来自 StepFun 的音频编辑模型。它将基于大语言模型的 30 亿参数音频模型与强化学习相结合,支持零样本语音克隆和富有表现力的音频编辑。
该模型可处理普通话、英语、四川话、粤语、日语和韩语。它面向情感控制、说话风格编辑、副语言编辑以及迭代式音频优化等任务而构建。

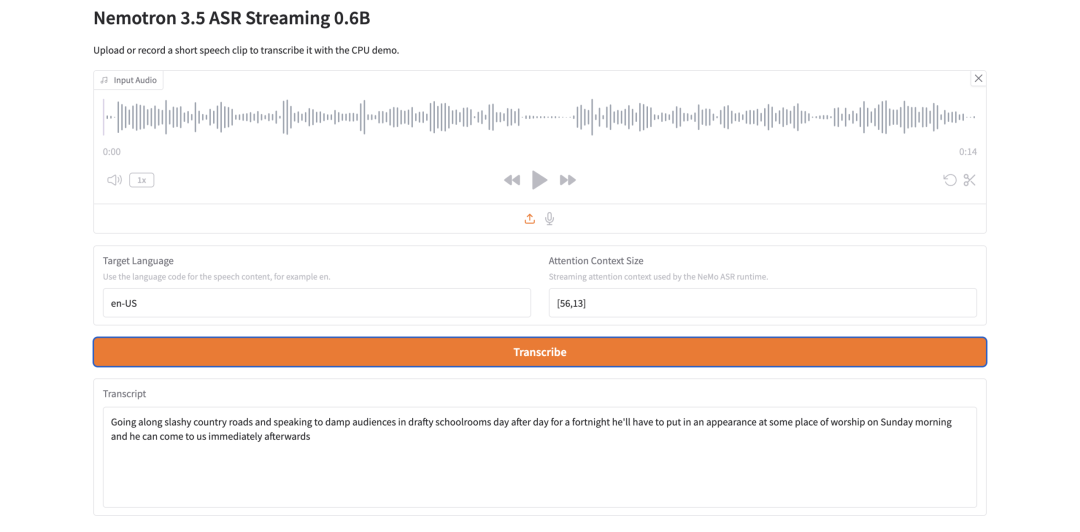
- Nemotron 3.5 ASR Streaming 0.6B:轻量级流式语音识别
Nemotron 3.5 ASR Streaming 0.6B 是来自 NVIDIA 的自动语音识别模型。它面向低延迟流式转录而构建,并采用具备缓存感知能力的 FastConformer-RNNT 架构。
其关键设计在于上下文复用。在流式推理过程中,模型会复用编码器上下文,而不是重新计算重叠的音频片段,这有助于减少冗余计算并提升实时性能。
热门百科词条
HyperAI 本周还重点介绍了五个热门 AI 百科词条:
- 大语言模型(LLM)
- 世界动作模型(WAM)
- 调和平均数
- 虚拟筛选
- 基于 AI 反馈的强化学习(RLAIF)
HyperAI 的 Wiki 收录了数百个 AI 相关概念及解释。对于希望快速理解论文、教程和模型文档中常见术语的读者来说,它非常实用。
7 月 AI 会议截止日期
原始更新还列出了 7 月若干 AI 与计算机科学会议的截止日期。所有截止时间均标注为 AoE 时间。
| 日期 | 时间 | 会议 |
|---|---|---|
| 7 月 09 日 | 23:59:59 | POPL 2027 |
| 7 月 10 日 | 23:59:59 | ICSE 2027 |
| 7 月 17 日 | 23:59:59 | SIGMOD 2027 |
| 7 月 28 日 | 23:59:59 | AAAI 2027 |
关于 HyperAI
HyperAI 是一个人工智能与高性能计算社区。其网站为开发者、研究人员和 AI 学习者提供公开资源。
根据原始来源,HyperAI 已经收集或支持:
- 2,100+ 个带有国内加速节点的公开数据集
- 700+ 门经典和热门在线教程
- 300+ 个 AI4Science 论文案例研究
- 700+ 个 AI 相关百科词条
- 完整的 Apache TVM 中文文档镜像
常见问题
什么是 Irodori-TTS-500M-v3?
Irodori-TTS-500M-v3 是一个基于 RF-DiT 架构的开源日语文本转语音模型。它支持日语语音生成、短参考音频零样本语音克隆,以及基于表情符号的风格控制。
Irodori-TTS 能否在不进行微调的情况下克隆声音?
可以。原始更新将 Irodori-TTS 描述为支持通过一段较短的参考音频片段进行零样本语音克隆,通常约为 3 到 10 秒。效果仍取决于参考音频的质量和清晰度。
SAM-Audio 用于什么?
SAM-Audio 用于基于提示的音频源分离。用户可以描述想要提取的声音、提供视觉线索,或指定时间范围,以便从混合录音中分离出目标声音。
视频抠像和视频分割有什么区别?
视频分割通常将对象划分为区域或掩码,而视频抠像会估计更精细的 Alpha 遮罩。对于干净的前景提取、头发细节、半透明边缘和合成而言,抠像尤其重要。
PrismAudio 生成什么?
PrismAudio 为视频生成音频。它会尝试让生成的声音与视频的语义内容、时间节奏、审美感受和空间线索对齐。
为什么 Unlimited-OCR 对长文档有用?
Unlimited-OCR 专为长时程解析而设计,而不仅仅是孤立的单页 OCR。在处理论文、报告、扫描文件、长表格或由多页 PDF 转换而来的图像时,它会很有用。
Nemotron 3.5 ASR Streaming 0.6B 适合实时语音转录吗?
是的,它专为低延迟设计。
流式 ASR。其具备缓存感知能力的 FastConformer-RNNT 架构会在流式推理过程中复用上下文,从而帮助减少冗余计算。
相关工具
- Irodori-TTS:开源日语 TTS,支持参考音频语音克隆和风格控制。
- Hugging Face 上的 Irodori-TTS-500M-v3:500M v3 日语 TTS 检查点的模型页面。
- SAM-Audio:Meta 的 Segment Anything in Audio 推理与示例仓库。
- MatAnyone 2:MatAnyone 2 视频抠像框架的项目页面。
- InSpatio-World:实时交互式 4D 世界模拟的项目页面。
- DiaMoE-TTS:基于 IPA 的多方言语音合成 GitHub 仓库。
- PrismAudio:基于分解式 CoT 和多维奖励的视频生成音频项目页面。
- DreamOmni2:开源多模态指令式图像编辑与生成项目。
- PixelRefer:阿里巴巴达摩院用于细粒度图像与视频对象理解的框架。
- Unlimited-OCR:百度的长时域 OCR 与文档解析项目。
- EdgeTAM:Meta 的端侧可提示图像与视频分割 Track-Anything 模型。
- Step-Audio-EditX:阶跃星辰用于零样本语音克隆和富表现力音频编辑的模型。
- Nemotron 3.5 ASR Streaming 0.6B:NVIDIA 用于低延迟流式 ASR 的 Hugging Face 模型页面。
相关链接
- BAAI Hub 原文:本期 HyperAI 周报的源文章。
- HyperAI 官方网站:HyperAI 教程、论文、数据集和 AI 资源的主入口。
- HyperAI Wiki:涵盖常见概念和研究术语的 AI 百科入口。
- HyperAI 会议追踪器:AI 与计算机科学会议截止日期追踪器。
- Meta SAM-Audio 研究页面:Segment Anything Model Audio 的官方研究页面。
- arXiv 上的 SAM-Audio 论文:介绍 SAM-Audio 基础模型的研究论文。
- arXiv 上的 MatAnyone 2 论文:关于 MatAnyone 2 及其学习式抠像质量评估器的论文。
- arXiv 上的 Unlimited-OCR 论文:Unlimited OCR 和长时域解析的技术报告。
总结
本周更新汇集了一批实用的新 AI 演示和模型资源,尤其聚焦于音频生成、语音识别、视频处理、图像理解和长文档 OCR。
最具实用性的条目包括用于日语语音生成的 Irodori-TTS、用于基于提示的声音分离的 SAM-Audio、用于干净视频抠像的 MatAnyone 2、用于长文档的 Unlimited-OCR,以及用于流式语音识别的 Nemotron 3.5 ASR。
总体而言,这份汇总适合希望快速了解哪些新 AI 模型值得测试、各自能做什么以及在哪里试用的读者。


